
多款AI搜索引用错误率高达60%,付费版本错误率更高: AI 搜索工具在美国很火,几乎四分之一的美国人都表示他们已经用 AI 来取代了传统的搜索引擎。 然而在享受便捷的同……
哈喽!伙伴们,我是小智,你们的AI向导。欢迎来到每日的AI学习时间。今天,我们将一起深入AI的奇妙世界,探索“多款AI搜索引用错误率高达60%,付费版本错误率更高”,并学会本篇文章中所讲的全部知识点。还是那句话“不必远征未知,只需唤醒你的潜能!”跟着小智的步伐,我们终将学有所成,学以致用,并发现自身的更多可能性。话不多说,现在就让我们开始这场激发潜能的AI学习之旅吧。

多款AI搜索引用错误率高达60%,付费版本错误率更高:
AI 搜索工具在美国很火,几乎四分之一的美国人都表示他们已经用 AI 来取代了传统的搜索引擎。
然而在享受便捷的同时,也潜藏着诸多问题。例如,AI 会直接引用网络上原始文章的内容,但这些内容是否符合指令要求,却是一件极为不确定的事情。
哥伦比亚大学数字新闻研究中心(Tow Center for Digital Journalism)近期就针对 AI 搜索引用内容的正确率问题展开了研究,他们分别测试了包括 ChatGPT Search、Perplexity、Perplexity Pro、Gemini、DeepSeek Search、Grok-2 Search、Grok-3 Search 和 Copilot 在内的 8 款 AI 搜索工具。
最终发现,这些 AI 搜索工具在引用新闻方面表现非常不佳,出错比例甚至高达 60%。
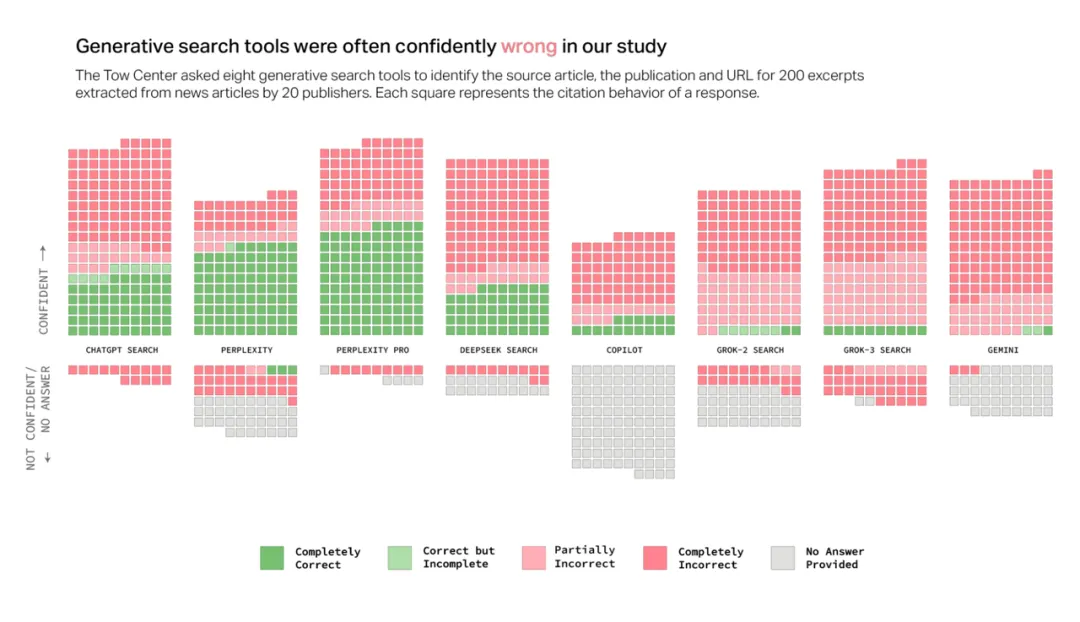
1.AI 常常自信且坚定得给出错误答案
Tow 数字新闻中心基于之前对 GPT 的研究,又对 8 款具有实时搜索功能的生成式搜索工具进行了测试,以评估它们准确检索和引用新闻内容的能力,以及它们在无法做到时的表现。
经研究发现:
• AI 搜索在无法准确回答问题时,通常不会拒绝回答,而是提供错误或推测性的答案。
• 付费 AI 搜索比免费版本更自信地提供错误答案。
• 多个 AI 搜索似乎绕过了机器人排除协议(Robot Exclusion Protocol)的设置。
• 生成式搜索工具编造链接,并引用文章的转载或复制版本。
• 与新闻来源的内容授权协议并不能保证 AI 搜索回答中的准确引用。
他们的发现与之前的研究一致,证明他们的观察不仅仅是 ChatGPT 的问题,而是他们测试的所有主流生成式搜索工具中普遍存在的现象。
除此之外,团队还公布了他们的实验方法论:
首先,他们从每家出版商中随机选择了 10 篇文章,然后手动从这些文章中选取直接摘录内容用于研究人员的查询。在向每个 AI 提供选定的摘录内容后,研究要求其识别相应文章的标题、原始出版商、发布日期和URL。

