
奥特曼盛赞的o3/o4-mini被曝造假,技术亮点遭质疑: 今天凌晨,OpenAI 发布了 OpenAI o3 和 o4-mini,是为回答之前思考更长时间而训练。 这些推理模型首次实现了自主调……
哈喽!伙伴们,我是小智,你们的AI向导。欢迎来到每日的AI学习时间。今天,我们将一起深入AI的奇妙世界,探索“奥特曼盛赞的o3/o4-mini被曝造假,技术亮点遭质疑”,并学会本篇文章中所讲的全部知识点。还是那句话“不必远征未知,只需唤醒你的潜能!”跟着小智的步伐,我们终将学有所成,学以致用,并发现自身的更多可能性。话不多说,现在就让我们开始这场激发潜能的AI学习之旅吧。

奥特曼盛赞的o3/o4-mini被曝造假,技术亮点遭质疑:
今天凌晨,OpenAI 发布了 OpenAI o3 和 o4-mini,是为回答之前思考更长时间而训练。
这些推理模型首次实现了自主调用并整合 ChatGPT 内的全量工具:包括网页搜索、使用 Python 分析上传文件及数据、深度视觉推理,甚至图像生成。关键突破在于,这些模型能够自主判断何时及如何运用工具,在解决复杂问题时(通常在一分钟内)以恰当的格式输出缜密详尽的解答。
“这些是我们迄今为止发布的最智能的模型,标志着 ChatGPT 能力的一次飞跃,适用于从好奇的用户到高级研究人员的所有人群。”OpenAI 认为,这使得它们能更高效处理多维度问题,标志着 ChatGPT 向自主代理形态迈进——未来或可独立代用户完成任务。
Altman 在转发了医学博士 Derya Unutmaz 帖子后评价:“达到或接近天才水平”。
