
大模型的智能从哪里来?: 了解机器智能背后的本质也成为大众的好奇心所指。究其机器的本质在于:算法驱动、算力驱动、数据驱动。技术在模型叠加的基础上,可能会不断刷……
哈喽!伙伴们,我是小智,你们的AI向导。欢迎来到每日的AI学习时间。今天,我们将一起深入AI的奇妙世界,探索“大模型的智能从哪里来?”,并学会本篇文章中所讲的全部知识点。还是那句话“不必远征未知,只需唤醒你的潜能!”跟着小智的步伐,我们终将学有所成,学以致用,并发现自身的更多可能性。话不多说,现在就让我们开始这场激发潜能的AI学习之旅吧。

大模型的智能从哪里来?:
了解机器智能背后的本质也成为大众的好奇心所指。究其机器的本质在于:算法驱动、算力驱动、数据驱动。技术在模型叠加的基础上,可能会不断刷新人们的认知。
• ChatGPT为什么是AI里程碑?
• 涌现智能从何而来?
• DeepSeek是如何实现深度思考进行推理的?
• AGI的下一站是哪里?
1.Transformer架构
https://arxiv.org/abs/1706.03762
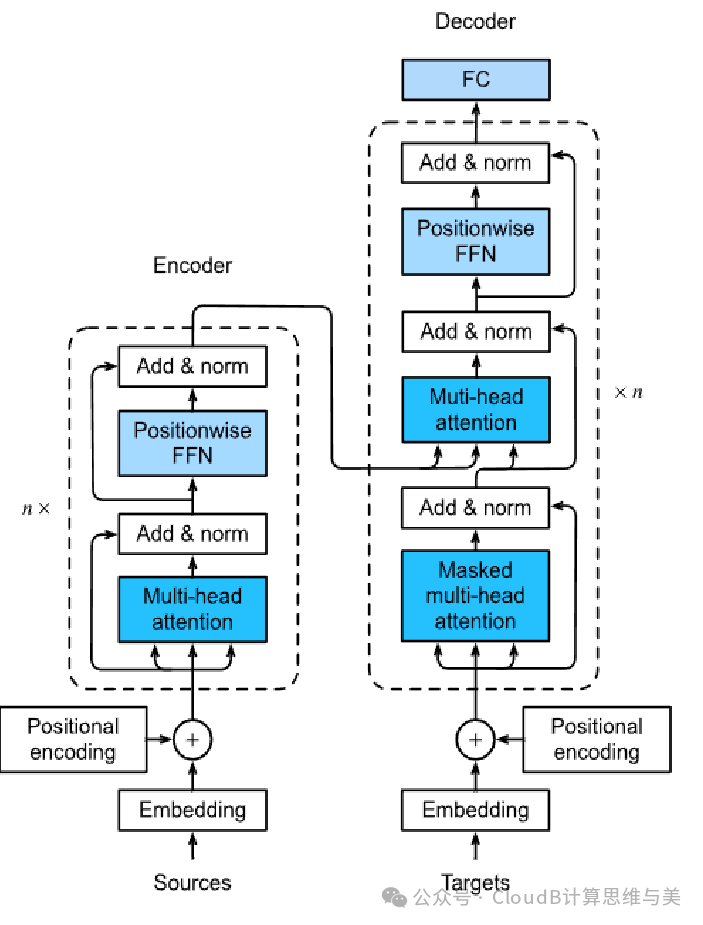
Transformer 是一种基于自注意力机制(Self-Attention)的神经网络架构,通过并行化计算和全局依赖建模,高效处理序列数据,实现信息的编码和解码,后广泛应用于自然语言处理、计算机视觉等领域。其核心特点是捕捉长距离依赖关系,支持灵活扩展,成为现代深度学习的基石。
2.“涌现”智能
https://arxiv.org/abs/2206.07682
Emergent Intelligence:当系统规模达到一定程度时,系统整体表现出一些在单个组件或小规模系统中无法观察到的复杂行为或能力。在大模型(如 ChatGPT)中,涌现智能的出现主要与以下因素有关:
(1)模型规模的扩大
• 参数量的增加:随着神经网络模型参数量的增加(从数百万到数千亿),模型的表达能力显著增强,能够捕捉更复杂的语言模式和知识。
• 规模效应:当模型规模达到一定阈值时,会突然表现出一些新的能力(如上下文学习、推理能力等),这种现象被称为“涌现”。
(2)海量数据的训练
• 多样化的数据:大模型通过训练海量的多样化数据(如书籍、网页、对话记录等),覆盖了广泛的知识领域和语言现象。
• 数据驱动的学习:模型从数据中自动提取规律,逐渐学会处理复杂的任务。
(3)自监督学习与预训练
• 自监督任务:模型通过自监督学习(如预测下一个词或掩码词)从无标注数据中学习语言的内在规律。
