
面向开发者的LLM入门教程-问答加载向量数据库: 问答 Langchain 在实现与外部数据对话的功能时需要经历下面的5个阶段,它们分别是:Document Loading->Splitting->Stora……
哈喽!伙伴们,我是小智,你们的AI向导。欢迎来到每日的AI学习时间。今天,我们将一起深入AI的奇妙世界,探索“面向开发者的LLM入门教程-问答加载向量数据库”,并学会本篇文章中所讲的全部知识点。还是那句话“不必远征未知,只需唤醒你的潜能!”跟着小智的步伐,我们终将学有所成,学以致用,并发现自身的更多可能性。话不多说,现在就让我们开始这场激发潜能的AI学习之旅吧。

面向开发者的LLM入门教程-问答加载向量数据库:
问答
Langchain 在实现与外部数据对话的功能时需要经历下面的5个阶段,它们分别是:Document Loading->Splitting->Storage->Retrieval->Output,如下图所示:
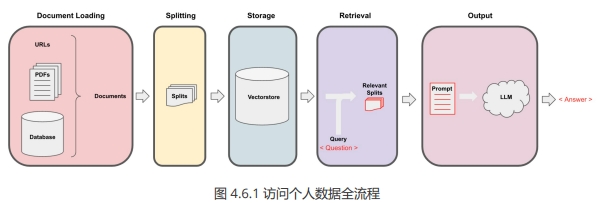
我们已经完成了整个存储和获取,获取了相关的切分文档之后,现在我们需要将它们传递给语言模型,以获得答案。这个过程的一般流程如下:首先问题被提出,然后我们查找相关的文档,接着将这些切分文档和系统提示一起传递给语言模型,并获得答案。
默认情况下,我们将所有的文档切片都传递到同一个上下文窗口中,即同一次语言模型调用中。然而,有一些不同的方法可以解决这个问题,它们都有优缺点。大部分优点来自于有时可能会有很多文档,但你简单地无法将它们全部传递到同一个上下文窗口中。MapReduce、Refine 和 MapRerank 是三种方法,用于解决这个短上下文窗口的问题。我们将在该课程中进行简要介绍。
在上一章,我们已经讨论了如何检索与给定问题相关的文档。下一步是获取这些文档,拿到原始问题,将它们一起传递给语言模型,并要求它回答这个问题。在本节中,我们将详细介绍这一过程,以及完成这项任务的几种不同方法。
在2023年9月2日之后,GPT-3.5 API 会进行更新,因此此处需要进行一个时间判断
import datetime
current_date = datetime.datetime.now().date()
if current_date < datetime.date(2023, 9, 2): llm_name = "gpt-3.5-turbo-0301" else: llm_name = "gpt-3.5-turbo" print(llm_name)
gpt-3.5-turbo-0301
加载向量数据库
首先我们加载之前已经进行持久化的向量数据库:
from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings
persist_directory = ‘docs/chroma/matplotlib/’
embedding = OpenAIEmbeddings()
vectordb = Chroma(persist_directory=persist_directory,
embedding_function=embedding)print(vectordb._collection.count())
27
我们可以测试一下对于一个提问进行向量检索。如下代码会在向量数据库中根据相似性进行检索,返回给你 k 个文档。
question = “这节课的主要话题是什么”
docs = vectordb.similarity_search(question,k=3)
len(docs)
3
嘿,伙伴们,今天我们的AI探索之旅已经圆满结束。关于“面向开发者的LLM入门教程-问答加载向量数据库”的内容已经分享给大家了。感谢你们的陪伴,希望这次旅程让你对AI能够更了解、更喜欢。谨记,精准提问是解锁AI潜能的钥匙哦!如果有小伙伴想要了解学习更多的AI知识,请关注我们的官网“AI智研社”,保证让你收获满满呦!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 















还没有评论呢,快来抢沙发~