后续团队特意选择了那些如果粘贴到传统 Google 搜索中,能在前 3 条结果中返回原始来源的摘录内容,然后总共运行了 1600 次查询(20家出版商 × 10篇文章 × 8个 AI),并根据是否正确检索到文章、是否正确识别出版商、是否正确提供URL三个属性手动评估了 AI 的回答。
并且根据这些标准,将每个回答都标记为以下标签之一:
• 正确:所有三个属性均正确。
• 正确但不完整:部分属性正确,但回答缺少信息。
• 部分错误:部分属性正确,而其他属性错误。
• 完全错误:所有三个属性均错误和/或缺失。
• 未提供:未提供任何信息。
爬虫被阻止:出版商在其robots.txt文件中禁止了聊天机器人的爬虫访问。

然而最后的结果却令人大跌眼镜,实验表明,AI 搜索经常无法检索到正确的文章。它们在所有查询中提供了超过60% 的错误答案。并且不同平台的错误率还有所不同,Perplexity 的错误率为 37%,而 Grok 3 的错误率则高得多,达到了 94%,DeepSeek 的错误率则在 58% 左右。
值得一提的是,研究人员测试的 AI 都以十分自信的给出了错误答案,它们很少使用“看起来”、“可能”、“或许”这种有限定性的词语,或者通过“我无法找到确切文章”等语句承认知识空白。
例如,ChatGPT 错误识别了134篇文章,但在其 200 次回答中仅有 15 次表现出缺乏信心,但从未拒绝提供答案。除了 Copilot(它拒绝回答的问题比回答的更多)之外,所有工具都更倾向于提供错误答案,而不是承认自身的局限性。
除此之外,经过研究,团队发现付费版本的错误率竟然更高。
像 Perplexity Pro(20美元/月)或 Grok 3(40美元/月)这样的付费模型,凭借着更高的成本和他们自己声称的计算优势,被人们理所当然的认为会比免费版本更值得信赖。
然而,尽管付费的 AI 比对应的免费版本回答了更多的内容,但同时它们的错误率也更高了。这种矛盾的现象主要是因为它们宁愿提供错误的答案,也不会直接拒绝回答。
它们倾向于提供明确但错误的答案,而不是直接拒绝回答问题。付费用户期望得到更优质、准确的服务,然而这种权威的语气和错误答案,无疑给用户带来了极大的困扰。
2.爬虫乱象,出版商权益被侵犯
在本次研究中测试到的 8 款 AI 搜索工具中,ChatGPT、Perplexity 和 Perplexity Pro、Copilot 以及 Gemini 都已经公开了各自的爬虫程序名称,而 Grok 2 和 Grok 3 则尚未公开。
团队原本希望 AI 搜索应能正确查询其爬虫程序可访问的网站,并拒绝已屏蔽其内容访问权限的网站,但事实情况却并非如此。

