
最新版AI大模型面试八股文116-120题: AI大模型风头正劲,相关岗位炙手可热,竞争也异常激烈。想要在面试中脱颖而出,除了扎实的技术功底,还需要对面试套路了如指掌。……
哈喽!伙伴们,我是小智,你们的AI向导。欢迎来到每日的AI学习时间。今天,我们将一起深入AI的奇妙世界,探索“最新版AI大模型面试八股文116-120题”,并学会本篇文章中所讲的全部知识点。还是那句话“不必远征未知,只需唤醒你的潜能!”跟着小智的步伐,我们终将学有所成,学以致用,并发现自身的更多可能性。话不多说,现在就让我们开始这场激发潜能的AI学习之旅吧。

最新版AI大模型面试八股文116-120题:
AI大模型风头正劲,相关岗位炙手可热,竞争也异常激烈。想要在面试中脱颖而出,除了扎实的技术功底,还需要对面试套路了如指掌。这份最新版AI大模型面试八股文,正是为你量身打造的“通关秘籍”!
116、为什么说Transformer 的注意力机制是相对廉价的?注意力机制相对更对于RNN 系列及Convolution 系列算法而言在计算上(尤其是计算复杂度)有什么优势?
答案:
并行计算:注意力机制中的计算可以高度并行化,每个注意力头都可以独立计算,而不受其他头的影响。这意味着可以同时计算多个头的注意力权重,大大加快了计算速度。相比之下,RNN和CNN等序列模型通常需要顺序计算,难以实现高效的并行计算。
局部连接性:在注意力机制中,每个位置只与其他位置进行注意力计算,而不是与整个序列进行计算。这种局部连接性使得注意力机制的计算复杂度不会随着序列长度的增加而呈现线性增长。相比之下,RNN和CNN等序列模型通常需要在每个时间步或每个位置上进行固定的计算操作,导致计算复杂度随着序列长度的增加而线性增长。
自注意力机制的简化:在Transformer中使用的自注意力机制相对于传统的注意力机制更加简化和高效。通过使用矩阵乘法和softmax操作,可以快速计算出每个位置对其他位置的注意力权重,而无需显式计算所有可能的组合。这种简化使得注意力机制的计算成本大大降低。
117、请分享一下至少三种提升Transformer 预测速度的具体的方法及其数学原理
答案:
注意力头的减少:通过减少注意力头的数量来降低计算量。在Transformer中,每个注意力头都需要计算查询(query)、键(key)和值(value)之间的注意力权重,然后将值加权求和以生成输出。减少注意力头的数量可以大大减少计算复杂度。
局部注意力机制:使用局部注意力机制来减少每个位置计算注意力时需要考虑的范围。在局部注意力机制中,每个位置只与其周围一定范围内的位置进行注意力计算,而不是与整个序列进行计算。这样可以显著降低计算量,特别是在处理长序列时。数学上,局部注意力机制可以通过限制注意力权重矩阵中的非零元素范围来实现。
参数量的减少:减少Transformer模型中的参数量可以降低模型的计算量。例如,可以通过减少隐藏层的维度、减少编码器和解码器的层数或减少词嵌入的维度来降低模型的参数量。这样可以降低模型的计算复杂度,并且可以提高模型的训练和推理速度。数学上,参数量的减少会直接影响模型中矩阵乘法和参数更新的计算量。
118、请分别描述Bert 的MLM 和NSP 技术(例如Sampling) 的问题及具体改进方式
答案:
MLM(Masked Language Model):
问题:MLM任务中,部分输入词被随机掩盖(用MASK符号替换),模型需要预测这些被掩盖的词。然而,由于随机地掩盖词语,可能会导致模型在训练过程中学习到过于简单或者不太自然的预测模式,
具体改进方式:可以采用更加智能的掩盖策略,例如选择更具语义相关性的词进行掩盖,或者通过结合其他任务(如词义消歧)来指导掩盖策略。另外,还可以尝试使用更加复杂的训练目标,例如通过引入额外的噪声来增加模型的鲁棒性。
NSP(Next Sentence Prediction):
问题:NSP任务中,模型需要判断两个句子是否是连续的,这种二分类任务可能会过于简化,无法充分利用句子之间的语义关系,尤其是对于复杂的语义关系和长文本。
具体改进方式:可以考虑引入更多的语义相关性指导模型的学习,例如通过更丰富的句子对策略来选择训练样本,或者结合其他任务(如句子级别的语义匹配)来增强模型的语义理解能力。另外,可以尝试引入更复杂的模型结构,例如使用更多的注意力头或者更深的网络层来提高模型的表示能力。
119、请阐述使用Transformer 实现Zero-shot Learning 数学原理和具体实现流程数学原理:
答案:
Transformer模型在预训练阶段学习到了词嵌入和句子表示,这些表示具有丰富的语义信息,可以很好地捕捉单词和句子之间的语义关系。
零样本学习的关键在于将未见过的类别与已知类别之间的语义关系进行建模。Transformer模型学习到的语义表示可以用来衡量不同类别之间的语义相似度,从而实现对未见过类别的分类。
具体实现流程:
准备数据:首先,需要准备一个包含已知类别和未知类别的语义表示。可以使用预训练的Transformer模型,如BERT、RoBERTa等,将每个类别的文本描述转换为语义表示。
计算相似度:对于给定的未见过的类别,将其文本描述转换为语义表示,并与所有已知类别的语义表示计算相似度。可以使用余弦相似度或其他距离度量来衡量相似度。
分类预测:根据计算得到的相似度,选择与未见类别语义表示最相似的已知类别作为预测结果。可以使用最近邻分类器或其他机器学习算法来实现分类预测。
这一部分包包给出了答案,在你十分清楚transformer结构后,可以加强这些题目来强化对于
transformer的理解。当然如果你是一知半解,也可以读来做一个强化学习。
120、Self-Attention的表达式
答案:
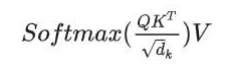
嘿,伙伴们,今天我们的AI探索之旅已经圆满结束。关于“最新版AI大模型面试八股文116-120题”的内容已经分享给大家了。感谢你们的陪伴,希望这次旅程让你对AI能够更了解、更喜欢。谨记,精准提问是解锁AI潜能的钥匙哦!如果有小伙伴想要了解学习更多的AI知识,请关注我们的官网“AI智研社”,保证让你收获满满呦!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 















还没有评论呢,快来抢沙发~