
Ai文生视频第二章之Open-Sora篇: Open-Sora 是一个完全开源的高效复现类 Sora 视频生成方案,旨在为开发者提供强大的工具支持。如果您对视频生成技术感兴趣,那么 Open……
哈喽!伙伴们,我是小智,你们的AI向导。欢迎来到每日的AI学习时间。今天,我们将一起深入AI的奇妙世界,探索“Ai文生视频第二章之Open-Sora篇”,并学会本篇文章中所讲的全部知识点。还是那句话“不必远征未知,只需唤醒你的潜能!”跟着小智的步伐,我们终将学有所成,学以致用,并发现自身的更多可能性。话不多说,现在就让我们开始这场激发潜能的AI学习之旅吧。

Ai文生视频第二章之Open-Sora篇:
Open-Sora 是一个完全开源的高效复现类 Sora 视频生成方案,旨在为开发者提供强大的工具支持。如果您对视频生成技术感兴趣,那么 Open-Sora 绝对值得一试!本文将为您详细介绍 Open-Sora 的架构、功能特性以及如何快速上手使用。
一、前言介绍
1.1 介绍一下 Open-Sora?
Open-Sora 是一个基于空间-时间注意力机制(STDiT)的视频生成模型,能够高效生成高质量的视频内容。它在性能和效率之间取得了良好的平衡,是目前开源领域中颇具竞争力的解决方案。
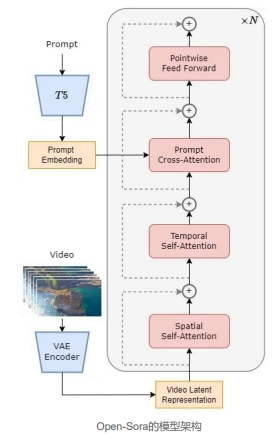
1.2 Open-Sora 的模型架构
如图所示,在 STDiT(空间-时间)架构中,每个空间注意力模块之后插入一个时间注意力模块。这一设计与 Latte 论文中的变体3相似,但在参数数量上未做严格控制。实验表明,在相同迭代次数下,性能排序为:DiT(全注意力)> STDiT(顺序执行)> STDiT(并行执行)≈ Latte。出于效率考虑,Open-Sora 本次选择了 STDiT(顺序执行)。
1.3 Open-Sora 的功能特性
– 支持多种分辨率和帧率的视频生成。
– 提供灵活的配置选项,用户可根据需求调整参数。
– 高效的推理速度和较低的硬件资源占用。
1.4 数据收集和预处理流程
高质量数据是高质量模型的关键。Open-Sora 提供了完整的数据处理工具链,包括:
1. 下载数据集。
2. 将视频分割成片段。
3. 生成视频字幕。
1.5 运行环境介绍
Open-Sora 基于 Python 3.10 和 PyTorch 构建,建议在具备 GPU 加速的环境中运行以获得最佳性能。
二、环境搭建
2.1 下载代码
首先,克隆 Open-Sora 的代码仓库:
$ git clone https://github.com/hpcaitech/Open-Sora.git
$ cd Open-Sora
2.2 构建环境
创建并激活一个新的 Python 环境:
$ conda create -n py310 python=3.10 #创建新环境
$ source activate py310 #激活环境
2.3 安装依赖
安装必要的依赖包:
$ pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple –ignore-installed
可选安装项:
– Flash Attention:
pip install packaging ninja
pip install flash-attn –no-build-isolation
– Apex:
pip install -v –disable-pip-version-check –no-cache-dir –no-build-isolation –config-settings “–build-option=–cpp_ext” –config-settings “–build-option=–cuda_ext” git+https://github.com/NVIDIA/apex.git
– Xformers:
pip install -U xformers –index-url https://download.pytorch.org/whl/cu121
2.4 Open-Sora 安装
安装 Open-Sora:
$ pip install -v .
2.5 大模型下载
进入模型目录并下载所需模型:
cd Open-Sora/opensora/models
#下载 VAE 模型
git clone https://www.modelscope.cn/AI-ModelScope/sd-vae-ft-ema.git
#下载 ST-dit 模型
git clone https://www.modelscope.cn/AI-ModelScope/Open-Sora.git
#下载 text-encoder 模型
cd text-encoder
git clone https://www.modelscope.cn/AI-ModelScope/t5-v1_1-xxl.git
三、快速实战
3.1 修改配置文件
编辑配置文件 Open-Sora/configs/opensora/inference/16x512x512.py,设置以下参数:
python:
num_frames = 16
fps = 24 // 3
image_size = (256, 256)
model = dict(
type=”STDiT-XL/2″,
space_scale=0.5,
time_scale=1.0,
enable_flashattn=True,
enable_layernorm_kernel=True,
from_pretrained=”Open-Sora/opensora/models/stdit/OpenSora-v1-HQ-16x512x512.pth”,
)
vae = dict(
type=”VideoAutoencoderKL”,
from_pretrained=”Open-Sora/opensora/models/sd-vae-ft-ema”,
)
text_encoder = dict(
type=”t5″,
from_pretrained=”Open-Sora/opensora/models/text_encoder”,
model_max_length=120,
)
scheduler = dict(
type=”iddpm”,
num_sampling_steps=100,
cfg_scale=7.0,
)
dtype = “fp16”
batch_size = 2
seed = 42
prompt_path = “./assets/texts/t2v_samples.txt”
save_dir = “./outputs/samples/”
3.2 推理
运行以下命令进行推理:
生成 16x512x512 视频
torchrun –standalone –nproc_per_node 1 scripts/inference.py configs/opensora/inference/16x512x512.py –ckpt-path OpenSora-v1-HQ-16x512x512.pth –prompt-path ./assets/texts/t2v_samples.txt
生成 16x256x256 视频
torchrun –standalone –nproc_per_node 1 scripts/inference.py configs/opensora/inference/16x256x256.py –ckpt-path OpenSora-v1-HQ-16x256x256.pth –prompt-path ./assets/texts/t2v_samples.txt
生成效果示例:
-2秒 512×512:宁静的森林夜景,捕捉从白天到夜晚的过渡。

-2秒 512×512:繁忙的城市街道,车灯和路灯交织出迷人的光影。

四、微调
4.1 数据处理
高质量数据是模型微调的关键。您可以参考以下步骤:
1. 下载数据集:/tools/datasets/README.md
2. 分割视频片段:/tools/scenedetect/README.md
3. 生成字幕:/tools/caption/README.md
4.2 训练
启动训练前,请确保已下载 T5 权重到 pretrained_models/t5_ckpts/t5-v1_1-xxl 目录中。然后运行以下命令:
#单 GPU 训练
torchrun –nnodes=1 –nproc_per_node=1 scripts/train.py configs/opensora/train/16x256x512.py –data-path YOUR_CSV_PATH#多 GPU 训练
torchrun –nnodes=1 –nproc_per_node=8 scripts/train.py configs/opensora/train/64x512x512.py –data-path YOUR_CSV_PATH –ckpt-path YOUR_PRETRAINED_CKPT
希望这篇教程能帮助您快速上手 Open-Sora!如果您有任何疑问或需要进一步的帮助。
嘿,伙伴们,今天我们的AI探索之旅已经圆满结束。关于“Ai文生视频第二章之Open-Sora篇”的内容已经分享给大家了。感谢你们的陪伴,希望这次旅程让你对AI能够更了解、更喜欢。谨记,精准提问是解锁AI潜能的钥匙哦!如果有小伙伴想要了解学习更多的AI知识,请关注我们的官网“AI智研社”,保证让你收获满满呦!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 















还没有评论呢,快来抢沙发~