
资源编号
14672最后更新
2025-04-21《强化学习在自然语言处理下的应用篇》电子书下载: 这篇论文主要介绍了强化学习在自然语言处理中的应用基础及其发展路径,特别是到PPO算法之前的相关理论和概念。以下……
哈喽!伙伴们,我是小智,你们的AI向导。欢迎来到每日的AI学习时间。今天,我们将一起深入AI的奇妙世界,探索“《强化学习在自然语言处理下的应用篇》电子书下载”,并学会本篇文章中所讲的全部知识点。还是那句话“不必远征未知,只需唤醒你的潜能!”跟着小智的步伐,我们终将学有所成,学以致用,并发现自身的更多可能性。话不多说,现在就让我们开始这场激发潜能的AI学习之旅吧。

《强化学习在自然语言处理下的应用篇》电子书下载:
这篇论文主要介绍了强化学习在自然语言处理中的应用基础及其发展路径,特别是到PPO算法之前的相关理论和概念。以下是论文的主要内容摘要:
强化学习(Reinforcement Learning, RL)是一种时序决策学习框架,通过智能体与环境的交互来优化策略,使其能够在环境中自主学习。本文旨在介绍强化学习的基础知识和其在自然语言处理中的应用。
核心内容
1. 强化学习基础知识
1.1 强化学习定义
强化学习是一种时序决策学习框架,通过智能体与环境的交互来优化策略,使其能够在环境中自主学习。智能体根据当前状态选择动作,并从环境中获得奖励,以此来优化策略。
1.2 状态和观测
状态(States):对世界状态的完整描述。
观测(Observations):对状态的部分描述,可能会缺失一些信息。当观测等于状态时,称为完美信息;否则为非完美信息。
1.3 动作空间
离散动作空间:智能体只能采取有限的动作,如下棋或文本生成。
连续动作空间:智能体的动作是实数向量,如机械臂转动角度。动作空间的类型影响策略网络的实现方式。
1.4 Policy策略
确定性策略(Deterministic Policy):在连续动作空间中使用,策略直接输出动作。
随机性策略(Stochastic Policy):在离散动作空间中使用,策略输出动作的概率分布。
1.5 轨迹
轨迹:状态和行动的序列,表示为
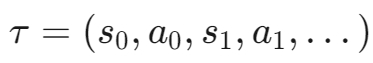
状态转换函数:描述状态如何根据当前状态和动作变化。
初始状态:从初始状态分布中采样。
1.6 奖赏函数
奖赏函数:用于评估智能体的行为,可以是基于状态、动作或状态转移的。
目标:最大化行动轨迹的累计奖励。
1.7 强化学习问题
核心问题:选择一种策略以最大化预期收益。
优化问题:找到最优策略。
2. RL发展路径(至PPO)
2.1 Value-based优化方法
Value-based:通过状态的值函数 V(s) 或状态-动作对的值函数 Q(s,a) 来估计累积奖赏,从而优化策略。
最优值函数:最大化策略下的预期收益。
最优动作-值函数:用于选择最优动作。
2.2 贝尔曼方程
中心思想:当前值估计等于当前奖赏加上未来值估计。
公式:用于计算值函数和动作-值函数的更新。
2.3 优势函数
定义:用于衡量一个动作相对于其他动作的优势。
公式:
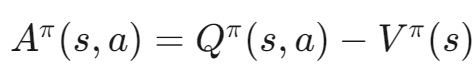
本文详细介绍了强化学习的基础知识和其在自然语言处理中的应用。通过对状态、观测、动作空间、Policy策略、轨迹、奖赏函数和强化学习问题的介绍,读者可以更好地理解强化学习的基本概念。此外,本文还探讨了强化学习的发展路径,特别是Value-based优化方法、贝尔曼方程和优势函数的应用。这些理论和概念为进一步研究和应用强化学习提供了坚实的基础。
嘿,伙伴们,今天我们的AI探索之旅已经圆满结束。关于“《强化学习在自然语言处理下的应用篇》电子书下载”的内容已经分享给大家了。感谢你们的陪伴,希望这次旅程让你对AI能够更了解、更喜欢。谨记,精准提问是解锁AI潜能的钥匙哦!如果有小伙伴想要了解学习更多的AI知识,请关注我们的官网“AI智研社”,保证让你收获满满呦!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 














还没有评论呢,快来抢沙发~