
AI换脸入门之FaceFusion实战(四): 一、前言:FaceChain是什么?能做什么? FaceChain 是阿里巴巴达摩院推出的一款开源 AI 工具,专门用于生成高质量的个人写真和数字……
哈喽!伙伴们,我是小智,你们的AI向导。欢迎来到每日的AI学习时间。今天,我们将一起深入AI的奇妙世界,探索“AI换脸入门之FaceFusion实战(四)”,并学会本篇文章中所讲的全部知识点。还是那句话“不必远征未知,只需唤醒你的潜能!”跟着小智的步伐,我们终将学有所成,学以致用,并发现自身的更多可能性。话不多说,现在就让我们开始这场激发潜能的AI学习之旅吧。

AI换脸入门之FaceFusion实战(四):
一、前言:FaceChain是什么?能做什么?
FaceChain 是阿里巴巴达摩院推出的一款开源 AI 工具,专门用于生成高质量的个人写真和数字形象(类似于免费版的妙鸭相机)。它的核心功能是通过最少一张照片,快速生成属于你自己的个性化数字替身。无论是汉服风、工作照、芭比娃娃风,还是漫画风格,FaceChain 都能满足你的多样化需求。
FaceChain 的强大之处在于它结合了 Stable Diffusion 模型的文生图能力、LoRA 风格化训练以及人脸感知理解模型。这意味着,你可以用极少的数据生成高度逼真的个人写真,甚至还能控制生成人物的姿态和服装风格。
如果你对个性化数字形象感兴趣,那么 FaceChain 绝对值得一试!
1.FaceChain的功能特色
• 形象定制化训练:用户只需要提供至少一张个人头肩照,就可以用于LoRA风格化训练,生成具有个性化风格的数字形象。
• 生成各种风格的个人写真:FaceChain能够生成多种风格的个人写真,包括汉服风、工作照、芭比娃娃、校服风、圣诞风、绅士风、漫画风等,满足用户多样化的个性化需求。
• 支持SD WebUI插件调用:FaceChain支持通过SD WebUI插件进行调用,可以通过SD界面与AI模型进行交互,方便地生成和编辑个人形象。
• 支持姿态控制:用户可以控制生成的数字形象的姿态,为创造动态或特定动作的个人形象提供了可能。
• 自定义prompt提示词:用户可通过输入特定的提示词来改变数字形象的服装、配饰等,实现更加个性化的定制。
2.FaceChain 原理
个人写真模型的能力来源于Stable Diffusion模型的文生图功能,输入一段文本或一系列提示词,输出对应的图像。我们考虑影响个人写真生成效果的主要因素:写真风格信息,以及用户人物信息。为此,我们分别使用线下训练的风格LoRA模型和线上训练的人脸LoRA模型以学习上述信息。LoRA是一种具有较少可训练参数的微调模型,在Stable Diffusion中,可以通过对少量输入图像进行文生图训练的方式将输入图像的信息注入到LoRA模型中。因此,个人写真模型的能力分为训练与推断两个阶段,训练阶段生成用于微调Stable Diffusion模型的图像与文本标签数据,得到人脸LoRA模型;推断阶段基于人脸LoRA模型和风格LoRA模型生成个人写真图像。
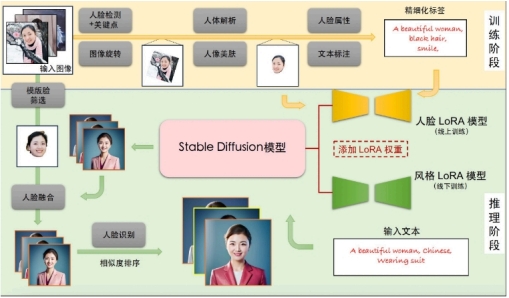
3.FaceChain 训练阶段
输入:用户上传的包含清晰人脸区域的图像
输出:人脸LoRA模型
描述:首先,我们分别使用基于朝向判断的图像旋转模型,以及基于人脸检测和关键点模型的人脸精细化旋转方法处理用户上传图像,得到包含正向人脸的图像;接下来,我们使用人体解析模型和人像美肤模型,以获得高质量的人脸训练图像;随后,我们使用人脸属性模型和文本标注模型,结合标签后处理方法,产生训练图像的精细化标签;最后,我们使用上述图像和标签数据微调Stable Diffusion模型得到人脸LoRA模型。
4.FaceChain 推断阶段
输入:训练阶段用户上传图像,预设的用于生成个人写真的输入提示词
输出:个人写真图像
描述:首先,我们将人脸LoRA模型和风格LoRA模型的权重融合到Stable Diffusion模型中;接下来,我们使用Stable Diffusion模型的文生图功能,基于预设的输入提示词初步生成个人写真图像;随后,我们使用人脸融合模型进一步改善上述写真图像的人脸细节,其中用于融合的模板人脸通过人脸质量评估模型在训练图像中挑选;最后,我们使用人脸识别模型计算生成的写真图像与模板人脸的相似度,以此对写真图像进行排序,并输出排名靠前的个人写真图像作为最终输出结果。
5.硬件环境
FaceChain是一个组合模型,基于PyTorch机器学习框架,以下是已经验证过的主要环境依赖:
• python环境: py3.8, py3.10
• pytorch版本: torch2.0.0, torch2.0.1
• CUDA版本: 11.7
• CUDNN版本: 8+
• 操作系统版本: Ubuntu 20.04, CentOS 7.9
