
全网超简单Deepseek本地部署,小白也能轻松上手!: 本篇教程,小智会为大家讲解如何本地部署Deepseek大模型,来解决数据隐私问题和最近deepseek服务器繁忙问题。方法很……
哈喽!伙伴们,我是小智,你们的AI向导。欢迎来到每日的AI学习时间。今天,我们将一起深入AI的奇妙世界,探索“全网超简单Deepseek本地部署,小白也能轻松上手!”,并学会本篇文章中所讲的全部知识点。还是那句话“不必远征未知,只需唤醒你的潜能!”跟着小智的步伐,我们终将学有所成,学以致用,并发现自身的更多可能性。话不多说,现在就让我们开始这场激发潜能的AI学习之旅吧。

全网超简单Deepseek本地部署,小白也能轻松上手!:
本篇教程,小智会为大家讲解如何本地部署Deepseek大模型,来解决数据隐私问题和最近deepseek服务器繁忙问题。方法很简单,没有太高的技术难度。小白可以轻松上手!
但是,在开讲之前。我先跟大家说一说心里话,如非必要普通用户真心用不到本地部署deepseek!其他大模型也一样,除非你是企业或者个人真正需要本地部署,否则可以看看就行,不必强求。
之所以不推荐大家本地部署,道理也很简单。大模型推理时很吃硬件配置,尤其是显卡的显存、cpu、内存。一般的家用电脑显卡显存是8G的(比如4060)推荐选择7b或8b模型跑一跑,其他的就自己试水了。现阶段AI大模型的优化水平,保守估计家用本地部署也就只能跑一跑1.5b、7b、8b、14b这些。
说到这里有伙伴们会疑惑,既然8G显存电脑可以正常跑7B大模型,为什么我前面说不推荐大家这么做呢?
答疑:因为1.5b、7b、8b、14b这几个本版的deepseek大模型,自带的数据很少(数越小的版本自带数据越少),安装后ai会的知识也很有限。导致你部署的deepseek给予你的回答,比官网满血版的deepseekV3/R1,差的不是一星半点。懂得都懂!总之就是一句话,体验超差。如果说你自己要建立一个知识库,来喂给deepseek,目的是打造一个专属的小知识库AI,那倒是可以试试。
不说废话了,自己考虑需不需要吧,下面唠干货了!
第一步:下载工具
下载Ollama工具

首先,我们需要用到的是Ollama这款软件。这是一个免费开源的本地大语言模型运行平台,可以帮你把deepseek模型下载到你的电脑并运行。
下载方法及教程请看下方教程:
