
腾讯推出新一代快思考模型混元 Turbo S:主打秒回、低成本: 2 月 27 日,腾讯混元自研的快思考模型 Turbo S 正式发布。 据悉,区别于 Deepseek R1、混元 T1 等需要“想……
哈喽!伙伴们,我是小智,你们的AI向导。欢迎来到每日的AI学习时间。今天,我们将一起深入AI的奇妙世界,探索“腾讯推出新一代快思考模型混元 Turbo S:主打秒回、低成本”,并学会本篇文章中所讲的全部知识点。还是那句话“不必远征未知,只需唤醒你的潜能!”跟着小智的步伐,我们终将学有所成,学以致用,并发现自身的更多可能性。话不多说,现在就让我们开始这场激发潜能的AI学习之旅吧。

腾讯推出新一代快思考模型混元 Turbo S:主打秒回、低成本:
2 月 27 日,腾讯混元自研的快思考模型 Turbo S 正式发布。
据悉,区别于 Deepseek R1、混元 T1 等需要“想一下再回复”的慢思考模型,混元 Turbo S 能够实现“秒回”,吐字速度提升一倍,首字时延降低 44%,另外,通过模型架构创新,Turbo S 部署成本也大幅下降,持续推动大模型应用门槛降低。
在业界通用的多个公开 Benchmark 上,腾讯混元 Turbo S 在知识、数学、推理等多个领域展现出对标 DeepSeek V3、GPT 4o、Claude3.5 等业界领先模型的效果表现。
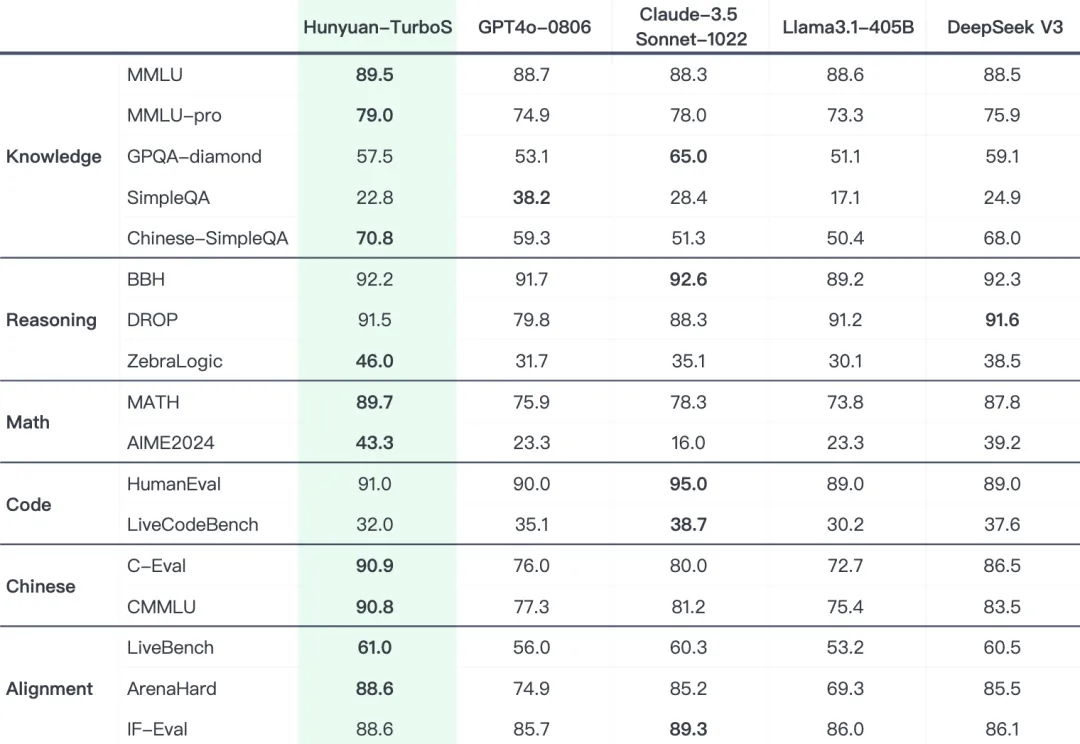
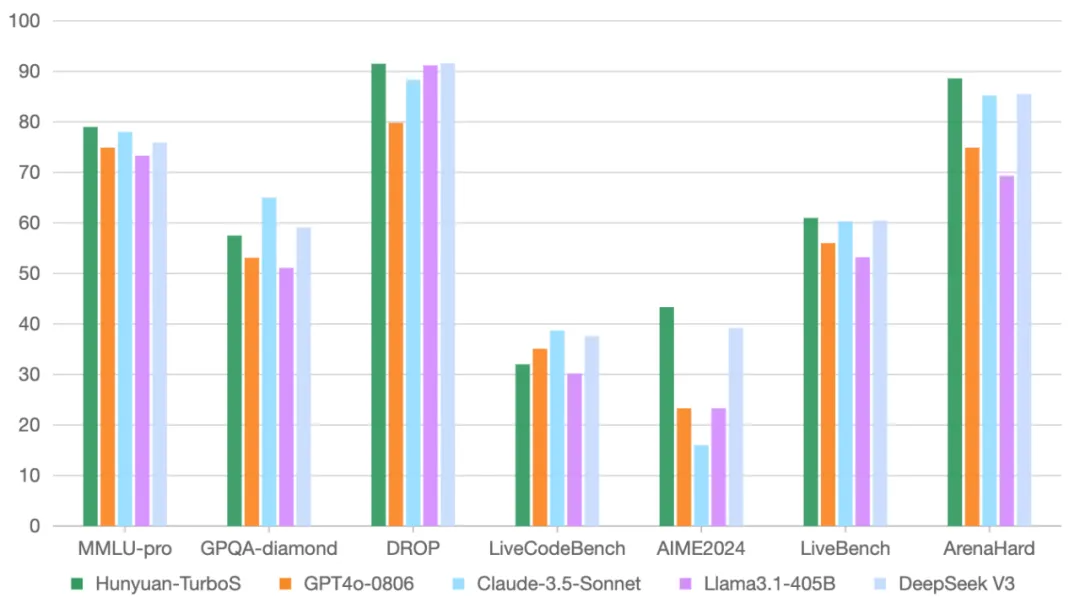
表格中,其它模型的评测指标来自官方评测结果,官方评测结果中不包含部分来自混元内部评测平台
据介绍,通过长短思维链融合,腾讯混元 Turbo S 在保持文科类问题快思考体验的同时,基于自研混元 T1 慢思考模型合成的长思维链数据,显著改进理科推理能力,实现模型整体效果提升。