• GPU型号: Nvidia-A10 24G
6.资源要求
• GPU: 显存占用约19G
• 磁盘: 推荐预留50GB以上的存储空间
二、FaceChain的核心功能与亮点
1. 个性化形象定制
– 只需提供至少一张清晰的头肩照,FaceChain 就能为你生成专属的数字形象。
– 支持多种风格的写真生成,比如汉服风、校服风、圣诞风、绅士风等。
2. 支持姿态控制
– 你可以指定生成人物的姿态,比如站立、坐着或特定动作,为创作动态形象提供更多可能性。
3. 自定义提示词(Prompt)
– 通过输入特定的提示词,你可以改变生成人物的服装、配饰等细节,打造完全个性化的形象。
4. 丰富的插件支持
– FaceChain 支持通过 Stable Diffusion WebUI 插件调用,方便你在熟悉的界面中生成和编辑个人形象。
5. 高效生成速度
– 在 FACT 技术的加持下,FaceChain 将生成时间从原来的几分钟缩短到仅需 10 秒左右,极大地提升了用户体验。
三、环境搭建:如何快速上手FaceChain?
1. 使用ModelScope提供的notebook环境 【重启后数据丢失】
# Step1: 我的notebook -> PAI-DSW -> GPU环境
# Step2: 进入Notebook cell,执行下述命令从github clone代码:
!GIT_LFS_SKIP_SMUDGE=1 git clone https://github.com/modelscope/facechain.git –depth 1
# Step3: 切换当前工作路径,安装依赖
import os
os.chdir(‘/mnt/workspace/facechain’) # 注意替换成上述clone后的代码文件夹主路径
print(os.getcwd())
!pip3 install gradio==3.50.2
!pip3 install controlnet_aux==0.0.6
!pip3 install python-slugify
!pip3 install onnxruntime==1.15.1
!pip3 install edge-tts
!pip3 install modelscope==1.10.0
# Step4: 启动服务,点击生成的URL即可访问web页面,上传照片开始训练和预测
!python3 app.py
2. docker镜像
如果您熟悉docker,可以使用我们提供的docker镜像,其包含了模型依赖的所有组件,无需复杂的环境安装:
# Step1: 机器资源
您可以使用本地或云端带有GPU资源的运行环境。
如需使用阿里云ECS,可访问: https://www.aliyun.com/product/ecs,推荐使用”镜像市场“中的CentOS 7.9 64
位(预装NVIDIA GPU驱动)
# Step2: 将镜像下载到本地 (前提是已经安装了docker engine并启动服务,具体可参考:
https://docs.docker.com/engine/install/)
# For China Mainland users:
docker pull registry.cn-hangzhou.aliyuncs.com/modelscope-repo/modelscope:ubuntu22.04-cuda11.8.0-
py310-torch2.1.0-tf2.14.0-1.10.0
# For users outside China Mainland:
docker pull registry.us-west-1.aliyuncs.com/modelscope-repo/modelscope:ubuntu22.04-cuda11.8.0-py310-
torch2.1.0-tf2.14.0-1.10.0
# Step3: 拉起镜像运行
docker run -it –name facechain -p 7860:7860 –gpus all registry.cn-hangzhou.aliyuncs.com/modelscoperepo/modelscope:ubuntu22.04-cuda11.8.0-py310-torch2.1.0-tf2.14.0-1.10.0 /bin/bash # 注意
your_xxx_image_id 替换成你的镜像id
# 注意: 如果提示无法使用宿主机GPU的错误,可能需要安装nvidia-container-runtime
# 1. 安装nvidia-container-runtime:https://docs.nvidia.com/datacenter/cloud-native/containertoolkit/latest/install-guide.html
# 2. 重启docker服务:sudo systemctl restart docker
# Step4: 在容器中安装gradio
pip3 install gradio==3.50.2
