
最新版AI大模型面试八股文101-105题: AI大模型风头正劲,相关岗位炙手可热,竞争也异常激烈。想要在面试中脱颖而出,除了扎实的技术功底,还需要对面试套路了如指掌。……
哈喽!伙伴们,我是小智,你们的AI向导。欢迎来到每日的AI学习时间。今天,我们将一起深入AI的奇妙世界,探索“最新版AI大模型面试八股文101-105题”,并学会本篇文章中所讲的全部知识点。还是那句话“不必远征未知,只需唤醒你的潜能!”跟着小智的步伐,我们终将学有所成,学以致用,并发现自身的更多可能性。话不多说,现在就让我们开始这场激发潜能的AI学习之旅吧。

最新版AI大模型面试八股文101-105题:
AI大模型风头正劲,相关岗位炙手可热,竞争也异常激烈。想要在面试中脱颖而出,除了扎实的技术功底,还需要对面试套路了如指掌。这份最新版AI大模型面试八股文,正是为你量身打造的“通关秘籍”!
101、简单描述一下wordpiece model 和byte pair encoding,有实际应用过吗?
答案:WordPiece Model和Byte Pair Encoding(BPE)都是子词分割技术。
WordPiece将词分割成子词,提高模型的词汇覆盖率。BPE是合并最频繁的字对。
1. WordPiece Model:
想象一下,你有一个工具箱,里面有各种各样的拼图碎片,每个碎片代表一个语素或词的一部分。WordPiece模型就像这个工具箱,它把单词分解成更小的、有意义的片段。
这样做的好处是,即使工具箱里没有某个完整的单词,你也可以通过拼凑这些小片段来表达这个单词的意思。在机器学习中,这可以帮助模型理解和生成新的、未见过的词汇。
2.Byte Pair Encoding(BPE):
BPE更像是一种编码技巧,它观察文本数据,找出最常见的字节对,然后把这些字节对合并成一个单一的单元。比如,“power”和“ful”这样的词,如果它们经常一起出现,BPE就会把它们看作一个单元。这样做可以减少词汇表的大小,同时保持词汇的多样性。
实际应用:
这两种技术在自然语言处理(NLP)中非常实用,特别是在机器翻译、文本生成等任务中。它们帮助模型处理那些在训练数据中很少见或完全没见过的词汇。
102、Transformer训练的时候学习率是如何设定的?Dropout是如何设定的,位置在哪里?Dropout 在测试的需要有什么需要注意的吗?
答案:
(1)预热策略:Transformer通常使用预热(warm-up)策略和学习率衰减相结合的方法。在训练的前一部分迭代中,学习率逐渐增加,然后按照预定的方式逐渐减少。
其中,d model是模型的维度,step_num 是当前训练步数,warmup_steps 是预热步数。
(2)Transformer中使用Dropout层来防止过拟合,具体位置包括:
(3)测试时:不使用Dropout:在测试或推理阶段,Dropout不再使用,即不会随机丢弃节点,而是使用所有节点参与计算。
103、引申一个关于bert问题,bert的mask为何不学习transformer在attention处进行屏蔽score的技巧?
答案:
BERT的掩码设计目的是为了在预训练过程中让模型学习丰富的上下文表示,而不是为了防止信息泄漏,这与
Transformer中attention mask的用途不同。BERT中的mask:
1.预训练任务:BERT使用掩码语言模型(Masked Language Model, MLM)进行预训练,即在输入序列中随机选择一些单词进行掩码,然后让模型预测这些掩码位置的单词。
2.原因:独立于位置的预测:BERT的掩码操作是对输入的特定位置进行掩码,目的是让模型能够学习到每个单词的上下文表示,而不需要关注具体位置。
3.不同任务:BERT的设计目标是让模型学习到每个单词的上下文表示,而Transformer的attention掩码(mask)主要用于在序列生成中防止信息泄漏,如自回归模型中防止预测未来的单词。
Transformer的注意力掩码(attention mask):
1.屏蔽未来信息:在自回归模型中,如GPT,使用注意力掩码来屏蔽未来的单词,以防止信息泄漏,从而确保模型只能利用当前和过去的信息进行预测。
2.序列长度不同:在处理不同长度的序列时,使用掩码来标识实际存在的部分和填充部分(padding),从而保证模型的注意力计算只在有效部分进行。
104、请阐述Transformer 能够进行训练来表达和生成信息背后的数学假设,什么数学模型
答案:

105、Transformer 的Positional Encoding 是如何表达相对位置关系的,位置信息在不同的Encoder 的之间传递会丢失吗?
答案:
Transformer中的Positional Encoding用于向输入的词嵌入中添加位置信息,以便模型能够理解输入序列中词语的位置顺序。Positional Encoding通常是通过将位置信息编码成一个固定长度的向量,并将其与词嵌入相加来实现的。
Positional Encoding的一种常见表达方式是使用正弦和余弦函数,通过计算不同位置的位置编码向量来表示相对位置关系。具体来说,位置pos 的位置编码PE(pos)可以表示为:
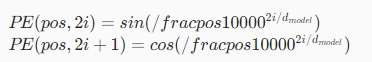
其中,pos 是位置,i 是位置编码向量中的维度索引, dmodel是词嵌入维度。这种位置编码方式允许模型学习到不同位置之间的相对位置关系,同时能够保持一定的周期性。
至于位置信息在不同的Encoder之间是否会丢失,答案是不会。在Transformer模型中,位置编码是在每个Encoder和Decoder层中加入的,并且会随着词嵌入一起流经整个模型。因此,每个Encoder和Decoder层都会接收到包含位置信息的输入向量,从而能够保留输入序列的位置关系。这样,位置信息可以在不同的Encoder之间传递,并且不会丢失。
嘿,伙伴们,今天我们的AI探索之旅已经圆满结束。关于“最新版AI大模型面试八股文101-105题”的内容已经分享给大家了。感谢你们的陪伴,希望这次旅程让你对AI能够更了解、更喜欢。谨记,精准提问是解锁AI潜能的钥匙哦!如果有小伙伴想要了解学习更多的AI知识,请关注我们的官网“AI智研社”,保证让你收获满满呦!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 















还没有评论呢,快来抢沙发~