
面向开发者的LLM入门课程-直接使用向量储存查询: 基于文档的问答 使用大语言模型构建一个能够回答关于给定文档和文档集合的问答系统是一种非常实用和有效的应用场景。……
哈喽!伙伴们,我是小智,你们的AI向导。欢迎来到每日的AI学习时间。今天,我们将一起深入AI的奇妙世界,探索“面向开发者的LLM入门课程-直接使用向量储存查询”,并学会本篇文章中所讲的全部知识点。还是那句话“不必远征未知,只需唤醒你的潜能!”跟着小智的步伐,我们终将学有所成,学以致用,并发现自身的更多可能性。话不多说,现在就让我们开始这场激发潜能的AI学习之旅吧。

面向开发者的LLM入门课程-直接使用向量储存查询:
基于文档的问答
使用大语言模型构建一个能够回答关于给定文档和文档集合的问答系统是一种非常实用和有效的应用场景。与仅依赖模型预训练知识不同,这种方法可以进一步整合用户自有数据,实现更加个性化和专业的问答服务。例如,我们可以收集某公司的内部文档、产品说明书等文字资料,导入问答系统中。然后用户针对这些文档提出问题时,系统可以先在文档中检索相关信息,再提供给语言模型生成答案。
这样,语言模型不仅利用了自己的通用知识,还可以充分运用外部输入文档的专业信息来回答用户问题,显著提升答案的质量和适用性。构建这类基于外部文档的问答系统,可以让语言模型更好地服务于具体场景,而不是停留在通用层面。这种灵活应用语言模型的方法值得在实际使用中推广。
基于文档问答的这个过程,我们会涉及 LangChain 中的其他组件,比如:嵌入模型(Embedding Models)和向量储存(Vector Stores),本章让我们一起来学习这部分的内容。
直接使用向量储存查询
1.导入数据
from langchain.chains import RetrievalQA #检索QA链,在文档上进行检索
from langchain.chat_models import ChatOpenAI #openai模型
from langchain.document_loaders import CSVLoader #文档加载器,采用csv格式存储
from langchain.vectorstores import DocArrayInMemorySearch #向量存储
from IPython.display import display, Markdown #在jupyter显示信息的工具
import pandas as pdfile = ‘../data/OutdoorClothingCatalog_1000.csv’
# 使用langchain文档加载器对数据进行导入
loader = CSVLoader(file_path=file)# 使用pandas导入数据,用以查看
data = pd.read_csv(file,usecols=[1, 2])
data.head()
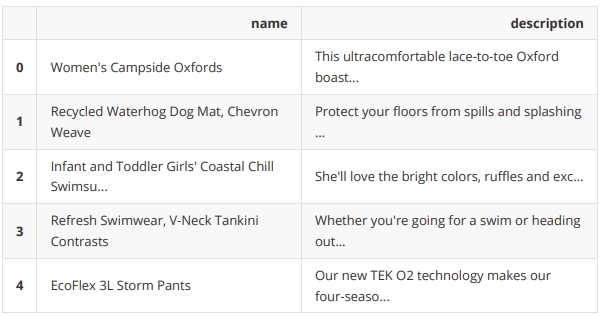
数据是字段为 name 和 description 的文本数据:
可以看到,导入的数据集为一个户外服装的 CSV 文件,接下来我们将在语言模型中使用它。
2.基本文档加载器创建向量存储
#导入向量存储索引创建器
from langchain.indexes import VectorstoreIndexCreator# 创建指定向量存储类, 创建完成后,从加载器中调用, 通过文档加载器列表加载
index =
VectorstoreIndexCreator(vectorstore_cls=DocArrayInMemorySearch).from_loaders([loa
der])
3.查询创建的向量存储
query =”请用markdown表格的方式列出所有具有防晒功能的衬衫,对每件衬衫描述进行总结”
#使用索引查询创建一个响应,并传入这个查询
response = index.query(query)#查看查询返回的内容
display(Markdown(response))
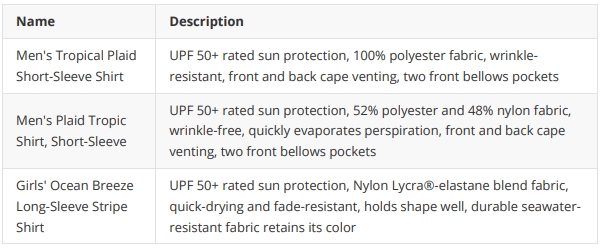
在上面我们得到了一个 Markdown 表格,其中包含所有带有防晒衣的衬衫的 名称(Name) 和 描述(Description) ,其中描述是语言模型总结过的结果。
嘿,伙伴们,今天我们的AI探索之旅已经圆满结束。关于“面向开发者的LLM入门课程-直接使用向量储存查询”的内容已经分享给大家了。感谢你们的陪伴,希望这次旅程让你对AI能够更了解、更喜欢。谨记,精准提问是解锁AI潜能的钥匙哦!如果有小伙伴想要了解学习更多的AI知识,请关注我们的官网“AI智研社”,保证让你收获满满呦!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 















还没有评论呢,快来抢沙发~