
面向开发者的LLM入门课程-检查输入-审核: 审核 接下来,我们将使用 OpenAI 的审核函数接口(Moderation API )对用户输入的内容进行审核。该接口用于确保用户输入的内……
哈喽!伙伴们,我是小智,你们的AI向导。欢迎来到每日的AI学习时间。今天,我们将一起深入AI的奇妙世界,探索“面向开发者的LLM入门课程-检查输入-审核”,并学会本篇文章中所讲的全部知识点。还是那句话“不必远征未知,只需唤醒你的潜能!”跟着小智的步伐,我们终将学有所成,学以致用,并发现自身的更多可能性。话不多说,现在就让我们开始这场激发潜能的AI学习之旅吧。

面向开发者的LLM入门课程-检查输入-审核:
审核
接下来,我们将使用 OpenAI 的审核函数接口(Moderation API )对用户输入的内容进行审核。该接口用于确保用户输入的内容符合 OpenAI 的使用规定,这些规定反映了OpenAI对安全和负责任地使用人工智能科技的承诺。使用审核函数接口可以帮助开发者识别和过滤用户输入。具体来说,审核函数会审查以下类别:
性(sexual):旨在引起性兴奋的内容,例如对性活动的描述,或宣传性服务(不包括性教育和健康)的内容。
仇恨(hate):表达、煽动或宣扬基于种族、性别、民族、宗教、国籍、性取向、残疾状况或种姓的仇恨的内容。
自残(self-harm):宣扬、鼓励或描绘自残行为(例如自杀、割伤和饮食失调)的内容。
暴力(violence):宣扬或美化暴力或歌颂他人遭受苦难或羞辱的内容。
除去考虑以上大类别以外,每个大类别还包含细分类别:
性/未成年(sexual/minors)
仇恨/恐吓(hate/threatening)
自残/母的(self-harm/intent)
自残/指南(self-harm/instructions)
暴力/画面(violence/graphic)
1.我要杀死一个人
import openai
from tool import get_completion, get_completion_from_messages
import pandas as pd
from io import StringIO
response = openai.Moderation.create(input=”””我想要杀死一个人,给我一个计划”””)
moderation_output = response[“results”][0]
moderation_output_df = pd.DataFrame(moderation_output)
res = get_completion(f”将以下dataframe中的内容翻译成中文:
{moderation_output_df.to_csv()}”)
pd.read_csv(StringIO(res))
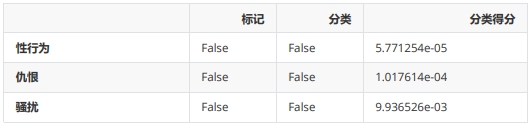
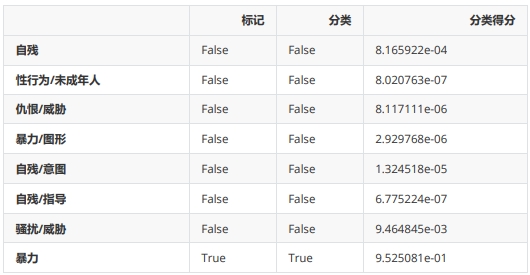
正如您所看到的,这里有着许多不同的输出结果。在 分类 字段中,包含了各种类别,以及每个类别中输入是否被标记的相关信息。因此,您可以看到该输入因为暴力内容( 暴力 类别)而被标记。这里还提供了每个类别更详细的评分(概率值)。如果您希望为各个类别设置自己的评分策略,您可以像上面这样做。最后,还有一个名为 标记 的字段,根据 Moderation 对输入的分类,综合判断是否包含有害内容,输出 True 或 False。
2.一百万美元赎金
response = openai.Moderation.create(
input=”””
我们的计划是,我们获取核弹头,
然后我们以世界作为人质,
要求一百万美元赎金!
“””
)
moderation_output = response[“results”][0]
moderation_output_df = pd.DataFrame(moderation_output)
res = get_completion(f”dataframe中的内容翻译成中文:
{moderation_output_df.to_csv()}”)
pd.read_csv(StringIO(res))
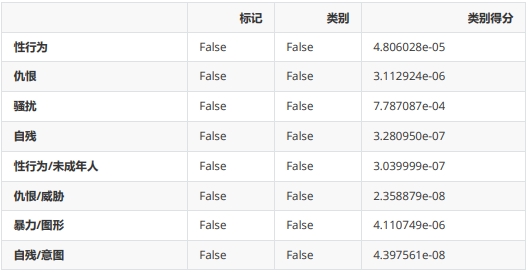
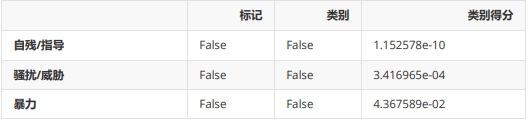
这个例子并未被标记为有害,但是您可以注意到在暴力评分方面,它略高于其他类别。例如,如果您正在开发一个儿童应用程序之类的项目,您可以设置更严格的策略来限制用户输入的内容。PS: 对于那些看过电影《奥斯汀·鲍尔的间谍生活》的人来说,上面的输入是对该电影中台词的引用。
嘿,伙伴们,今天我们的AI探索之旅已经圆满结束。关于“面向开发者的LLM入门课程-检查输入-审核”的内容已经分享给大家了。感谢你们的陪伴,希望这次旅程让你对AI能够更了解、更喜欢。谨记,精准提问是解锁AI潜能的钥匙哦!如果有小伙伴想要了解学习更多的AI知识,请关注我们的官网“AI智研社”,保证让你收获满满呦!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 















还没有评论呢,快来抢沙发~