特别是 ChatGPT、Perplexity 和 Perplexity Pro,它们时而拒绝或错误地回答允许其访问的网站,时而又正确地回答那些因爬虫受限而无法获取的信息。其中 Perplexity Pro 的表现最差,在测试的 90 篇文章中,它正确地识别出了近三分之一它没有权限访问的内容。
尽管《国家地理》已经禁止了 Perplexity 的爬虫程序,但它仍识别出了 10 篇付费文章的内容。然而值得一提的是,《国家地理》和 Perplexity 并没有合作关系,Perplexity 可能通过其他途径获取了受限内容。
这不禁让人感到怀疑,Perplexity 所谓的“尊重robots.txt指令”只是一句空谈。
同样,《Press Gazette》本月报道称,尽管《纽约时报》禁止了 Perplexity 的爬虫程序,但它依旧是 1 月被 Perplexity 引用最多的网站,访问量高达 14.6 万次。
与其他聊天机器人相比,ChatGPT 回答被禁止爬虫访问的文章相关问题的次数较少,但总体而言,它更倾向于提供错误答案而非拒绝回答。
除了以上这些,在公开了爬虫程序的 AI 搜索应用中,Copilot 是唯一一个没有被任何出版商禁止爬虫程序的,这也就意味着它可以访问查询所有的内容,但它却常常拒绝回答,拥有着最高的拒答率。

另一方面,谷歌创建了其 Google-Extended 爬虫,以便出版商可以选择阻止 Gemini 的爬虫,从而不会影响其内容在谷歌搜索中的展示。在研究人员测试的 20 家出版商中,有 10 家允许其访问,但 Gemini 只给出过一次正确答案。
除此之外,在面对政治相关的内容时,即便被允许访问,Gemini 也会选择不回答。
尽管机器人排除协议(Robot Exclusion Protocol)并不具有法律约束力,但它是一个被广泛接受的用于明确网站可爬取范围的标准,忽视它就相当于剥夺了出版商决定其内容是否被纳入搜索或用作AI模型训练数据的权利。
虽然允许网络爬虫可能会增加其内容在 AI 搜索输出中的整体可见性,但出版商可能有各种理由不希望爬虫访问其内容,比如不希望付费内容被直接看到,或是内容的主旨大意在 AI 生成的摘要中被断章取义,歪曲理解。
新闻媒体联盟主席 Danielle Coffey 在去年6月给出版商的一封信中写道:“如果无法阻止大规模的数据爬取,我们无法将有价值的内容变现,也无法支付记者的薪酬。这将对行业造成严重损害。”
3.AI 搜索经常无法链接回原始来源
AI 搜索的输出通常会引用外部来源以证明其答案的权威性,引用来源咖位越大,在人们心中信息的可信度就越强。这意味着出版商的可信度常被用来提升 AI 搜索的可信赖度。
根据路透社的报道,即使是鼓励用户从 X 获取实时更新的 Grok,引用的主要内容依旧来源于传统的新闻机构。
例如,在 BBC 新闻最近关于 AI 助手如何呈现其内容的报告中,作者写道:“当 AI 助手引用像 BBC 这样值得信赖的品牌作为来源时,受众更有可能信任答案——即使它是错误的。”
所以,当 AI 搜索出错时,它们不仅损害了自己的声誉,还损害了它们依赖以获取合法性的出版商的声誉。

然而,即使 AI 搜索正确识别了文章,也经常未能正确链接到原始来源。这就带来了两个问题:那些希望在搜索结果中获得可见性的出版商未能如愿,而那些希望退出的出版商的内容却违背其意愿仍然可见。
更多时候, AI 搜索常常引导用户去访问各大平台上的文章转载版本,而不是原始来源,即使出版商已经与 AI 公司有授权协议。例如,尽管 Perplexity Pro 与《德克萨斯论坛报》有合作关系,但在 10 次查询中,仍有 3 次引用了非官方的版本,这种倾向剥夺了原始来源潜在的推荐流量。

