
最新版AI大模型面试八股文91-100题: AI大模型风头正劲,相关岗位炙手可热,竞争也异常激烈。想要在面试中脱颖而出,除了扎实的技术功底,还需要对面试套路了如指掌。这……
哈喽!伙伴们,我是小智,你们的AI向导。欢迎来到每日的AI学习时间。今天,我们将一起深入AI的奇妙世界,探索“最新版AI大模型面试八股文91-100题”,并学会本篇文章中所讲的全部知识点。还是那句话“不必远征未知,只需唤醒你的潜能!”跟着小智的步伐,我们终将学有所成,学以致用,并发现自身的更多可能性。话不多说,现在就让我们开始这场激发潜能的AI学习之旅吧。

最新版AI大模型面试八股文91-100题:
AI大模型风头正劲,相关岗位炙手可热,竞争也异常激烈。想要在面试中脱颖而出,除了扎实的技术功底,还需要对面试套路了如指掌。这份最新版AI大模型面试八股文,正是为你量身打造的“通关秘籍”!
91、为何在获取输入词向量之后需要对矩阵乘以embedding size的开方?意义是什么?
答案:在获取输入词向量之后,需要对矩阵乘以embedding size的平方根,是为了保持向量的尺度稳定。Embedding的值通常是随机初始化的,乘以开方后的结果能保证在后续的点乘计算中,值的尺度不会过大或过小,从而有利于模型的训练稳定性。
92、简单介绍一下Transformer的位置编码?有什么意义和优缺点?
答案:Transformer的位置编码(Positional Encoding)是为了给模型提供序列中各个位置的信息,因为Transformer本身不具备顺序信息。位置编码通过正弦和余弦函数生成,对不同位置生成不同的编码。
优点是能够显式地提供位置信息,易于计算,缺点是位置编码固定,不能根据上下文动态调整。
93、你还了解哪些关于位置编码的技术,各自的优缺点是什么?
答案:除了位置编码,其他位置表示技术还有:
• 可学习的位置编码(Learnable Positional Encoding):位置编码作为可学习的参数,优点是灵活,能够根据数据调整,缺点是可能需要更多的训练数据。
• 相对位置编码(Relative Positional Encoding):考虑到相对位置关系,优点是能够捕捉相对位置信息,适用于长序列,缺点是实现复杂度高。
• 混合位置编码(Hybrid Positional Encoding):结合绝对和相对位置编码,优点是综合两者优点,缺点是实现复杂度增加。
94、简单讲一下Transformer中的残差结构以及意义。
答案:Transformer中的残差结构(Residual Connection)是在每个子层输出后,加入输入的原始信息,通过直接相加实现。这有助于缓解深层网络中的梯度消失问题,保证信息流的顺畅,促进训练过程的稳定和快速收敛。
95、为什么transformer块使用LayerNorm而不是BatchNorm?LayerNorm 在Transformer的位置是哪里?
答案:Transformer块使用LayerNorm而不是BatchNorm,因为LayerNorm在序列模型中表现更好。BatchNorm在处理变长序列和小批量数据时不稳定,而LayerNorm对每个样本独立进行归一化,更适合变长序列数据。LayerNorm通常位于每个子层的残差连接之后。
96、简答讲一下BatchNorm技术,以及它的优缺点。
答案:BatchNorm(批量归一化)是对每个小批量数据进行归一化,减去均值除以标准差,再引入可学习的缩放和平移参数。
优点是加快训练速度,缓解梯度消失和爆炸问题。缺点是在小批量或变长序列中效果不稳定,不适合序列模型。
97、简单描述一下Transformer中的前馈神经网络?使用了什么激活函数?相关优缺点?