它即支持Windows也支持MacOS,直接在官网点击下载即可,下载后傻瓜式安装完成后,在电脑中搜索cmd,打开后输入ollama并回车,如果看到的是这样的输出,就说明你已经安装成功了。
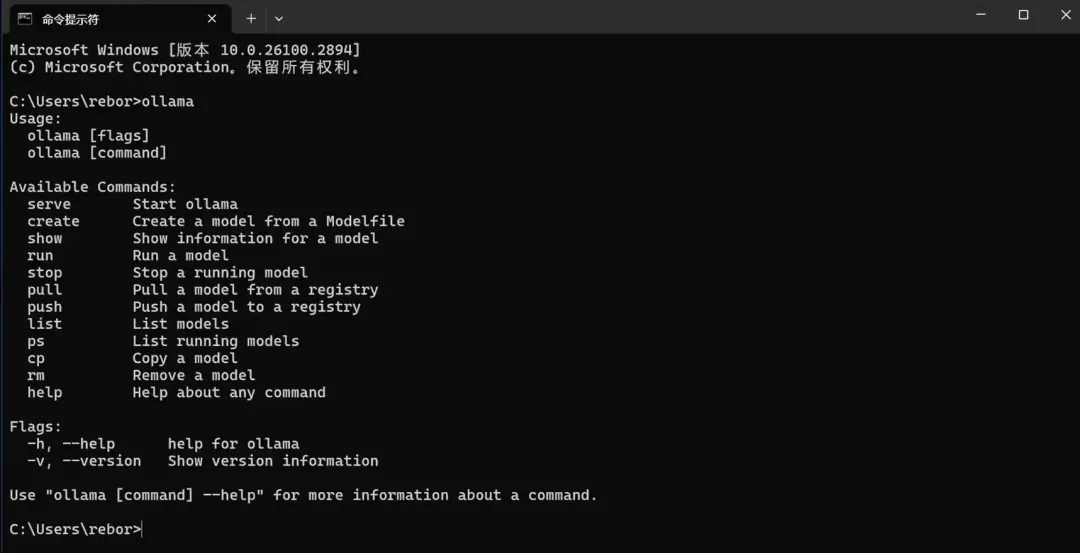
如果提示你找不到该命令,可以检查一下你系统的环境变量有没有配置Ollama的安装目录,如果已经有该配置,但还是提示你找不到该命令的话,重启一下电脑应该就可以了。
第二步:下载Deepseek模型
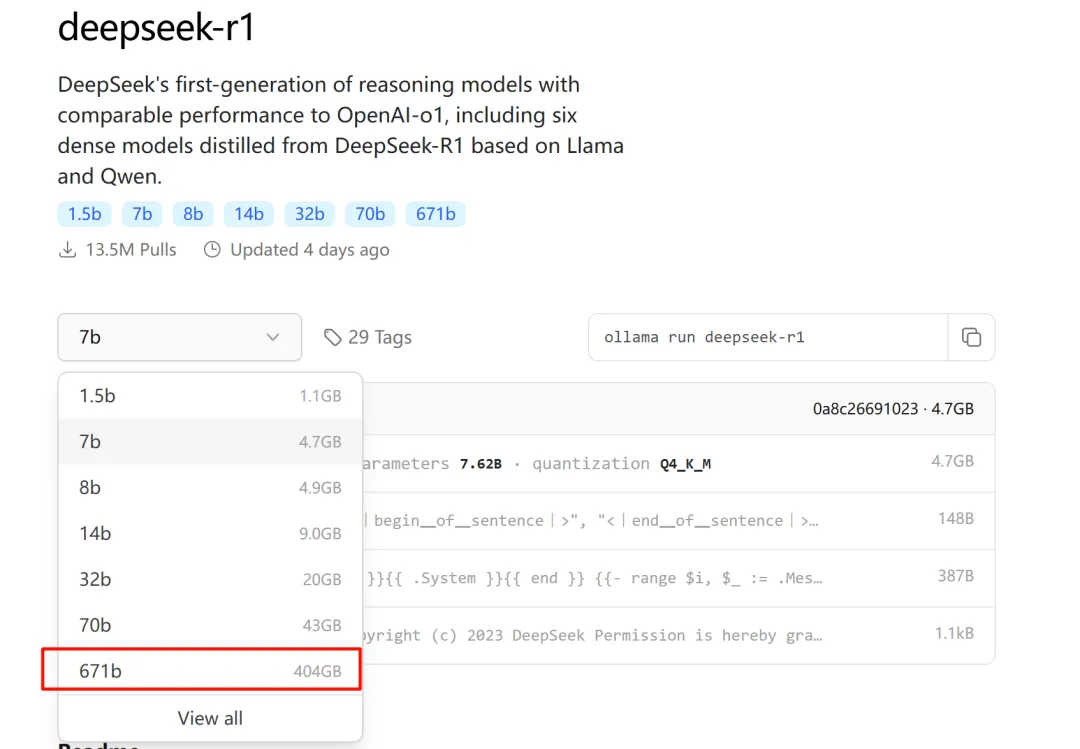
接下来我们到Ollama官网首页,点击这里的deepseek-r1,会进入到deepseek模型的下载主页,deepseek-r1目前主要有1.5b、7b、8b、14b、32b、70b、671b,这几种不同量级的开源模型。
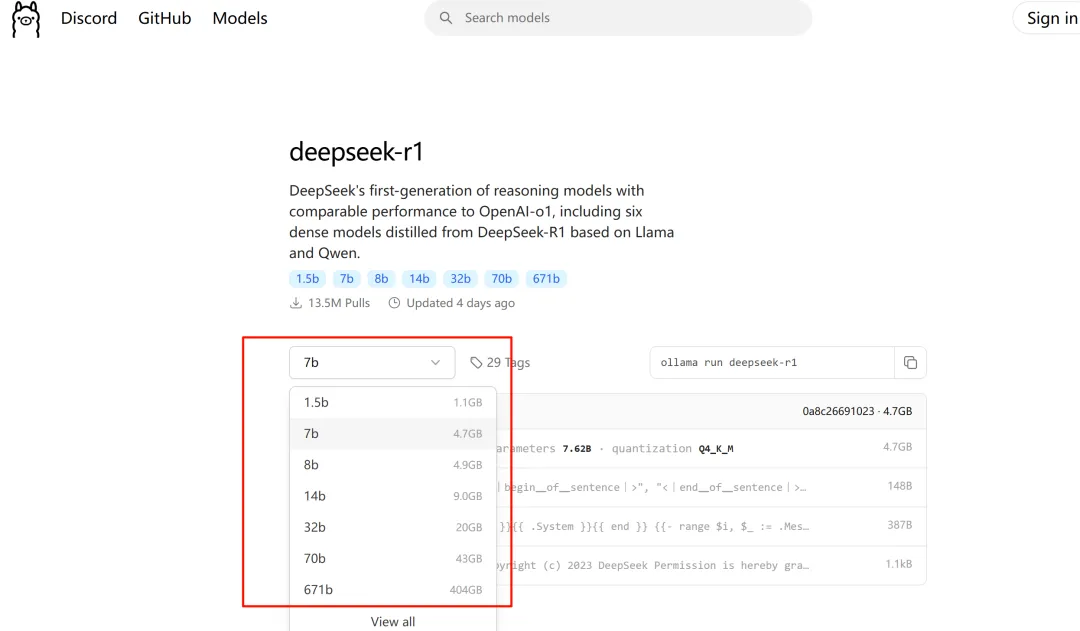
数字后面的b是英文billion,也就是十亿的首字母,整体代表的是模型的参数量,1.5b就是15亿参数,7b就是70亿参数,参数量越大意味着你得到的回答的质量也就越高。