相反,对于那些不希望内容被爬虫程序抓取的文章来说,未经授权的副本和非官方版本更是让他们头疼不已。
例如,尽管《今日美国》已经阻止了 ChatGPT 的爬虫访问,但 GPT 仍然引用了 Yahoo News 转载的其他文章版本。
与此同时,生成式搜索工具编造 URL 的倾向也会影响用户验证信息来源的能力。例如,Grok 2 更加倾向于链接到出版机构的主页,而不是具体文章。
而 Gemini 和 Grok 3 超过一半的回答引用了编造或失效的 URL,严重影响了用户体验。在研究人员测试的200个 Grok 3 的提示中,有 154次 引用指向了错误页面。即使 Grok 正确识别了文章,但它也经常链接到一个编造的URL。虽然这个问题并非 Grok 3 和 Gemini 独有,但在其他的 AI 搜索中,这种现象出现的频率明显要低很多。
《时代》杂志的首席运营官 Mark Howard 向研究团队强调:“我们的品牌如何被呈现、在何时何地出现、以及我们如何出现和在哪里出现的透明度,以及 AI 在我们的平台上推动的参与度,都至关重要。”
尽管点击流量目前仅占出版商整体推荐流量的一小部分,但 AI 搜索工具的推荐流量在过去一年中显示出适度增长。正如《新闻公报》的 Bron Maher 所说:“ AI 搜索工具新闻发布者陷入了困境,他们呕心沥血的创作出能够在ChatGPT 等平台上展示的内容,却无法通过流量和广告获得收益。长此以往,新闻行业将会受到影响,最终导致信息质量和多样性下降。”
4.授权协议不意味着被准确引用
在研究人员测试的公司中,OpenAI 和Perplexity 对与新闻出版商建立正式关系表现出了最大的兴趣。今年 2 月,OpenAI 分别与 Schibsted 和《卫报》媒体集团达成了第 16 和第 17 项新闻内容授权协议。同样,去年 Perplexity 推出了自己的“出版商计划”,旨在“促进共同成功”,其中包括与参与出版商的收入分成安排。
AI 公司与出版商之间的协议通常涉及建立由合同协议和技术集成管理的内容管道。这些安排通常为 AI 公司提供直接访问出版商内容的权限,从而消除了网站爬取的需求。这种协议可能会让人期待,与合作伙伴出版商内容相关的用户查询会产生更准确的结果。然而,在 2025 年 2 月进行的测试中,研究人员并未观察到这一点。至少目前还没有。

他们观察到,在与合作伙伴出版商相关的查询回答中,准确性差异很大。
例如,《时代》杂志与 OpenAI 和 Perplexity 都有协议,尽管这些公司相关的模型并未 100% 准确地识别其内容,但它仍然是研究人员数据集中被识别最准确的出版商之一。
另一方面,《旧金山纪事报》允许 OpenAI 的搜索爬虫访问,并且是 Hearst 与该公司“战略内容合作伙伴关系”的一部分,但 ChatGPT 仅正确识别了研究人员分享的该出版商 10 段摘录中的 1 段。
即使在这唯一一次正确识别文章的情况下,AI 搜索工具正确命名了出版商,但未能提供 URL,这也说明这些 AI 公司并未承诺达到 100% 的准确性。
嘿,伙伴们,今天我们的AI探索之旅已经圆满结束。关于“多款AI搜索引用错误率高达60%,付费版本错误率更高”的内容已经分享给大家了。感谢你们的陪伴,希望这次旅程让你对AI能够更了解、更喜欢。谨记,精准提问是解锁AI潜能的钥匙哦!如果有小伙伴想要了解学习更多的AI知识,请关注我们的官网“AI智研社”,保证让你收获满满呦!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 















还没有评论呢,快来抢沙发~