
面向开发者的LLM入门教程-向量数据库与词向量(1): 向量数据库与词向量(Vectorstoresand Embeddings) 让我们一起回顾一下检索增强生成(RAG)的整体工作流程: 前两节……
哈喽!伙伴们,我是小智,你们的AI向导。欢迎来到每日的AI学习时间。今天,我们将一起深入AI的奇妙世界,探索“面向开发者的LLM入门教程-向量数据库与词向量(1)”,并学会本篇文章中所讲的全部知识点。还是那句话“不必远征未知,只需唤醒你的潜能!”跟着小智的步伐,我们终将学有所成,学以致用,并发现自身的更多可能性。话不多说,现在就让我们开始这场激发潜能的AI学习之旅吧。

面向开发者的LLM入门教程-向量数据库与词向量(1):
向量数据库与词向量(Vectorstoresand Embeddings)
让我们一起回顾一下检索增强生成(RAG)的整体工作流程:
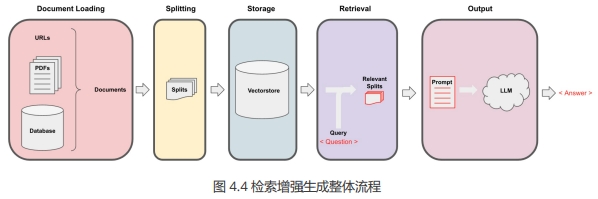
前两节课我们讨论了 Document Loading (文档加载)和 Splitting (分割)。
下面我们将使用前两节课的知识对文档进行加载分割。
读取文档
下面文档是 datawhale 官方开源的 matplotlib 教程链接 https://datawhalechina.github.io/fantastic-matplotlib/index.html ,可在该网站上下载对应的教程。
注意,本章节需要安装第三方库 pypdf 、 chromadb
from langchain.document_loaders import PyPDFLoader
# 加载 PDF
loaders_chinese = [
# 故意添加重复文档,使数据混乱
PyPDFLoader(“docs/matplotlib/第一回:Matplotlib初相识.pdf”),
PyPDFLoader(“docs/matplotlib/第一回:Matplotlib初相识.pdf”),
PyPDFLoader(“docs/matplotlib/第二回:艺术画笔见乾坤.pdf”),
PyPDFLoader(“docs/matplotlib/第三回:布局格式定方圆.pdf”)
]
docs = []
for loader in loaders_chinese:
docs.extend(loader.load())
在文档加载后,我们可以使用 RecursiveCharacterTextSplitter (递归字符文本拆分器)来创建块。
# 分割文本
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 1500, # 每个文本块的大小。这意味着每次切分文本时,会尽量使每个块包含 1500
个字符。
chunk_overlap = 150 # 每个文本块之间的重叠部分。
)
splits = text_splitter.split_documents(docs)
print(len(splits))
27
嘿,伙伴们,今天我们的AI探索之旅已经圆满结束。关于“面向开发者的LLM入门教程-向量数据库与词向量(1)”的内容已经分享给大家了。感谢你们的陪伴,希望这次旅程让你对AI能够更了解、更喜欢。谨记,精准提问是解锁AI潜能的钥匙哦!如果有小伙伴想要了解学习更多的AI知识,请关注我们的官网“AI智研社”,保证让你收获满满呦!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 















还没有评论呢,快来抢沙发~