但是参数量越大,所需要的GPU资源也就越高,如果你的电脑没有独立显卡,那么就选择1.5b版本。
如果有独立显卡,但显存是4G或8G左右的,可以选择7b或8b的版本。 确定好模型版本之后,只需要把对应命令粘贴到cmd终端回车,等待模型下载完成,然后自动运行就好了。

当你看到这个success的提示时,至此,deepseek本地版就部署好了。但现在只能在终端使用这种命令行式的方式进行对话,体验不太好。所以我们需要借助一些第三方工具,实现官网中的对话样式。

第三步:下载安装第三方工具-Cherry Studio客户端
下载地址:123网盘分享链接
官网下载:https://cherry-ai.com/download
这里推荐大家使用Cherry Studio这款工具。它是一个支持多家大模型平台的AI客户端,使用它可以直接对接ollama API,实现窗口式的大模型对话效果。
首先,到官网下载软件,安装完成后,点击左下角的设置。在模型服务中选择ollama。首先把顶部的开关打开,然后点击底部的管理按钮。
在弹出的界面中添加你刚才下载的deepseek模型。然后回到首页的对话界面,这时就可以和deepseek进行对话了。
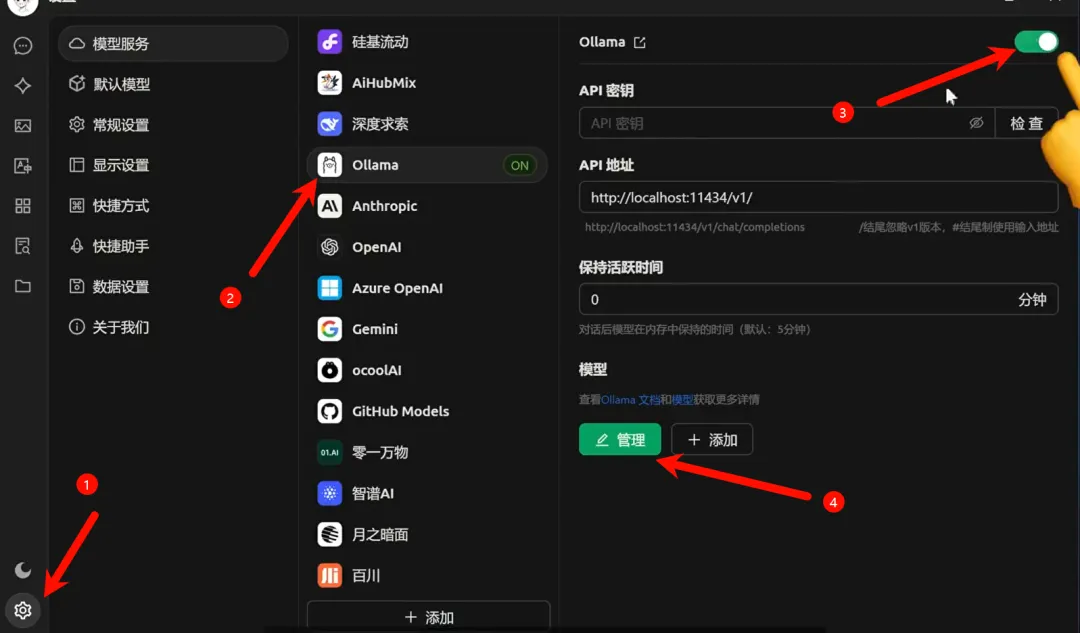
如果你安装了多个deepseek模型,也可以点击顶部进行切换。
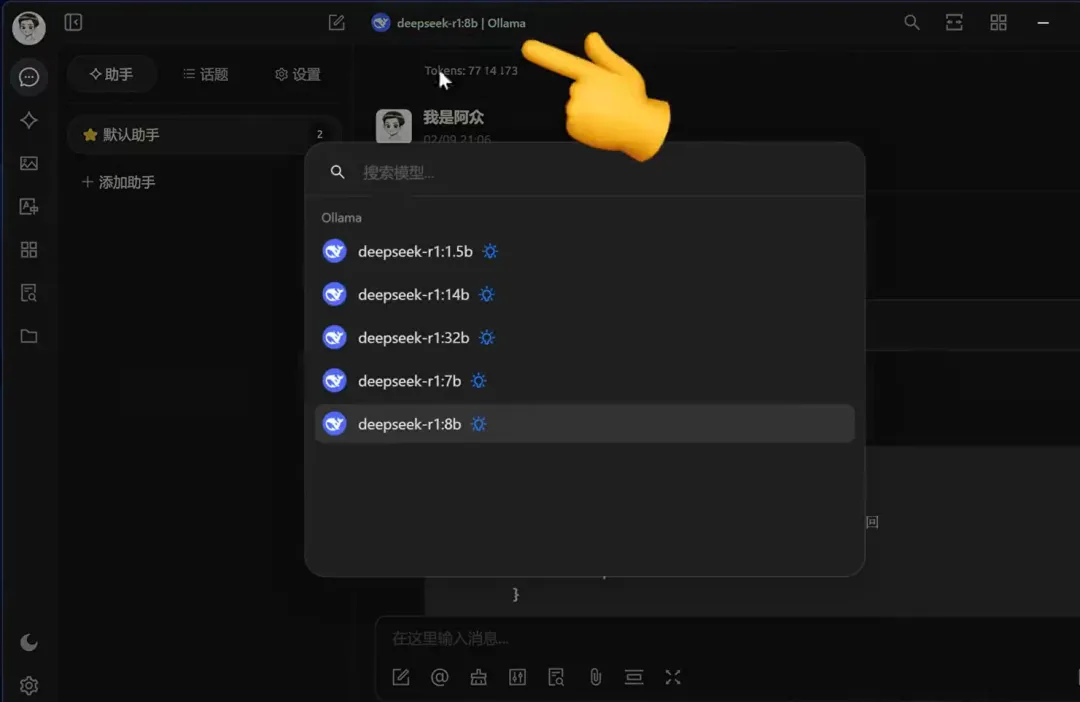
第四步:模型测试
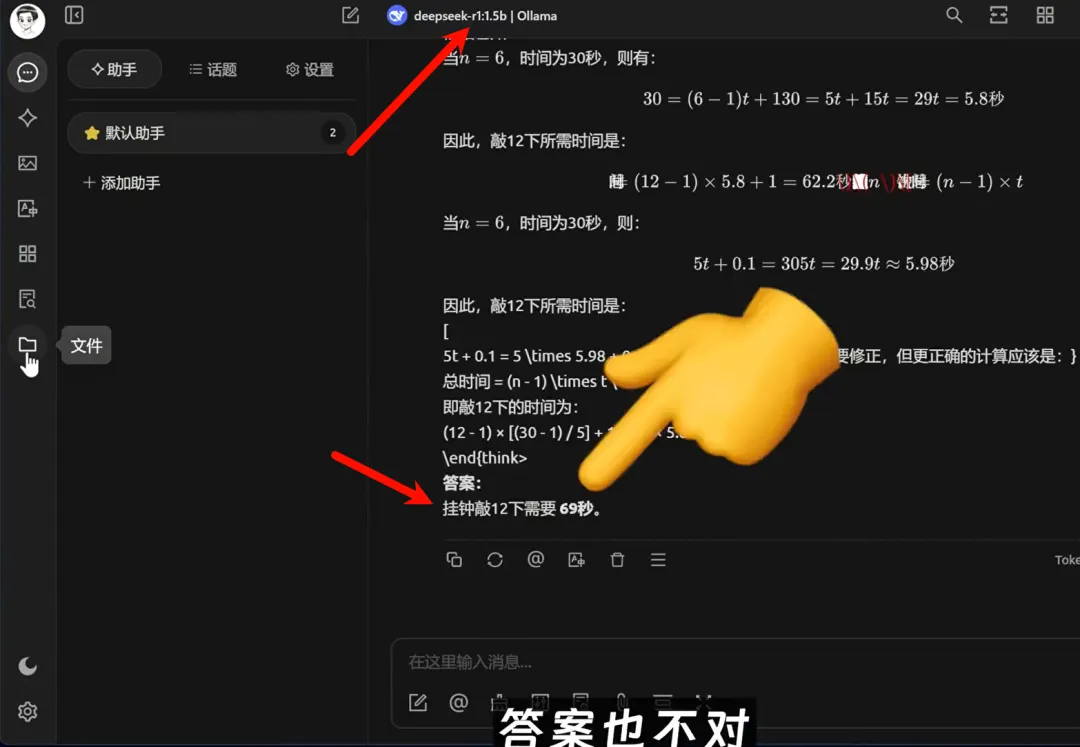
接下来,我们通过一个题目来测试一下模型回答的质量。题目很简单:一个挂钟敲六下要30秒,敲12下要几秒?正确答案是66秒。
我们首先来看一下1.5b这个模型的回答。可以看到回答速度非常快,但输出的答案很啰嗦,答案也不对。
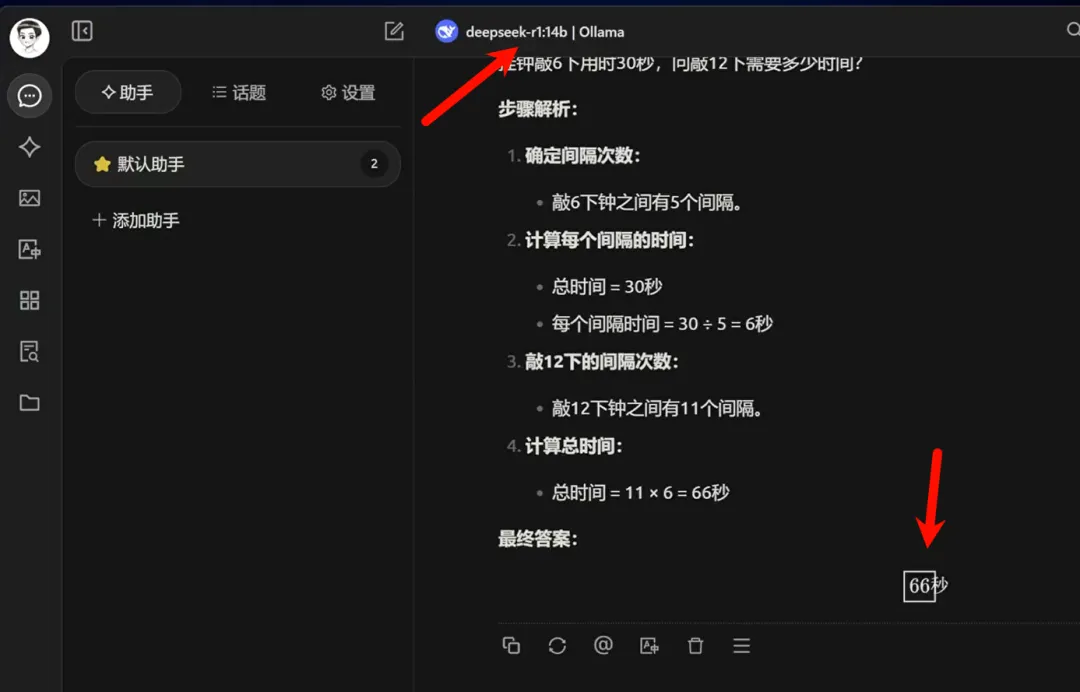
接下来再看一下14b模型的结果,回答得很简洁,且结果也是正确的。首先确定了每敲一次的时间间隔,然后计算了敲击12次总共消耗的时间。
从此我们也可以得出,参数量越多的模型,回答的质量也就越高、越准确。不过,即使你使用了700亿参数的版本,它也不是官网使用的deepseek r1,因为官网使用的是671b的纯血版deepseek。