• 预训练目标:预训练过程中,模型学会了通用的语言表示能力,为后续的涌现能力奠定了基础。
(4)上下文学习(In-Context Learning)
• 少样本学习:模型能够在少量示例的提示下完成新任务,这种能力被称为“上下文学习”。
• 模式匹配:模型通过识别输入中的模式,推断出任务的规则并生成相应的输出。
(5)多任务学习与泛化能力
• 多任务训练:模型在训练过程中接触了多种任务(如翻译、问答、摘要等),这些任务共享通用的语言表示能力。
• 泛化能力:模型能够将学到的知识迁移到新任务中,表现出强大的泛化能力。
(6)人类反馈与对齐(Alignment)
• 人类反馈强化学习(RLHF):通过人类反馈,模型学会了生成更符合人类期望的回复。
• 对齐技术:模型被训练为更安全、更有用、更符合用户需求,这种对齐过程进一步提升了其表现。
(7)复杂任务的分解与推理
• 任务分解:模型能够将复杂任务分解为多个简单步骤,逐步解决问题。
• 推理能力:尽管模型的推理能力有限,但在某些情况下,它能够通过模式匹配和概率计算模拟出类似推理的行为。
3.Deepseek逆袭
https://github.com/deepseek-ai/DeepSeek-V3/blob/main/DeepSeek_V3.pdf
https://huggingface.co/deepseek-ai/DeepSeek-V3-Base
最近,Deepseek刷屏,以其超高的性价比、开放开源、推理性能、中文信息的理解等出圈。
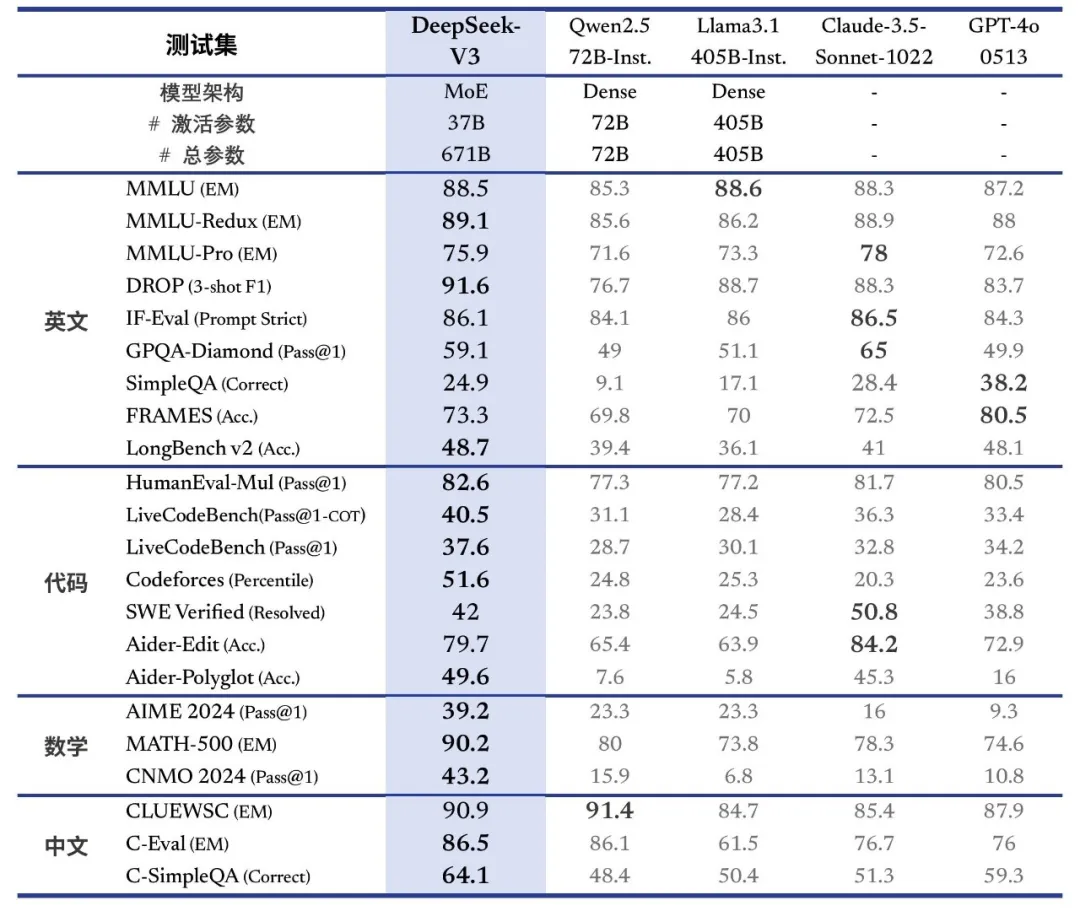
DeepSeek-R1 为例,其实现推理主要通过以下方式:
基于强化学习的训练
• 采用强化学习框架
DeepSeek-R1 使用了 GRPO 强化学习框架,以 DeepSeek-V3-Base 作为基础模型,通过强化学习来提升模型在推理任务中的性能。在强化学习过程中,模型通过与环境的交互,不断调整自身的策略,以最大化累积奖励。
• 探索纯强化学习路径
DeepSeek-R1-Zero 是 DeepSeek 首次尝试使用纯强化学习来提升语言模型推理能力的产物,重点关注模型通过纯 RL 流程实现的自我演化。它在初始阶段未依赖监督微调(SFT),在强化学习过程中自然地展现出许多强大而有趣的推理行为,如自我验证、反思以及生成长推理链等。
多阶段训练优化
• 加入冷启动数据微调
