
面向开发者的LLM入门教程-为什么要进行文档分割: 为什么要进行文档分割 1. 模型大小和内存限制:GPT 模型,特别是大型版本如 GPT-3 或 GPT-4 ,具有数十亿甚至上百亿的……
哈喽!伙伴们,我是小智,你们的AI向导。欢迎来到每日的AI学习时间。今天,我们将一起深入AI的奇妙世界,探索“面向开发者的LLM入门教程-为什么要进行文档分割”,并学会本篇文章中所讲的全部知识点。还是那句话“不必远征未知,只需唤醒你的潜能!”跟着小智的步伐,我们终将学有所成,学以致用,并发现自身的更多可能性。话不多说,现在就让我们开始这场激发潜能的AI学习之旅吧。

面向开发者的LLM入门教程-为什么要进行文档分割:
为什么要进行文档分割
1. 模型大小和内存限制:GPT 模型,特别是大型版本如 GPT-3 或 GPT-4 ,具有数十亿甚至上百亿的参数。为了在一次前向传播中处理这么多的参数,需要大量的计算能力和内存。但是,大多数硬件设备(例如 GPU 或 TPU )有内存限制。文档分割使模型能够在这些限制内工作。
2. 计算效率:处理更长的文本序列需要更多的计算资源。通过将长文档分割成更小的块,可以更高效地进行计算。
3. 序列长度限制:GPT 模型有一个固定的最大序列长度,例如2048个 token 。这意味着模型一次只能处理这么多 token 。对于超过这个长度的文档,需要进行分割才能被模型处理。
4. 更好的泛化:通过在多个文档块上进行训练,模型可以更好地学习和泛化到各种不同的文本样式和结构。
5. 数据增强:分割文档可以为训练数据提供更多的样本。例如,一个长文档可以被分割成多个部分,并分别作为单独的训练样本。
需要注意的是,虽然文档分割有其优点,但也可能导致一些上下文信息的丢失,尤其是在分割点附近。因此,如何进行文档分割是一个需要权衡的问题。
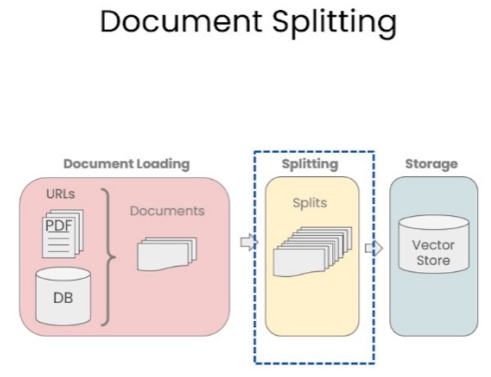
若仅按照单一字符进行文本分割,很容易使文本的语义信息丧失,这样在回答问题时可能会出现偏差。
因此,为了确保语义的准确性,我们应该尽量将文本分割为包含完整语义的段落或单元。
嘿,伙伴们,今天我们的AI探索之旅已经圆满结束。关于“面向开发者的LLM入门教程-为什么要进行文档分割”的内容已经分享给大家了。感谢你们的陪伴,希望这次旅程让你对AI能够更了解、更喜欢。谨记,精准提问是解锁AI潜能的钥匙哦!如果有小伙伴想要了解学习更多的AI知识,请关注我们的官网“AI智研社”,保证让你收获满满呦!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 















还没有评论呢,快来抢沙发~