
资源编号
15622最后更新
2025-04-27《LLMsTokenizer篇》电子书下载: 这篇文章详细介绍了不同大语言模型(LLMs)的分词方式及其特点,主要包括Byte-Pair Encoding (BPE)、WordPiece、SentencePiece三种分……
哈喽!伙伴们,我是小智,你们的AI向导。欢迎来到每日的AI学习时间。今天,我们将一起深入AI的奇妙世界,探索“《LLMsTokenizer篇》电子书下载”,并学会本篇文章中所讲的全部知识点。还是那句话“不必远征未知,只需唤醒你的潜能!”跟着小智的步伐,我们终将学有所成,学以致用,并发现自身的更多可能性。话不多说,现在就让我们开始这场激发潜能的AI学习之旅吧。

《LLMsTokenizer篇》电子书下载:
这篇文章详细介绍了不同大语言模型(LLMs)的分词方式及其特点,主要包括Byte-Pair Encoding (BPE)、WordPiece、SentencePiece三种分词算法,并对比了不同模型的分词效果和处理时间。
主要内容
Byte-Pair Encoding (BPE)
构建词典步骤:
准备足够的训练语料和期望的词表大小。
将单词拆分为字符粒度,并在末尾添加后缀“”,统计单词频率。
统计每一个连续/相邻字节对的出现频率,将最高频的连续字节对合并为新的子词。
重复上述步骤,直到词表达到设定的词表大小,或下一个最高频字节对出现频率为1。
应用模型:GPT2、BART和LLaMA采用了BPE。
WordPiece
与BPE的异同点:
本质上还是BPE的思想。
最大区别在于合并子词的方式:BPE选择频次最大的相邻子词合并,而WordPiece选择能够提升语言模型概率最大的相邻子词进行合并。
