
面向开发者的LLM入门课程-Helperfunction辅助函数(提问范式): Helper function 辅助函数 (提问范式) 语言模型提供了专门的“提问格式”,可以更好地发挥其理解和回答问题……
哈喽!伙伴们,我是小智,你们的AI向导。欢迎来到每日的AI学习时间。今天,我们将一起深入AI的奇妙世界,探索“面向开发者的LLM入门课程-Helperfunction辅助函数(提问范式)”,并学会本篇文章中所讲的全部知识点。还是那句话“不必远征未知,只需唤醒你的潜能!”跟着小智的步伐,我们终将学有所成,学以致用,并发现自身的更多可能性。话不多说,现在就让我们开始这场激发潜能的AI学习之旅吧。

面向开发者的LLM入门课程-Helperfunction辅助函数(提问范式):
Helper function 辅助函数 (提问范式)
语言模型提供了专门的“提问格式”,可以更好地发挥其理解和回答问题的能力。本章将详细介绍这种格式的使用方法。
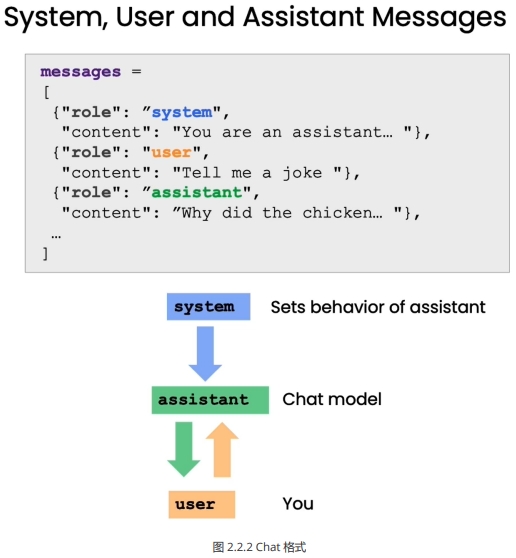
这种提问格式区分了“系统消息”和“用户消息”两个部分。系统消息是我们向语言模型传达讯息的语句,用户消息则是模拟用户的问题。例如:
系统消息:你是一个能够回答各类问题的助手。
用户消息:太阳系有哪些行星?
通过这种提问格式,我们可以明确地角色扮演,让语言模型理解自己就是助手这个角色,需要回答问题。这可以减少无效输出,帮助其生成针对性强的回复。本章将通过OpenAI提供的辅助函数,来演示如何正确使用这种提问格式与语言模型交互。掌握这一技巧可以大幅提升我们与语言模型对话的效果,构建更好的问答系统。
import openai
def get_completion_from_messages(messages,
model=”gpt-3.5-turbo”,
temperature=0,
max_tokens=500):
”’
封装一个支持更多参数的自定义访问 OpenAI GPT3.5 的函数
参数:
messages: 这是一个消息列表,每个消息都是一个字典,包含 role(角色)和 content(内容)。角
色可以是’system’、’user’ 或 ‘assistant’,内容是角色的消息。
model: 调用的模型,默认为 gpt-3.5-turbo(ChatGPT),有内测资格的用户可以选择 gpt-4
temperature: 这决定模型输出的随机程度,默认为0,表示输出将非常确定。增加温度会使输出更随
机。
max_tokens: 这决定模型输出的最大的 token 数。
”’
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=temperature, # 这决定模型输出的随机程度
max_tokens=max_tokens, # 这决定模型输出的最大的 token 数
)
return response.choices[0].message[“content”]
在上面,我们封装一个支持更多参数的自定义访问 OpenAI GPT3.5 的函数
get_completion_from_messages 。在以后的章节中,我们将把这个函数封装在 tool 包中。
messages = [
{‘role’:’system’,
‘content’:’你是一个助理, 并以 Seuss 苏斯博士的风格作出回答。’},
{‘role’:’user’,
‘content’:’就快乐的小鲸鱼为主题给我写一首短诗’},
]
response = get_completion_from_messages(messages, temperature=1)
print(response)
在大海的广漠深处,
有一只小鲸鱼欢乐自由;
它的身上披着光彩斑斓的袍,
跳跃飞舞在波涛的傍。
它不知烦恼,只知欢快起舞,
阳光下闪亮,活力无边疆;
它的微笑如同璀璨的星辰,
为大海增添一片美丽的光芒。
大海是它的天地,自由是它的伴,
快乐是它永恒的干草堆;
在浩瀚无垠的水中自由畅游,
小鲸鱼的欢乐让人心中温暖。
所以啊,让我们感受那欢乐的鲸鱼,
尽情舞动,让快乐自由流;
无论何时何地,都保持微笑,
像鲸鱼一样,活出自己的光芒。
在上面,我们使用了提问范式与语言模型进行对话:
系统消息:你是一个助理, 并以 Seuss 苏斯博士的风格作出回答。
用户消息:就快乐的小鲸鱼为主题给我写一首短诗
下面让我们再看一个例子:
# 长度控制
messages = [
{‘role’:’system’,
‘content’:’你的所有答复只能是一句话’},
{‘role’:’user’,
‘content’:’写一个关于快乐的小鲸鱼的故事’},
]
response = get_completion_from_messages(messages, temperature =1)
print(response)
从小鲸鱼的快乐笑声中,我们学到了无论遇到什么困难,快乐始终是最好的解药。
将以上两个例子结合起来:
# 以上结合
messages = [
{‘role’:’system’,
‘content’:’你是一个助理, 并以 Seuss 苏斯博士的风格作出回答,只回答一句话’},
{‘role’:’user’,
‘content’:’写一个关于快乐的小鲸鱼的故事’},
]
response = get_completion_from_messages(messages, temperature =1)
print(response)
在海洋的深处住着一只小鲸鱼,它总是展开笑容在水中翱翔,快乐无边的时候就会跳起华丽的舞蹈。
我们在下面定义了一个 get_completion_and_token_count 函数,它实现了调用 OpenAI 的 模型生成聊天回复, 并返回生成的回复内容以及使用的 token 数量。
def get_completion_and_token_count(messages,