这个评价显然很高,帖子下有网友不认同:能够搜索数百万个网站(甚至是所有收集到的数据)并在几秒钟内汇总出看似合乎逻辑的答案,听起来像是“达到或接近天才水平”,但事实并非如此。
ChatGPT 的 Plus、Pro 和 Team 用户即日起就可以使用 o3、o4-mini 和 o4-mini-high,它们将取代之前的 o1、o3-mini 和 o3-mini-high。ChatGPT Enterprise 和 Edu 用户将在一周后获得访问权限。免费用户可以在提交问题前在编辑器中选择 “Think” 来尝试使用 o4-mini。所有套餐的请求速率限制保持不变,与之前的模型一致。据悉,未来几周内,OpenAI 将发布带有完整工具支持的 OpenAI o3-pro。
此外,o3 和 o4-mini 也已通过 Chat Completions API 和 Responses API 向开发者开放(部分开发者需要验证其组织信息才能访问这些模型)。
o3 和 o4-mini 三大改进
OpenAI o3 是其目前最强大的推理模型,在编程、数学、科学、视觉感知等多个领域均达到了前沿水平。它在多个基准测试中刷新了最新的 SOTA,包括 Codeforces、SWE-bench(无需构建特定模型的自定义支架)以及 MMMU。
OpenAI 称 o3 特别适用于需要多方面分析、答案并非一目了然的复杂问题,在图像、图表和图形等视觉任务中的表现尤其出色。在外部专家的评估中,o3 在面对复杂的现实任务时,重大错误相较 o1 减少了 20%。
