
最新版AI大模型面试八股文81-90题: AI大模型风头正劲,相关岗位炙手可热,竞争也异常激烈。想要在面试中脱颖而出,除了扎实的技术功底,还需要对面试套路了如指掌。这……
哈喽!伙伴们,我是小智,你们的AI向导。欢迎来到每日的AI学习时间。今天,我们将一起深入AI的奇妙世界,探索“最新版AI大模型面试八股文81-90题”,并学会本篇文章中所讲的全部知识点。还是那句话“不必远征未知,只需唤醒你的潜能!”跟着小智的步伐,我们终将学有所成,学以致用,并发现自身的更多可能性。话不多说,现在就让我们开始这场激发潜能的AI学习之旅吧。

最新版AI大模型面试八股文81-90题:
AI大模型风头正劲,相关岗位炙手可热,竞争也异常激烈。想要在面试中脱颖而出,除了扎实的技术功底,还需要对面试套路了如指掌。这份最新版AI大模型面试八股文,正是为你量身打造的“通关秘籍”!
81、Transformer模型中的前馈网络(Feed-Forward Networks)的作用是什么?
答案:作用:前馈网络对自注意力层的输出进行非线性变换,增加了模型的表达能力,并可以捕捉局部特征。
82、Transformer网络很深,是怎么避免过拟合问题的?
答案:Transformer网络采用以下机制以避免过拟合并促进深层结构的训练:Dropout: 在自注意力、前馈层和嵌入层中随机抑制节点激活,提高泛化性。权重衰减:引入L2正则化惩罚过大的权重参数,限制模型复杂度。
标签平滑:在损失函数中对真实标签分布进行平滑,避免模型对某些类别的过度自信。残差连接:通过跳跃连接,实现特征直传,缓解梯度消失问题并加速收敛。
83、Transformer的两个mask机制是什么?
答案:
两种掩码:
序列掩码:用于屏蔽输入序列中的填充(padding)部分,确保这些位置不影响自注意力的计算。查找掩码:用于解码器中防止未来信息泄露,确保在预测下一个词时只能使用之前的词。
84、Transformer为什么要用Layer norm?作用是什么
答案:层归一化(Layer normalization)可以加速训练并提高稳定性,通过对输入的特征进行归一化,减少了不同初始化和批量数据分布差异带来的影响。
85、Encoder和decoder是如何进行交互的?
答案:交互方式:在解码器中,编码器-解码器注意力层允许解码器的每个位置访问编码器的所有位置的输出。这种机制使解码器能够根据编码器的上下文信息生成输出序列。
进阶篇
注意力
86、Transformer计算attention的时候为何选择点乘而不是加法?两者计算复杂度和效果上有什么区别?
答案:
• 捕捉相关性:点乘能够更好地捕捉查询(Q)和键(K)之间的相关性。点乘可以视为一种元素级别的加权求和,权重由Q和K的对应元素共同决定,这使得模型能够更精确地衡量它们之间的匹配程度。
• 计算效率:虽然点乘和加法在单个元素操作的计算复杂度上相似,但在矩阵运算中,点乘可以利用现代硬件(如GPU)上的并行计算优势,实现高效的大规模运算。
• 可扩展性:点乘天然支持扩展到多头注意力(Multi-Head Attention),这是Transformer架构中的一个重要特性。在多头注意力中,模型并行地执行多个点乘操作,然后将结果合并,以捕获不同子空间的信息。
• 梯度传播:点乘在反向传播中具有更好的梯度传播特性。在深度学习中,梯度的传播对于模型的训练至关重要,点乘操作的梯度计算相对简单,有助于优化算法的稳定性和收敛速度。
• 泛化能力:点乘作为一种通用的操作,可以更容易地泛化到不同的任务和模型架构中。加法虽然简单,但在捕捉复杂模式和关系方面可能不如点乘有效。
87、为什么在进行softmax之前需要对attention进行scaled(为什么除以dk的平方根),并使用公式推导进行讲解
答案:在Transformer模型中,自注意力(Self-Attention)机制的核心是计算一个查询(Query, Q QQ)与所有键(Key, K KK)的点积,然后通过softmax函数进行归一化,得到注意力分布。公式如下:
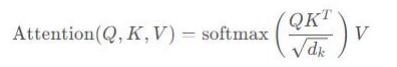
其中,V 是值(Value),dk 是键(Key)的维度。
为什么需要进行缩放(Scaling)?