架构方面,混元 Turbo S 采用了 Hybrid-Mamba-Transformer 融合模式,降低了传统 Transformer 结构的计算复杂度,减少了 KV-Cache 缓存占用,实现训练和推理成本的下降。新的融合模式也突破了传统纯 Transformer 结构大模型面临的长文训练和推理成本高的难题,一方面发挥了 Mamba 高效处理长序列的能力,也保留 Transformer 擅于捕捉复杂上下文的优势,构建了显存与计算效率双优的混合架构,这是工业界首次成功将 Mamba 架构无损地应用在超大型 MoE 模型上。
腾讯表示,作为旗舰模型,Turbo S 未来将成为腾讯混元系列衍生模型的核心基座,为推理、长文、代码等衍生模型提供基础能力。基于 Turbo S,通过引入长思维链、检索增强和强化学习等技术,腾讯自研了推理模型 T1,该模型已在腾讯元宝上线。腾讯混元表示,正式版的腾讯混元 T1 模型 API 也将很快上线,对外提供接入服务。
当前,开发者和企业用户可以在腾讯云上通过 API 调用腾讯混元 Turbo S,即日起一周内免费试用。定价上,Turbo S 输入价格为 0.8 元 / 百万 tokens,输出价格为 2 元 / 百万 tokens,相比前代混元 Turbo 模型价格下降数倍。
嘿,伙伴们,今天我们的AI探索之旅已经圆满结束。关于“腾讯推出新一代快思考模型混元 Turbo S:主打秒回、低成本”的内容已经分享给大家了。感谢你们的陪伴,希望这次旅程让你对AI能够更了解、更喜欢。谨记,精准提问是解锁AI潜能的钥匙哦!如果有小伙伴想要了解学习更多的AI知识,请关注我们的官网“AI智研社”,保证让你收获满满呦!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 















还没有评论呢,快来抢沙发~