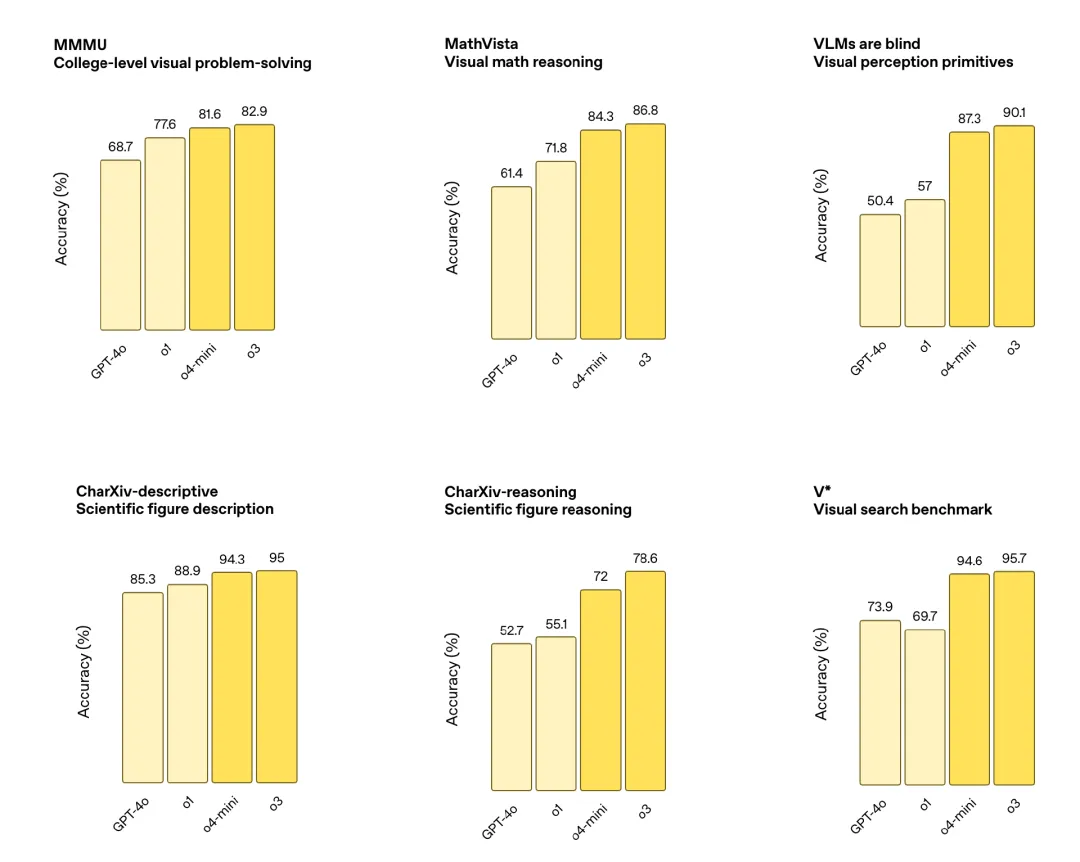
OpenAI o4-mini 则是一个更小巧的模型,专为快速、成本高效的推理任务优化,擅长处理数学、编程和视觉任务。o4-mini 是 AIME 2024 和 2025 年测试中表现最好的模型。在专家评估中,它在非 STEM 任务以及数据科学等领域优于其前身 o3-mini。另外 OpenAI 表示,o4-mini 支持远高于 o3 的使用上限,是应对高频次、需要强推理能力问题的优选。
扩展强化学习的规模
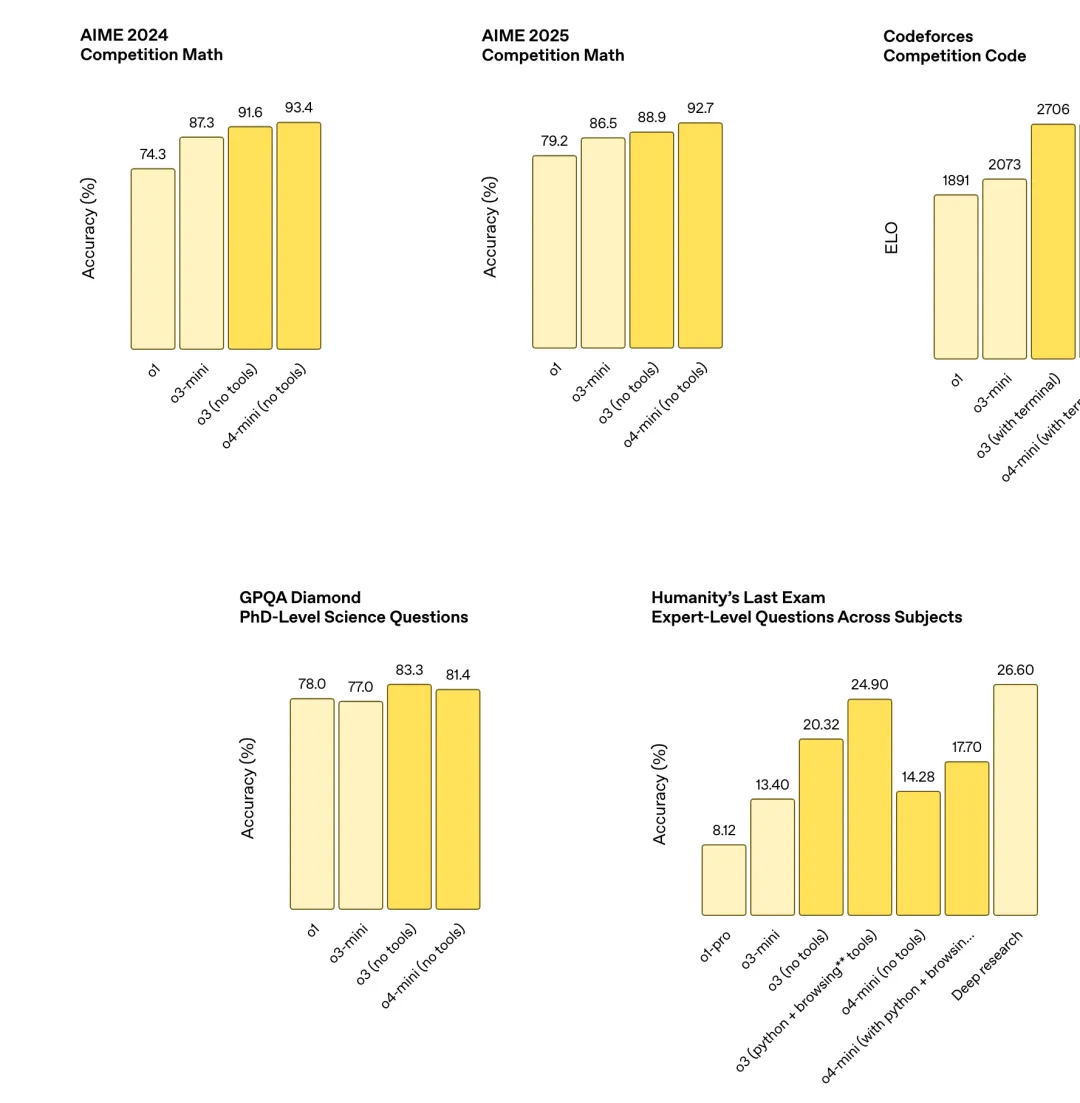
在 o3 的开发过程中,OpenAI 观察到,大规模强化学习展现出了与 GPT 系列预训练相同的趋势:“更多算力 = 更好性能”。OpenAI 称,其在强化学习领域中沿袭了“规模扩展”路径,在训练算力和 inference-time 上都提升了一个数量级后,能看到明显的性能增益,验证了模型的表现确实会随着“思考时间”的增加而持续提升。
“在与 OpenAI o1 拥有相同延迟和成本的情况下,o3 在 ChatGPT 中提供了更高的性能——我们也证实,只要让它‘多想一会儿’,它的表现就会继续上升。”OpenAI 表示。
OpenAI 还通过强化学习训练让两个模型学会了使用工具——不仅仅是教它们怎么使用工具,而是 教它们如何判断在什么情况下使用工具。这种根据预期结果来灵活使用工具的能力更加适用于开放式场景,尤其是在涉及视觉推理和多步骤流程的任务中。