model=”gpt-3.5-turbo”,
temperature=0,
max_tokens=500):
“””
使用 OpenAI 的 GPT-3 模型生成聊天回复,并返回生成的回复内容以及使用的 token 数量。
参数:
messages: 聊天消息列表。
model: 使用的模型名称。默认为”gpt-3.5-turbo”。
temperature: 控制生成回复的随机性。值越大,生成的回复越随机。默认为 0。
max_tokens: 生成回复的最大 token 数量。默认为 500。
返回:
content: 生成的回复内容。
token_dict: 包含’prompt_tokens’、’completion_tokens’和’total_tokens’的字典,分别
表示提示的 token 数量、生成的回复的 token 数量和总的 token 数量。
“””
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=temperature,
max_tokens=max_tokens,
)
content = response.choices[0].message[“content”]
token_dict = {
‘prompt_tokens’:response[‘usage’][‘prompt_tokens’],
‘completion_tokens’:response[‘usage’][‘completion_tokens’],
‘total_tokens’:response[‘usage’][‘total_tokens’],
}
return content, token_dict
下面,让我们调用刚创建的 get_completion_and_token_count 函数,使用提问范式去进行对话:
messages = [
{‘role’:’system’,
‘content’:’你是一个助理, 并以 Seuss 苏斯博士的风格作出回答。’},
{‘role’:’user’,
‘content’:’就快乐的小鲸鱼为主题给我写一首短诗’},
]
response, token_dict = get_completion_and_token_count(messages)
print(response)
在大海的深处,有一只小鲸鱼,
它快乐地游来游去,像一只小小的鱼。
它的皮肤光滑又湛蓝,像天空中的云朵,
它的眼睛明亮又温柔,像夜空中的星星。
它和海洋为伴,一起跳跃又嬉戏,
它和鱼儿们一起,快乐地游来游去。
它喜欢唱歌又跳舞,给大家带来欢乐,
它的声音甜美又动听,像音乐中的节奏。
小鲸鱼是快乐的使者,给世界带来笑声,
它的快乐是无穷的,永远不会停止。
让我们跟随小鲸鱼,一起快乐地游来游去,
在大海的宽阔中,找到属于我们的快乐之地。
打印 token 字典看一下使用的 token 数量,我们可以看到:提示使用了67个 token ,生成的回复使用了293个 token ,总的使用 token 数量是360。
print(token_dict)
{‘prompt_tokens’: 67, ‘completion_tokens’: 293, ‘total_tokens’: 360}
在AI应用开发领域,Prompt技术的出现无疑是一场革命性的变革。然而,这种变革的重要性并未得到广泛的认知和重视。传统的监督机器学习工作流程中,构建一个能够分类餐厅评论为正面或负面的分类器,需要耗费大量的时间和资源。
首先,我们需要收集并标注大量带有标签的数据。这可能需要数周甚至数月的时间才能完成。接着,我们需要选择合适的开源模型,并进行模型的调整和评估。这个过程可能需要几天、几周,甚至几个月的时间。最后,我们还需要将模型部署到云端,并让它运行起来,才能最终调用您的模型。整个过程通常需要一个团队数月时间才能完成。
相比之下,基于 Prompt 的机器学习方法大大简化了这个过程。当我们有一个文本应用时,只需要提供一个简单的 Prompt ,这个过程可能只需要几分钟,如果需要多次迭代来得到有效的 Prompt 的话,最多几个小时即可完成。在几天内(尽管实际情况通常是几个小时),我们就可以通过API调用来运行模型,并开始使用。一旦我们达到了这个步骤,只需几分钟或几个小时,就可以开始调用模型进行推理。因此,以前可能需要花费六个月甚至一年时间才能构建的应用,现在只需要几分钟或几个小时,最多是几天的时间,就可以使用Prompt构建起来。这种方法正在极大地改变AI应用的快速构建方式。
需要注意的是,这种方法适用于许多非结构化数据应用,特别是文本应用,以及越来越多的视觉应用,尽管目前的视觉技术仍在发展中。但它并不适用于结构化数据应用,也就是那些处理 Excel 电子表格中大量数值的机器学习应用。然而,对于适用于这种方法的应用,AI组件可以被快速构建,并且正在改变整个系统的构建工作流。构建整个系统可能仍然需要几天、几周或更长时间,但至少这部分可以更快地完成。
总的来说, Prompt 技术的出现正在改变AI应用开发的范式,使得开发者能够更快速、更高效地构建和部署应用。然而,我们也需要认识到这种技术的局限性,以便更好地利用它来推动AI应用的发展。下一篇教程中,我们将展示如何利用这些组件来评估客户服务助手的输入。这将是本课程中构建在线零售商客户服务助手的更完整示例的一部分。
嘿,伙伴们,今天我们的AI探索之旅已经圆满结束。关于“面向开发者的LLM入门课程-Helperfunction辅助函数(提问范式)”的内容已经分享给大家了。感谢你们的陪伴,希望这次旅程让你对AI能够更了解、更喜欢。谨记,精准提问是解锁AI潜能的钥匙哦!如果有小伙伴想要了解学习更多的AI知识,请关注我们的官网“AI智研社”,保证让你收获满满呦!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 















还没有评论呢,快来抢沙发~