答案:Transformer中的前馈神经网络FeedForward由两个线性变换和一个激活函数组成,激活函数通常是ReLU。如下公式:max相当于Relu
优点是增加模型的非线性表达能力,结构简单高效。缺点是ReLU可能导致部分神经元输出恒为零(死神经元),需要慎重选择超参数。
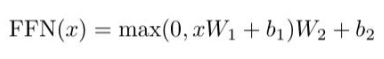
98、Encoder端和Decoder端是如何进行交互的?(在这里可以问一下关于seq2seq的attention知识)
答案:Encoder端和Decoder端通过注意力机制进行交互。Encoder将输入序列编码成隐藏表示,Decoder通过多头注意力机制,将编码器的输出作为键和值,解码器的输出作为查询,计算注意力得分,从编码器的输出中提取相关信息,生成新的输出序列。
下面用一个更通俗的类比来解释Transformer中编码器(Encoder)和解码器(Decoder)之间的交互。想象一下,编码器和解码器是两个团队,它们要共同完成一个任务:把一种语言翻译成另一种语言。
1.编码器团队(Encoder):
• 编码器团队的任务是仔细阅读原始语言(比如英语)的句子,并理解它的意思。
• 每个团队成员(编码器层)都会贡献自己对句子的理解,最终形成一个整体的理解(隐藏状态)。
2.解码器团队(Decoder):
• 解码器团队的任务是根据编码器团队的理解,逐字逐句地把句子翻译成目标语言(比如法语)。
3.交互的桥梁:注意力机制:
• 当解码器团队开始工作时,他们需要不断地与编码器团队沟通,以确保翻译的准确性。
• 他们通过一个特殊的“对讲机”(注意力机制)来沟通。解码器团队的每个成员(解码器层)都会问编码器团队:“在这个翻译步骤中,原文中的哪个部分最重要?”
4.编码器团队的回答:
• 编码器团队会根据解码器团队的问题,给出一个“重要性评分”(注意力权重),告诉解码器团队在当前翻译步骤中,原文的哪些部分是重要的。
5.解码器团队的翻译:
• 根据编码器团队给出的重要性评分,解码器团队会综合考虑这些信息,并决定下一个翻译出的词是什么。这个过程会一直重复,直到整个句子被翻译完成。
6.防止作弊的规则(掩码):
• 在翻译过程中,有一个规则:解码器团队不能提前看到未来的词(不能作弊)。所以他们会用一个“遮盖布”(掩码)来确保在翻译当前词时,只能看到已经翻译出来的部分。
通过这种方式,Transformer模型中的编码器和解码器可以协同工作,完成复杂的任务,比如语言翻译、文本摘要等。编码器团队深入理解输入信息,而解码器团队则利用这些理解,一步步构建出高质量的输出。
(Seq2seq(序列到序列)模型中,注意力机制用来解决长序列依赖问题。传统的seq2seq模型在解码时只能使用Encoder的最后一个隐状态,这对于长序列可能效果不好。注意力机制通过计算Decoder的每个时间步与Encoder输出的所有时间步之间的相关性,动态地选择信息,提升了翻译效果。)
99、Decoder阶段的多头自注意力和encoder的多头自注意力有什么区别?(为什么需要decoder自注意力需要进行sequence mask)
答案:Decoder阶段的多头自注意力需要进行sequence mask,以防止模型在训练时看到未来的单词。Encoder的多头自注意力没有这种限制。Sequence mask确保模型只关注已生成的部分,避免信息泄露,提高训练的效果。
100、Transformer的并行化提现在哪个地方?Decoder端可以做并行化吗?
答案:Transformer的并行化体现在注意力机制和前馈神经网络上,因为每个时间步的计算彼此独立。
Decoder端不能完全并行化,因为当前步的输出依赖于前一步的结果,但自注意力机制部分可以并行化。
嘿,伙伴们,今天我们的AI探索之旅已经圆满结束。关于“最新版AI大模型面试八股文91-100题”的内容已经分享给大家了。感谢你们的陪伴,希望这次旅程让你对AI能够更了解、更喜欢。谨记,精准提问是解锁AI潜能的钥匙哦!如果有小伙伴想要了解学习更多的AI知识,请关注我们的官网“AI智研社”,保证让你收获满满呦!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 















还没有评论呢,快来抢沙发~