
最新版AI大模型面试八股文136-140题: AI大模型风头正劲,相关岗位炙手可热,竞争也异常激烈。想要在面试中脱颖而出,除了扎实的技术功底,还需要对面试套路了如指掌。……
哈喽!伙伴们,我是小智,你们的AI向导。欢迎来到每日的AI学习时间。今天,我们将一起深入AI的奇妙世界,探索“最新版AI大模型面试八股文136-140题”,并学会本篇文章中所讲的全部知识点。还是那句话“不必远征未知,只需唤醒你的潜能!”跟着小智的步伐,我们终将学有所成,学以致用,并发现自身的更多可能性。话不多说,现在就让我们开始这场激发潜能的AI学习之旅吧。

最新版AI大模型面试八股文136-140题:
AI大模型风头正劲,相关岗位炙手可热,竞争也异常激烈。想要在面试中脱颖而出,除了扎实的技术功底,还需要对面试套路了如指掌。这份最新版AI大模型面试八股文,正是为你量身打造的“通关秘籍”!
136、基于attention有哪些代表性的改进方法?分别针对的是什么问题
答案:
1. 多头注意力(Multi-Head Attention):在标准attention机制中,输入被缩放然后与权重相乘以产生输出。在多头attention中,输入首先被分为多个“头”,每个头独立计算attention权重,然后将结果拼接起来。这种方法可以使模型更好地理解和处理输入数据。
2. 自注意力(Self-Attention):在许多任务中,输入数据的一部分与另一部分是高度相关的。自注意力机制让模型学习这种关系,从而提高性能。例如,在机器翻译任务中,句子中的单词可能会依赖于其他单词。通过让模型关注整个句子,而不是仅仅关注当前单词,可以提高翻译的准确性。
3. 局部注意力(Local Attention):与全局注意力相反,局部注意力只关注输入的局部区域。这种方法可以减少计算量,并使模型更好地理解输入数据的结构。
4. 加权平均注意力(Scaled Dot-Product Attention with Optional Additional Heads):在多头attention中,每个头的输出被缩放然后相加。加权平均注意力是对此方法的改进,它根据头的输出为每个头分配不同的权重。这可以进一步提高模型的性能。
137、如何设计更有效的注意力机制来处理层次化或结构化数据?
答案:
层次化注意力机制(Hierarchical Attention):层次化注意力机制在处理具有层次结构的输入时非常有效,如文档分类、句子级情感分析等。它首先将输入划分为不同的层次(如句子、段落等),然后在每个层次上计算注意力得分,并将结果汇总到最终的输出中。层次化注意力机制能够让模型在处理复杂输入时更好地关注到关键信息。
138、self-attention时间复杂度
答案:

139、逻辑回归为什么用交叉熵不用mse
答案:
逻辑回归模型不用MSE作为损失函数的原因主要有两个,一个从背景意义来说,交叉熵函数更贴切“概率”的意义。另一方面是从求解的角度,交叉熵损失函数比MSE损失函数更易于求解。
140、介绍一个transformer变体
答案:
ViT的首要意义就是将Transformer成功应用于计算机视觉任务,如图像分类、目标检测等。为研究人员提供了一种新的思路,即在计算机视觉任务中探索更多基于自注意力机制的模型设计
在分割任务中,ViT可以被用作特征提取器,将图像编码为特征向量,然后通过后续的分割头进行像素级别的预测,将图像中的每个像素分类到不同的语义类别中。
ViT会将输入图像分成一个个小的图像块(patches),并将每个图像块展平为一个向量,然后利用Transformer编码器学习全局特征和依赖关系。这种方法的优势在于,ViT能够利用自注意力机制来处理整个图像,而不是仅关注局部区域,从而提高了图像理解的能力。
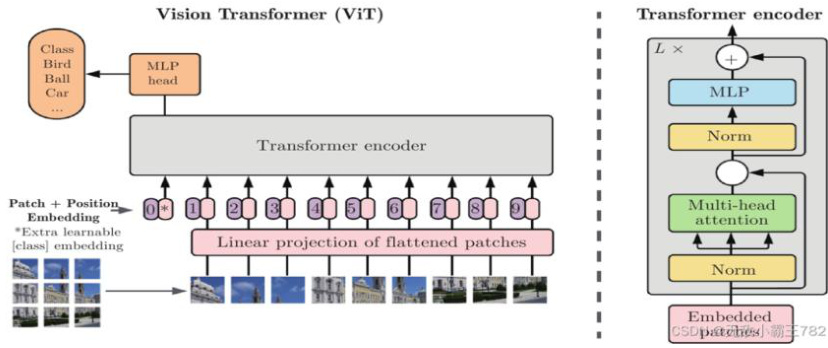
上图就是VIT模型的整体框架,由以下几个部分构成:
输入图像切分:首先,将输入的图像分割成一系列的固定大小的图像块(通常是16×16或32×32的小图像块)。
每个图像块将被看作一个序列元素。
嵌入层(Embedding Layer):每个图像块通过一个嵌入层进行编码,将每个像素的特征表示转换为更高维的嵌入向量。这些嵌入向量将作为输入序列送入Transformer模型。
位置编码(Positional Encoding):与传统Transformer类似,ViT模型在输入序列中引入位置信息。这是通过添加位置编码向量到每个图像块的嵌入向量中来实现的,从而使模型能够理解图像中的空间关系。
Transformer Encoder:接下来,ViT模型使用一层或多层的Transformer编码器来处理输入序列。每个编码器由多头自注意力机制(Multi-Head Self-Attention)和前馈神经网络(Feed-Forward Neural Network)两部
分组成。
多头自注意力机制:用于捕捉序列中不同位置之间的关系,特别是在图像块之间建立联系。它允许模型在处理每个图像块时能够关注其他图像块的信息,从而捕获全局的语义信息。
前馈神经网络:用于对每个图像块的特征进行非线性变换,以增强特征的表示能力。
池化和分类层:在经过一系列Transformer编码器后,ViT模型通常会采用全局平均池化(Global AveragePooling)来聚合所有图像块的信息,生成整体图像的特征表示。最后,将这些特征送入一个全连接层进行分类预测。
ViT模型的关键创新在于将图像块转化为序列数据,并利用Transformer的自注意力机制来捕获图像中的全局和局部信息。这使得ViT能够在一定程度上摆脱传统卷积神经网络的限制,对遮挡、尺度变化和位置变换等问题具有一定的鲁棒性。
嘿,伙伴们,今天我们的AI探索之旅已经圆满结束。关于“最新版AI大模型面试八股文136-140题”的内容已经分享给大家了。感谢你们的陪伴,希望这次旅程让你对AI能够更了解、更喜欢。谨记,精准提问是解锁AI潜能的钥匙哦!如果有小伙伴想要了解学习更多的AI知识,请关注我们的官网“AI智研社”,保证让你收获满满呦!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 















还没有评论呢,快来抢沙发~