
大模型LLM面试题大全超详细解析21-25题: 《大模型LLM面试题大全超详细解析》系列教程旨在帮助求职者系统掌握大模型相关面试知识。教程涵盖模型原理、训练技巧、应用场……
哈喽!伙伴们,我是小智,你们的AI向导。欢迎来到每日的AI学习时间。今天,我们将一起深入AI的奇妙世界,探索“大模型LLM面试题大全超详细解析21-25题”,并学会本篇文章中所讲的全部知识点。还是那句话“不必远征未知,只需唤醒你的潜能!”跟着小智的步伐,我们终将学有所成,学以致用,并发现自身的更多可能性。话不多说,现在就让我们开始这场激发潜能的AI学习之旅吧。

大模型LLM面试题大全超详细解析21-25题:
《大模型LLM面试题大全超详细解析》系列教程旨在帮助求职者系统掌握大模型相关面试知识。教程涵盖模型原理、训练技巧、应用场景及优化策略等核心内容,结合真实面试题,提供详细解析与实战技巧。无论你是初学者还是进阶者,都能从中获得实用指导,轻松应对大模型领域的面试挑战,提升求职竞争力。
21、是否需要为所有基于文本的LLM用例提供矢量存储?
答案:不需要
向量存储用于存储单词或句子的向量表示。这些向量表示捕获单词或句子的语义,并用于各种NLP任务。并非所有基于文本的LLM用例都需要矢量存储。有些任务,如情感分析和翻译,不需要RAG也就不需要矢量存储。
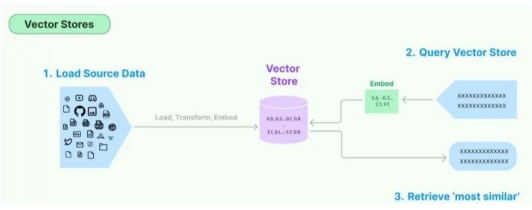
最常见的不需要矢量存储的:
1、情感分析:这项任务包括确定一段文本中表达的情感(积极、消极、中性)。它通常基于文本本身而不需要额外的上下文。
2、这项任务包括将文本从一种语言翻译成另一种语言。上下文通常由句子本身和它所属的更广泛的文档提供,而不是单独的向量存储。
22、以下哪一项不是专门用于将大型语言模型(llm)与人类价值观和偏好对齐的技术?
答案:
A.RLHF
B.Direct Preference Optimization
C.Data Augmentation
答案:C
数据增强Data Augmentation是一种通用的机器学习技术,它涉及使用现有数据的变化或修改来扩展训练数据。
虽然它可以通过影响模型的学习模式间接影响LLM一致性,但它并不是专门为人类价值一致性而设计的。
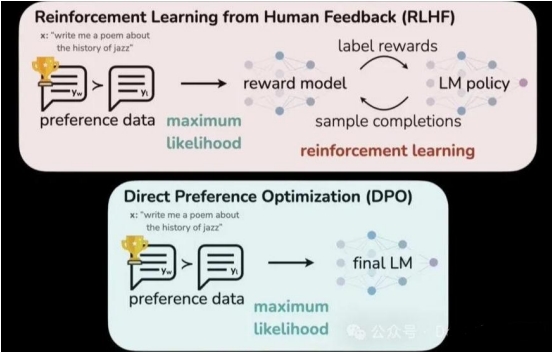
A)从人类反馈中强化学习(RLHF)是一种技术,其中人类反馈用于改进LLM的奖励函数,引导其产生与人类偏好一致的输出。
B)直接偏好优化(DPO)是另一种基于人类偏好直接比较不同LLM输出以指导学习过程的技术。
23、在RLHF中,如何描述“reward hacking”?
答案:
A.优化所期望的行为
B.利用奖励函数漏洞
答案:B
reward hacking是指在RLHF中,agent发现奖励函数中存在意想不到的漏洞或偏差,从而在没有实际遵循预期行为的情况下获得高奖励的情况,也就是说,在奖励函数设计不有漏洞的情况下才会出现reward hacking的问题。
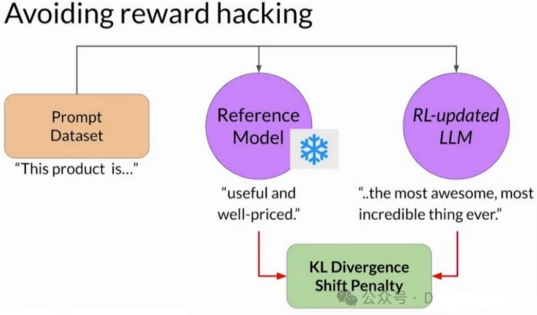
虽然优化期望行为是RLHF的预期结果,但它并不代表reward hacking。选项A描述了一个成功的训练过程。在reward hacking中,代理偏离期望的行为,找到一种意想不到的方式(或者漏洞)来最大化奖励。
24、对任务的模型进行微调(创造性写作),哪个因素显著影响模型适应目标任务的能力?
答案:
A.微调数据集的大小
B.预训练的模型架构和大小
答案:B
预训练模型的体系结构作为微调的基础。像大型模型(例如GPT-3)中使用的复杂而通用的架构允许更大程度地适应不同的任务。微调数据集的大小发挥了作用,但它是次要的。一个架构良好的预训练模型可以从相对较小的数据集中学习,并有效地推广到目标任务。
虽然微调数据集的大小可以提高性能,但它并不是最关键的因素。即使是庞大的数据集也无法弥补预训练模型架构的局限性。设计良好的预训练模型可以从较小的数据集中提取相关模式,并且优于具有较大数据集的不太复杂的模型。
25、transformer 结构中的自注意力机制在模型主要起到了什么作用?
答案:
A.衡量单词的重要性
B.预测下一个单词
C.自动总结
答案:A
transformer 的自注意力机制会对句子中单词的相对重要性进行总结。根据当前正在处理的单词动态调整关注点。相似度得分高的单词贡献更显著,这样会对单词重要性和句子结构的理解更丰富。这为各种严重依赖上下文感知分析的NLP任务提供了支持。
嘿,伙伴们,今天我们的AI探索之旅已经圆满结束。关于“大模型LLM面试题大全超详细解析21-25题”的内容已经分享给大家了。感谢你们的陪伴,希望这次旅程让你对AI能够更了解、更喜欢。谨记,精准提问是解锁AI潜能的钥匙哦!如果有小伙伴想要了解学习更多的AI知识,请关注我们的官网“AI智研社”,保证让你收获满满呦!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 















还没有评论呢,快来抢沙发~