pip3 install controlnet_aux==0.0.6
pip3 install python-slugify
pip3 install onnxruntime==1.15.1
pip3 install edge-tts
pip3 install modelscope==1.10.0
# Step5: 获取facechain源代码
GIT_LFS_SKIP_SMUDGE=1 git clone https://github.com/modelscope/facechain.git –depth 1
cd facechain
python3 app.py
# Note: FaceChain目前支持单卡GPU,如果您的环境有多卡,请使用如下命令
# CUDA_VISIBLE_DEVICES=0 python3 app.py
# Step6: 点击 “public URL”, 形式为 https://xxx.gradio.live
3. conda虚拟环境
使用conda虚拟环境,参考Anaconda来管理您的依赖,安装完成后,执行如下命令: (提示: mmcv对环境要求较高,可能出现不适配的情况,推荐使用docker方式)
conda create -n facechain python=3.8 # 已验证环境:3.8 和 3.10
conda activate facechain
GIT_LFS_SKIP_SMUDGE=1 git clone https://github.com/modelscope/facechain.git –depth 1
cd facechain
pip3 install -r requirements.txt
pip3 install -U openmim
# 参考mmcv官方文档 https://mmcv.readthedocs.io/en/latest/get_started/installation.html
mim install mmcv-full==1.7.2
# 进入facechain文件夹,执行:
python3 app.py
# Note: FaceChain目前支持单卡GPU,如果您的环境有多卡,请使用如下命令
# CUDA_VISIBLE_DEVICES=0 python3 app.py
# 最后点击log中生成的URL即可访问页面。
4. colab运行
点击:https://colab.research.google.com/github/modelscope/facechain/blob/main/facechain_demo.ipyn
5. stable-diffusion-webui中运行
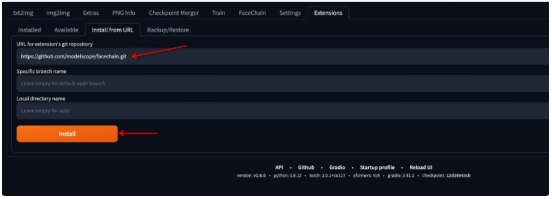
1. 选择Extensions Tab, 选择Install From URL(官方插件集成中,先从URL安装)
2. 切换到Installed,勾选FaceChain插件,点击Apply and restart UI
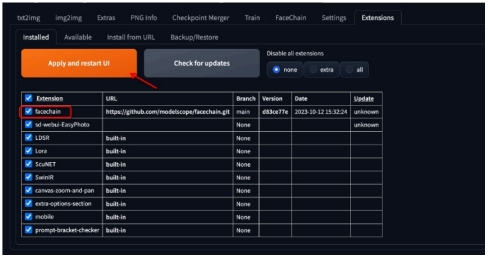
3. 页面刷新后,出现FaceChain Tab说明安装成功
注:app服务成功启动后,在log中访问页面URL,进入”形象定制“tab页,点击“选择图片上传”,并最少选1张包含人脸的图片;点击“开始训练”即可训练模型。训练完成后日志中会有对应展示,之后切换到“形象体验”标签页点击“开始生成”即可生成属于自己的数字形象。
6. 效果
运行
python app.py
启动后进入http://127.0.0.1:7860
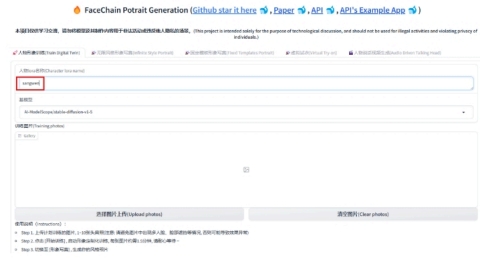
1. 填写“人物Lora名称”(例如sangwen),不要使用缺省的person1等参数,便于后续区分。
2. 点击“选择图片上传”,可以一次多选多张图片上传,但是一定要耐心等到全部图片上传完成再执行下一步操作。
(等待时间视上传图片总大小而定,这个操作还是比较快的)
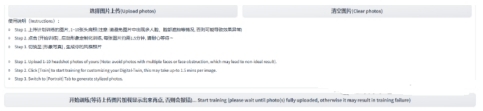
3. 点击“开始训练”,等待训练完成(系统会有提示)。在训练过程中,如果有照片不适用于训练(比如出现多个人脸),系统会有提示。
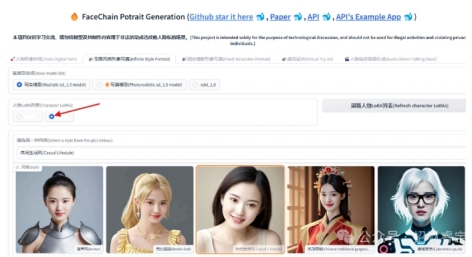
4. 训练完成后我们试一下“无限风格形象写真”,点击这个选项,选择写实模型。注意一定要点选某个训练生成的人物LoRA,系统不会自动选择的。
选择一种风格(这里选择“休闲生活风”)
在页面的下方,我们看一下“高级选项”,暂时不做修改。
在生成图片数量栏位,可以设定希望一次生成的图片数量。然后点击“开始生成”。