应用模型:BERT采用了WordPiece。
SentencePiece
思路介绍:
把空格也当作一种特殊字符来处理,再用BPE或WordPiece来构造词汇表。
应用模型:ChatGLM、BLOOM、PaLM采用了SentencePiece。
不同大模型的分词方式及对比
分词结果示例
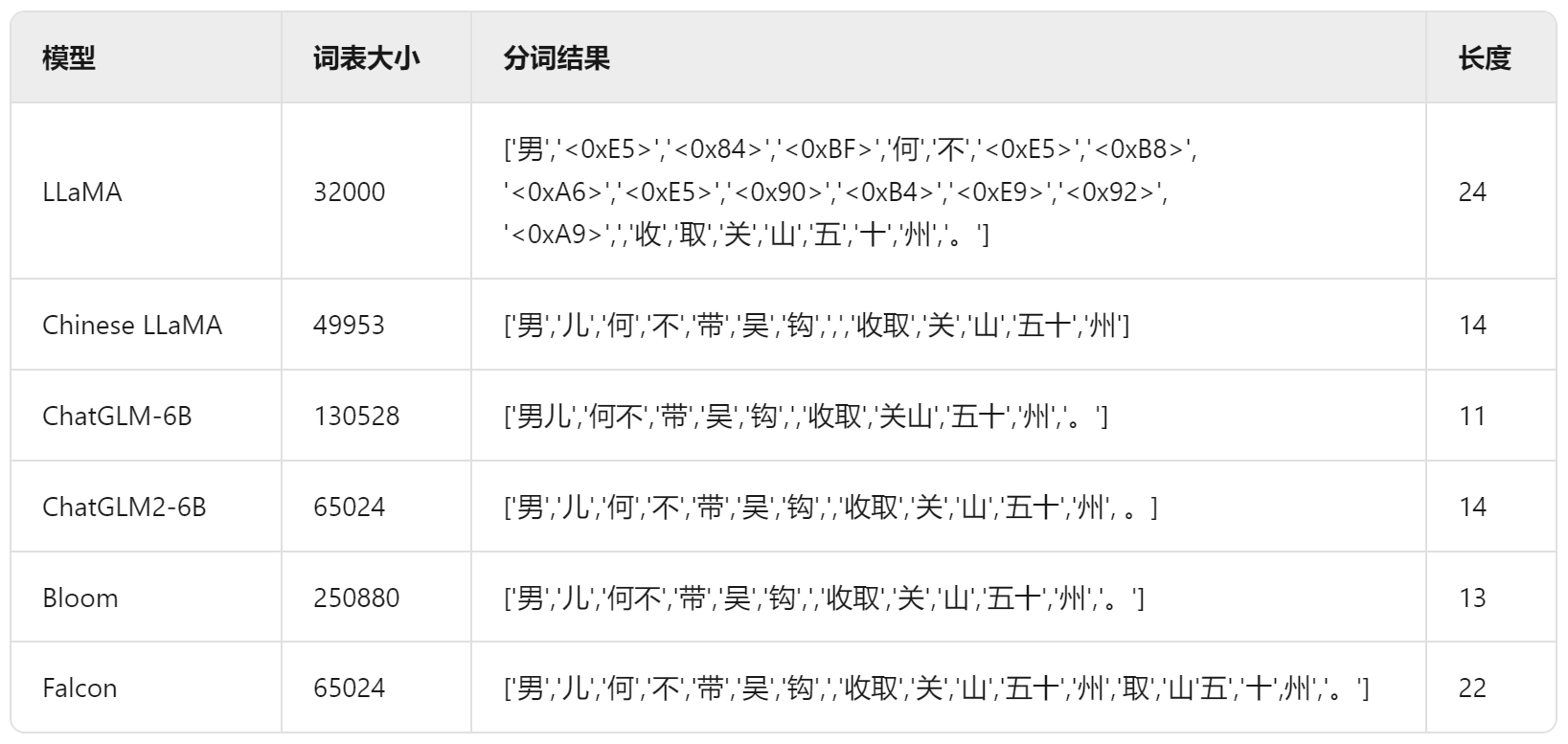
分词方式的区别
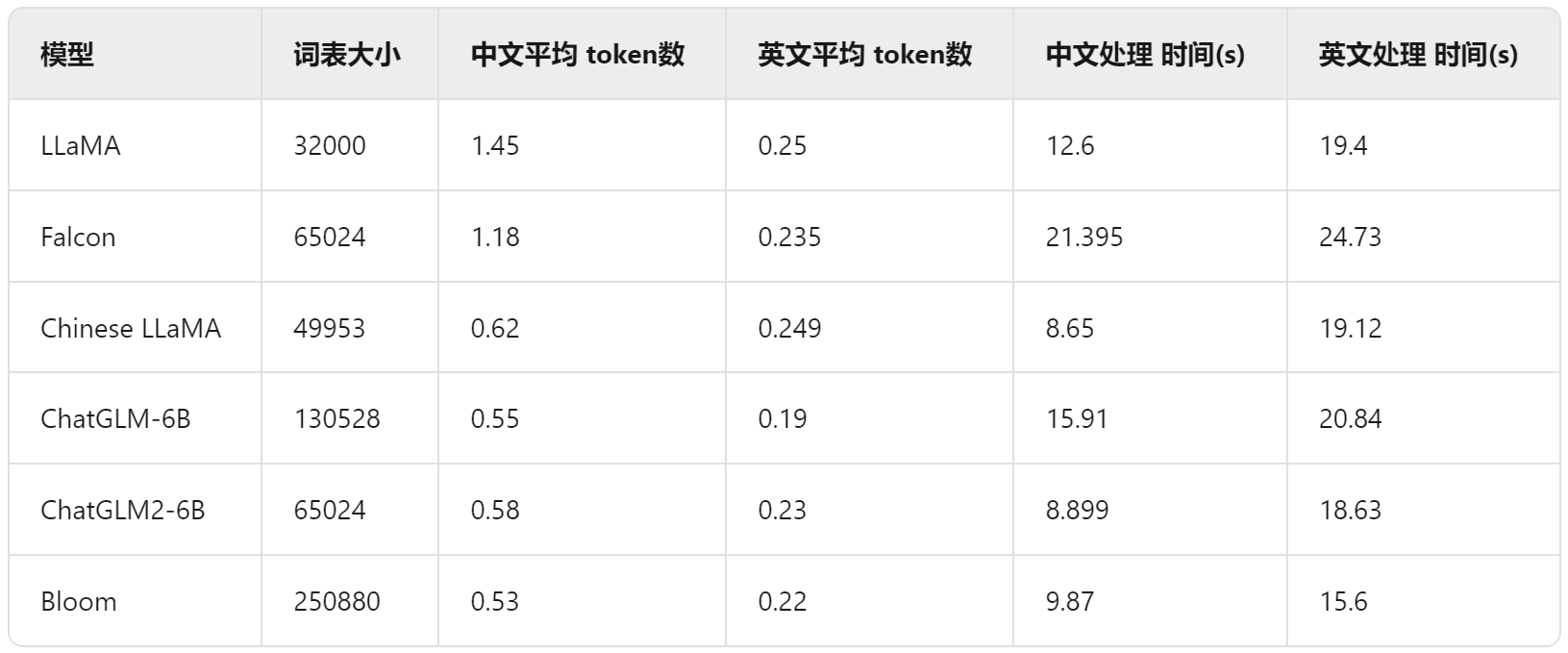
• LLaMA:词表最小,中英文上的平均token数最多,分词较细粒度,尤其在中文上平均token数高达1.45。
• Chinese LLaMA:扩展词表后,中文平均token数显著降低,提高了中文编码效率。
• ChatGLM-6B:平衡中英文分词效果最好的tokenizer,但由于词表较大,中文处理时间也增加。
• BLOOM:词表最大,但由于是多语种的,在中英文上分词效率与ChatGLM-6B基本相当。
这篇文章详细介绍了LLMs的分词方式及其特点,重点对比了BPE、WordPiece和SentencePiece三种算法,并通过具体模型实例展示了不同分词方式的效果和处理时间。
嘿,伙伴们,今天我们的AI探索之旅已经圆满结束。关于“《LLMsTokenizer篇》电子书下载”的内容已经分享给大家了。感谢你们的陪伴,希望这次旅程让你对AI能够更了解、更喜欢。谨记,精准提问是解锁AI潜能的钥匙哦!如果有小伙伴想要了解学习更多的AI知识,请关注我们的官网“AI智研社”,保证让你收获满满呦!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 













还没有评论呢,快来抢沙发~