你别看他的模型大小只有400GB,要想在本地运行该模型,你至少需要4块80G显存的A100显卡。这个成本对于个人来说基本是不可能实现的。所以,我们在本地运行这些缩小版模型的意义,更多的是折腾和体验。
不过对于个人使用来说,8b或32b的版本其实已经完全够用了,特别是在断网的情况下,它依然可以正常工作,而且不会出现服务器繁忙的情况。这一点是在线版本无法比拟的。

干货讲完啦!大家可以视频和文字教程对应学习,然后逐步去实践操作。如果遇到问题,不要着急。可以随时留言或者多问问ai啊,这时候不用它还待何时,哈哈哈!
特别鸣谢,视频UP主”我是阿众“大佬,我的教程内容也是来源于阿众老师。大家如果觉得很干,可以关注关注!
嘿,伙伴们,今天我们的AI探索之旅已经圆满结束。关于“全网超简单Deepseek本地部署,小白也能轻松上手!”的内容已经分享给大家了。感谢你们的陪伴,希望这次旅程让你对AI能够更了解、更喜欢。谨记,精准提问是解锁AI潜能的钥匙哦!如果有小伙伴想要了解学习更多的AI知识,请关注我们的官网“AI智研社”,保证让你收获满满呦!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 















还没有评论呢,快来抢沙发~