四、Inference
如果不想启动服务,而是直接在命令行进行开发调试等工作,FaceChain也支持在python环境中直接运行脚本进行训练和推理。在克隆后的文件夹中直接运行如下命令来进行训练:
PYTHONPATH=. sh train_lora.sh “ly261666/cv_portrait_model” “v2.0” “film/film” “./imgs” “./processed” “./output”
参数含义:
ly261666/cv_portrait_model: ModelScope模型仓库的stable diffusion基模型,该模型会用于训练,可以不修改
v2.0: 该基模型的版本号,可以不修改
film/film: 该基模型包含了多个不同风格的子目录,其中使用了film/film目录中的风格模型,可以不修改
./imgs: 本参数需要用实际值替换,本参数是一个本地文件目录,包含了用来训练和生成的原始照片
./processed: 预处理之后的图片文件夹,这个参数需要在推理中被传入相同的值,可以不修改
./output: 训练生成保存模型weights的文件夹,可以不修改
等待5-20分钟即可训练完成。用户也可以调节其他训练超参数,训练支持的超参数可以查看train_lora.sh的配置,或者facechain/train_text_to_image_lora.py中的完整超参数列表。
进行推理时,请编辑run_inference.py中的代码:
# 使用深度控制,默认False,仅在使用姿态控制时生效
use_depth_control = False
# 使用姿态控制,默认False
use_pose_model = False
# 姿态控制图片路径,仅在使用姿态控制时生效
pose_image = ‘poses/man/pose1.png’
# 填入上述的预处理之后的图片文件夹,需要和训练时相同
processed_dir = ‘./processed’
# 推理生成的图片数量
num_generate = 5
# 训练时使用的stable diffusion基模型,可以不修改
base_model = ‘ly261666/cv_portrait_model’
# 该基模型的版本号,可以不修改
revision = ‘v2.0’
# 该基模型包含了多个不同风格的子目录,其中使用了film/film目录中的风格模型,可以不修改
base_model_sub_dir = ‘film/film’
# 训练生成保存模型weights的文件夹,需要保证和训练时相同
train_output_dir = ‘./output’
# 指定一个保存生成的图片的文件夹,本参数可以根据需要修改
output_dir = ‘./generated’
# 使用凤冠霞帔风格模型,默认False
use_style = False
执行:
$ python run_inference.py
即可在output_dir中找到生成的个人数字形象照片。
五、效果展示
在FACT的加持下,FaceChain的人像生成体验又有了质的飞跃。
1. 在生成速度方面,FaceChain-FACT成功摆脱了冗长繁琐的训练阶段,将定制人像的生成时间大幅缩短了百倍。现在,整个生成过程仅需10s左右,为用户带来了无比流畅的使用体验。
2. 在生成效果方面,FaceChain-FACT成功提升了人脸的细腻程度,使其更加逼近真实的人像效果。通过高度保留的人脸细节信息,确保了生成写真效果既惊艳又自然。FaceChain海量的精美风格模版,又为生成的人像注入了艺术生命力。


FaceChain-FACT的诞生,将为用户开启前所未有的高质量AI写真体验。除了在生成速度与质量上的显著提升,FaceChain还提供丰富的API接口,让开发者可以根据自己的需求进行定制化开发。无论是想要创建自己的AI写真应
用,还是在现有项目中集成FaceChain的功能,都可以轻松实现。
FaceChain 是一款功能强大且易于使用的 AI 工具,无论是制作个性化写真,还是开发创意内容,它都能为你带来惊艳的效果。不过需要注意的是,AI 技术的应用需遵守法律法规,避免不当使用带来的风险。
希望这篇教程能帮助你顺利上手 FaceChain!如果有任何问题,欢迎随时交流讨论。
嘿,伙伴们,今天我们的AI探索之旅已经圆满结束。关于“AI换脸入门之FaceFusion实战(四)”的内容已经分享给大家了。感谢你们的陪伴,希望这次旅程让你对AI能够更了解、更喜欢。谨记,精准提问是解锁AI潜能的钥匙哦!如果有小伙伴想要了解学习更多的AI知识,请关注我们的官网“AI智研社”,保证让你收获满满呦!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 















还没有评论呢,快来抢沙发~