为解决 DeepSeek-R1-Zero 存在的可读性差和语言混杂等问题,进一步提升推理性能,DeepSeek-R1 在强化学习之前加入了少量冷启动数据和多阶段训练管道。首先收集数千条冷启动数据对 DeepSeek-V3-Base 模型进行微调。
• 结合监督数据再训练
在强化学习过程接近收敛时,通过在 RL 检查点上进行拒绝采样,结合DeepSeek-V3 的监督数据(包括写作、事实问答、以及自我认知等领域),生成新的 SFT 数据并重新训练模型。微调完成后,该检查点继续进行强化学习,以涵盖所有场景的 prompt,最终得到 DeepSeek-R1。
• 推理模式蒸馏
DeepSeek-R1 探索了将模型能力蒸馏到小型密集模型的可能性,以 Qwen2.5-32B 作为基础模型,直接从 DeepSeek-R1 进行蒸馏。将大型模型的推理模式蒸馏到小型模型中,使小型模型也能具备强大的推理能力,且性能优于直接在小模型上通过强化学习获得的推理模式。
DeepSeek-R1:是专注于复杂运算和逻辑推理的模型,专为数学、代码生成和逻辑推理等复杂任务设计,适用于科研、算法交易等场景。DeepSeek V3定位为通用型大语言模型,旨在处理自然语言处理、知识问答和内容生成等多种任务,适用于智能客服、内容创作等场景。
现代计算机发展,随着以深度学习为主的数据驱动的算法成为主导,逐渐从算法竞争到更多的算力和数据的竞争。热播的哪吒特效镜头超 1900 个,敖丙的 220 万片龙鳞每片都要精细渲染,单幅画面承载大量动态角色,需要高性能计算集群、专业渲染引擎与工具、云计算与弹性算力、AI 与机器学习等多方面技术提供算力支持,如大规模的 GPU 集群、结合 CPU 进行物理模拟,利用分布式计算架构分配任务,还可能采用渲染引擎及 AI 加速渲染、去噪等技术。
在大模型领域,算力和数据显得更加重要,所谓技术领先也是暂时的,在模型赋能的基础上AI可能会不断刷新人的认知,但数据驱动的智能也受限于数据,比如模型缺乏时效数据、缺乏局部领域数据等,往往就显得智力不足了。
嘿,伙伴们,今天我们的AI探索之旅已经圆满结束。关于“大模型的智能从哪里来?”的内容已经分享给大家了。感谢你们的陪伴,希望这次旅程让你对AI能够更了解、更喜欢。谨记,精准提问是解锁AI潜能的钥匙哦!如果有小伙伴想要了解学习更多的AI知识,请关注我们的官网“AI智研社”,保证让你收获满满呦!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 















还没有评论呢,快来抢沙发~