
Ai文生视频第一章之Latte篇-开源文生视频DiT: 在人工智能生成内容(AiGC)领域,视频生成技术正以前所未有的速度发展。Latte 是一种基于潜在扩散 Transformer 的视频生……
哈喽!伙伴们,我是小智,你们的AI向导。欢迎来到每日的AI学习时间。今天,我们将一起深入AI的奇妙世界,探索“Ai文生视频第一章之Latte篇-开源文生视频DiT”,并学会本篇文章中所讲的全部知识点。还是那句话“不必远征未知,只需唤醒你的潜能!”跟着小智的步伐,我们终将学有所成,学以致用,并发现自身的更多可能性。话不多说,现在就让我们开始这场激发潜能的AI学习之旅吧。

Ai文生视频第一章之Latte篇-开源文生视频DiT:
在人工智能生成内容(AiGC)领域,视频生成技术正以前所未有的速度发展。Latte 是一种基于潜在扩散 Transformer 的视频生成模型,旨在通过创新的技术架构和训练方法,为用户提供高效且高质量的文生视频解决方案。本文将详细介绍 Latte 的背景、方法、环境搭建以及实战操作,帮助您快速上手这一强大的工具。
一、前言介绍
1.1 为什么提出 Latte?
随着深度学习技术的进步,视频生成任务变得越来越复杂。传统的生成模型往往在效率和质量之间难以取得平衡。Latte 的提出正是为了应对这些挑战。它通过引入 Transformer 和潜在扩散机制,实现了更高效的视频生成能力,同时显著提升了生成结果的质量。
1.2 介绍一下 Latte 方法?
Latte 的核心在于其独特的模型结构和训练细节优化。以下是对 Latte 方法的详细解析:
• Latte 整体模型结构设计探究
Latte 的模型结构采用了 Transformer 架构,并结合潜在扩散机制(Latent Diffusion),使其能够更好地捕捉视频中的时空依赖关系。这种设计不仅提升了生成质量,还显著降低了计算成本。此外,Latte 的模型结构还支持多种变体,以适应不同的应用场景。
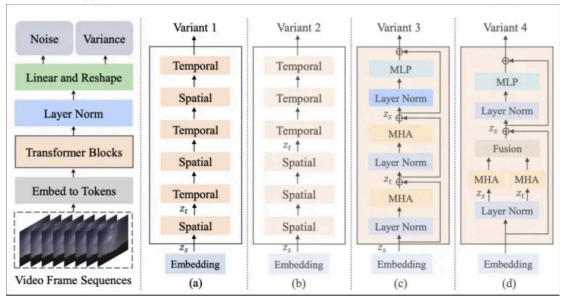
• Latte 模型与训练细节的最优设计探究(The best practices)
在训练过程中,Latte 引入了多种优化策略,例如 S-AdaLN(Scaled Adaptive Layer Normalization)和条件注入方式(Conditional Injection)。这些技术的应用进一步提升了模型的性能,使其在复杂场景下也能表现出色。
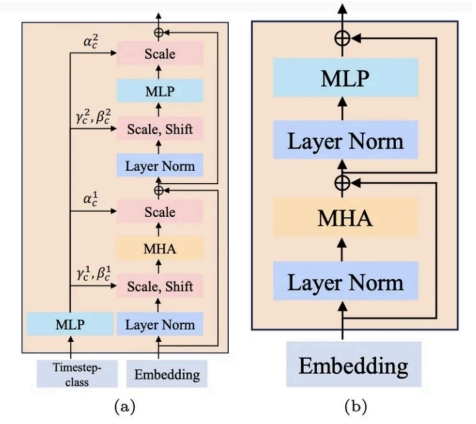
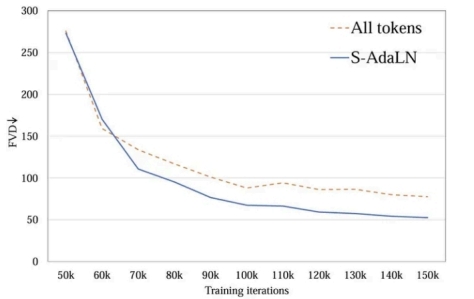
1.3 Latte 运行环境介绍
为了确保 Latte 能够顺利运行,我们需要搭建一个合适的开发环境。接下来将详细介绍如何配置 Latte 的运行环境。
二、如何搭建 Latte 环境?