1.梯度消失/爆炸问题:在深度学习中,当模型很深时,梯度可能会随着层数的增加而变得非常小(梯度消失)或者非常大(梯度爆炸)。在自注意力中,如果不进行缩放,随着dk的增加,QKt的结果可能会变得非常大,导致softmax函数的梯度变得非常小,进而导致梯度消失问题。
2.稳定性:缩放操作提高了模型的稳定性。通过除以除以![]() ,我们确保了即使在dk较大的情况下,softmax函数的输入也不会变得过大,从而使得梯度保持在一个合理的范围内。
,我们确保了即使在dk较大的情况下,softmax函数的输入也不会变得过大,从而使得梯度保持在一个合理的范围内。
3.概率分布:softmax函数的输出是一个概率分布,其值的范围在0到1之间。如果不进行缩放,当d较大时,QKt的值可能会非常大,导致softmax函数的输出值远离0和1,这会使得模型难以学习到有效的注意力分布。
公式推导
假设我们有一个查询Q和一个键K,它们都是维度为dk的向量。我们计算它们的点积:
![]()
在没有缩放的情况下,softmax函数的计算如下:
![]()
其梯度为:
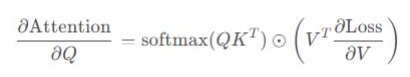
其中, ⊙ 表示Hadamard积(元素乘积),![]() 是损失函数对值V的梯度。
是损失函数对值V的梯度。
当dk较大时, QKt 的值可能会非常大,导致softmax函数的梯度非常小,因为softmax函数的梯度与输入值的差值成反比。因此,我们通过缩放来控制这个差值的大小:
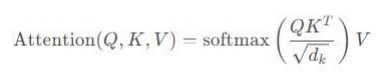
这样,即使 dk较大,![]() 的值也不会过大,从而保持了梯度的稳定性。梯度变为:
的值也不会过大,从而保持了梯度的稳定性。梯度变为:
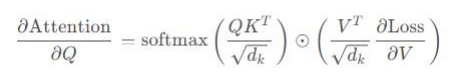
通过这种方式,我们确保了即使在高维情况下,梯度也能保持在一个合理的范围内,从而有助于模型的训练和收敛。
88、在计算attention score的时候如何对padding做mask操作?
答案:
在计算注意力得分时,对padding进行mask操作目的是为了避免模型将注意力集中在填充位置上(因为这些位置不包含实际的有用信息)。具体做法是在计算注意力得分之前,对填充位置对应的得分加上一个非常大的负数(如负无穷),通过softmax后,这些位置的权重接近于零,从而不影响实际有效的序列位置。
注:什么是padding?
在处理自然语言时,输入的序列长度可能不同。为了让所有序列能够在一个批次中进行计算,我们会在较短的序列后面填充特殊的标记,通常是零(0)。这些填充标记就是padding。
注:为什么要对padding做mask操作?
如果不对padding做mask操作,模型可能会误把这些填充位置当作有效信息进行处理,从而影响注意力得分的计算,最终影响模型的性能。因此,需要在注意力计算时忽略这些填充位置。
89、为什么在进行多头注意力的时候需要对每个head进行降维?(可以参考上面一个问题)
答案:在进行多头注意力时,需要对每个头进行降维,以保证每个头的计算复杂度不会过高,同时能够并行计算。将输入的维度分成多个头,可以让每个头处理更小维度的数据,从而降低单头的计算复杂度,减小参数量,提高计算效率。并且通过多个头的组合,增强模型的表达能力和鲁棒性。
详细讲解:
1.降低计算复杂度
假设输入的维度是d,每个头的输出维度也是d。如果不进行降维,每个头的输出维度仍然是d,那么在拼接多个头的输出时,最终的维度将是d * num_heads(num_heads表示头的数量)。这样维度会变得非常大,计算复杂度和内存需求都大大增加。通过对每个头进行降维,每个头的输出维度变为d / num_heads。这样,即使拼接多个头的输出,最终的维度也仍然是d,保持了与输入相同的维度,避免了计算复杂度和内存需求的急剧增长。
2. 保持模型的参数数量可控
模型的参数数量直接影响训练的难度和时间。如果每个头都不进行降维,那么模型的参数数量会大大增加,训练起来会非常困难。而对每个头进行降维,可以控制每个头的参数数量,从而使得整个模型的参数数量保持在一个可控范围内。
3.维持信息的多样性
通过对每个头进行降维,可以确保每个头在一个更小的子空间中进行注意力计算。这意味着每个头可以在不同的子空间中学习到不同的特征,增加了模型的多样性和鲁棒性。最终的拼接结果融合了不同子空间的信息,使得模型能够更全面地理解输入数据。
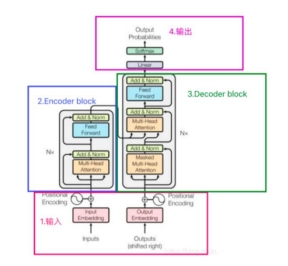
90、大概讲一下Transformer的Encoder模块?
答案:
Transformer的Encoder模块由N层堆叠组成,每层包括两个子层:
1.多头自注意力机制(Multi-Head Self-Attention)
2.前馈神经网络(Feed-Forward Neural Network)
每个子层后都接一个残差连接(Residual Connection)和层归一化(Layer Normalization)。输入首先通过嵌入层(Embedding),然后通过位置编码(Positional Encoding)加上位置信息,再依次经过各层编码器,最终输出编码后的序列表示。
嘿,伙伴们,今天我们的AI探索之旅已经圆满结束。关于“最新版AI大模型面试八股文81-90题”的内容已经分享给大家了。感谢你们的陪伴,希望这次旅程让你对AI能够更了解、更喜欢。谨记,精准提问是解锁AI潜能的钥匙哦!如果有小伙伴想要了解学习更多的AI知识,请关注我们的官网“AI智研社”,保证让你收获满满呦!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 















还没有评论呢,快来抢沙发~