2.1 下载代码
首先,从 GitHub 上克隆 Latte 的官方代码仓库:
$ git clone https://github.com/Vchitect/Latte.git
$ cd Latte
2.2 构建环境
使用 Conda 创建并激活虚拟环境:
$ conda env create -f environment.yml
$ conda activate latte
这一步非常重要,因为它确保了所有依赖项都能正确安装并兼容。
2.3 安装依赖
幸运的是,Latte 的依赖项已经包含在 environment.yml 文件中,因此无需额外安装。只需按照上述步骤完成环境构建即可。
2.4 大模型下载
Latte 的预训练模型可以通过以下两种方式下载:
方式一:使用 Hugging Face 下载
git lfs install
git clone https://huggingface.co/maxin-cn/Latte
注意:如果遇到网络问题,可以尝试使用国内镜像站点 [https://hf-mirror.com/](https://hf-mirror.com/)。
方式二:使用 ModelScope 下载
python:
from modelscope import snapshot_download
model_dir = snapshot_download(“AI-ModelScope/Latte”, cache_dir=’./’)
无论选择哪种方式,请确保下载完成后将模型路径正确配置到后续的操作中。
三、如何快速实战 Latte?
3.1 Sampling
Latte 提供了一个名为 sample.py 的脚本,用于从预训练模型中生成视频样本。你可以通过调整采样步骤和 classifier-free guidance scale 等参数来控制生成效果。
例如,从 FaceForensics 数据集生成视频:
$ bash sample/ffs.sh
注意:运行之前,请修改 configs/ffs/ffs_sample.yaml 文件中的 pretrained_model_path 选项以及 sample/ffs.sh 文件中的 –ckpt 参数。
如果需要批量生成数百个视频,可以使用 PyTorch 分布式数据并行(DDP)脚本:
$ bash sample/ffs_ddp.sh
3.2 文生视频
通过以下命令即可实现文本到视频的生成:
$ bash sample/t2v.sh
这一功能是 Latte 的一大亮点,能够让用户轻松地将文字描述转化为生动的视频内容。
四、如何训练 Latte 模型?
4.1 使用 train.py 脚本
Latte 提供了 train.py 脚本,用于训练类条件和无条件的模型。以下是如何在 FaceForensics 数据集上启动训练的具体步骤。
单机多 GPU 训练
如果您有多个 GPU 可用,可以使用 torchrun 命令来启动分布式训练:
$ torchrun –nnodes=1 –nproc_per_node=N train.py –config ./configs/ffs/ffs_train.yaml
注意:将 N 替换为您实际可用的 GPU 数量。
集群环境下的训练
如果您的计算资源基于 Slurm 集群,可以使用以下命令提交训练任务:
$ sbatch slurm_scripts/ffs.slurm
4.2 视频与图像联合训练
除了单独训练视频生成模型外,Latte 还支持视频与图像的联合训练。这可以通过 train_with_img.py 脚本来实现。
例如,在 FaceForensics 数据集上进行联合训练:
$ torchrun –nnodes=1 –nproc_per_node=N train_with_img.py –config ./configs/ffs/ffs_img_train.yaml
这种联合训练方法能够进一步提升模型对复杂场景的理解能力,从而生成更高质量的视频。
嘿,伙伴们,今天我们的AI探索之旅已经圆满结束。关于“Ai文生视频第一章之Latte篇-开源文生视频DiT”的内容已经分享给大家了。感谢你们的陪伴,希望这次旅程让你对AI能够更了解、更喜欢。谨记,精准提问是解锁AI潜能的钥匙哦!如果有小伙伴想要了解学习更多的AI知识,请关注我们的官网“AI智研社”,保证让你收获满满呦!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 















还没有评论呢,快来抢沙发~