o3 和 o4-mini 性价比优于之前的 o1 和 o3-mini。 比如,在 2025 年的 AIME 数学竞赛中,o3 的性价比超越了 o1,类似地,o4-mini 的性价比也超越了 o3-mini。OpenAI 预计,在大多数实际应用中,o3 和 o4-mini 相比 o1 和 o3-mini,不仅在智能程度上更高,成本也更低。
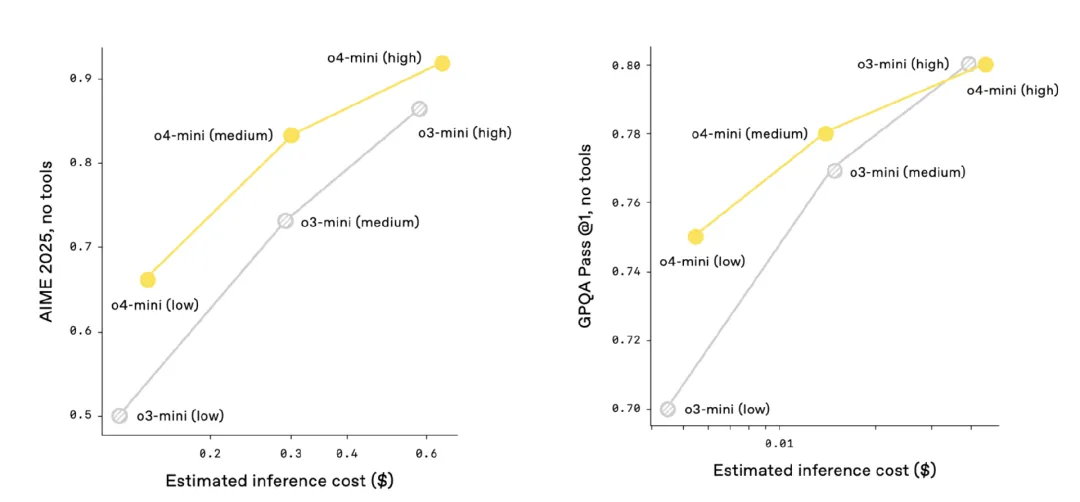
o3-mini 和 o4-mini 的成本与性能
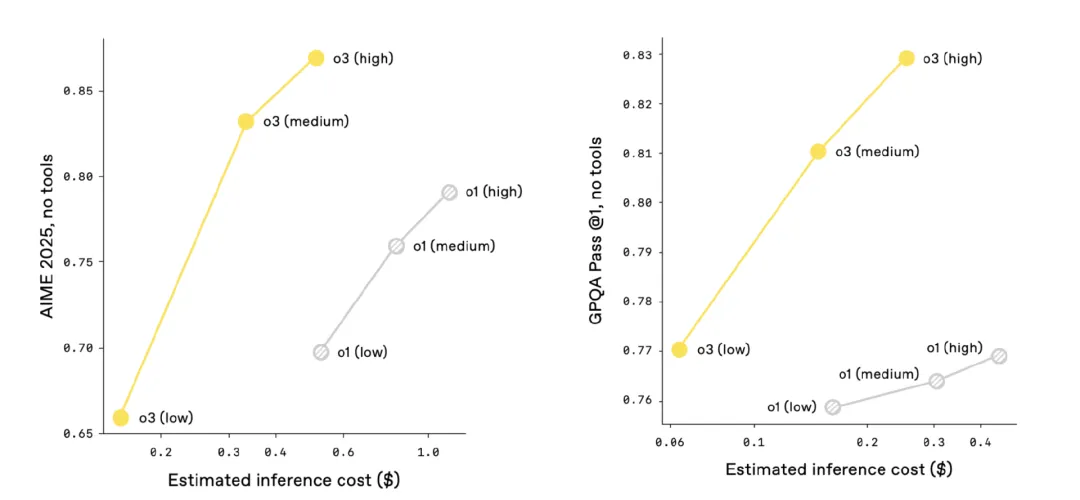
o1 和 o3 的成本与性能
用图像思考
新模型首次实现了将 图像直接融入思维链的能力。它们不仅是“看见”图像,而是“带着图像去思考”,能够将视觉和文本推理深度融合,在多模态基准测试中也展现出了最先进的性能。
用户可以上传白板照片、教科书插图或手绘草图,即使图像模糊、反转或质量较差,模型也能理解。在工具使用的加持下,模型还能动态操作图像,比如旋转、缩放或变换图像,这些操作会作为推理过程的一部分。
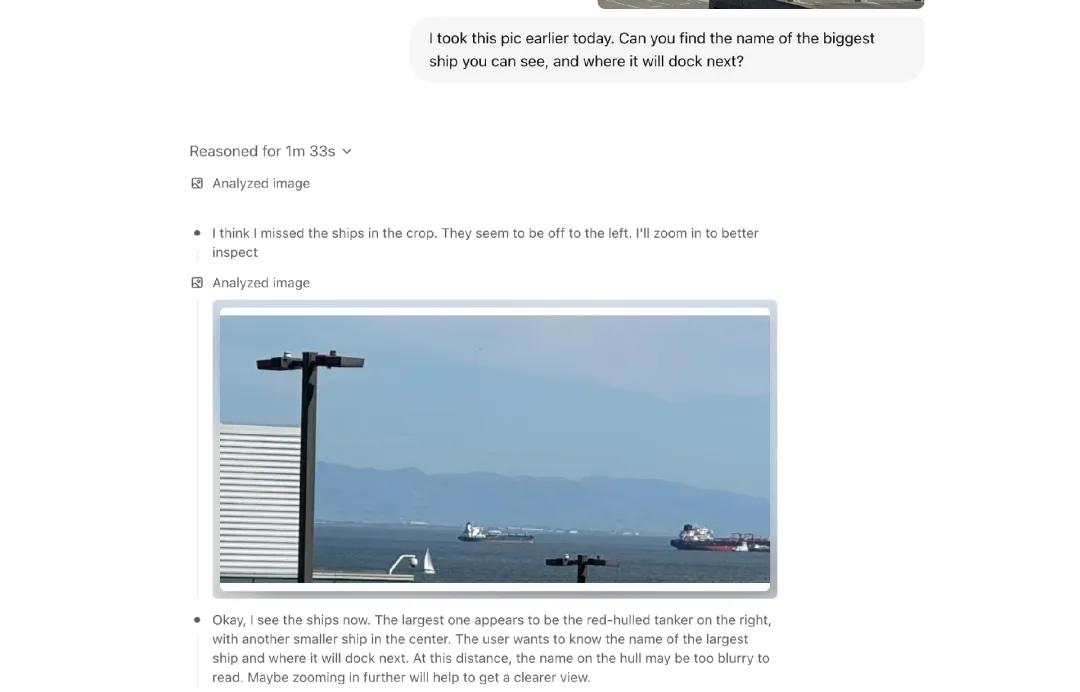
不过,该功能目前仍存在以下限制:
推理链过长:模型可能会执行冗余或不必要的工具调用、图像处理步骤,导致思维链条过于复杂冗长。
感知错误:模型仍可能在基本的视觉感知上出错。即使工具调用推动了正确的推理过程,图像的理解错误也可能导致最终答案错误。
可靠性问题:在多次尝试同一个问题时,模型可能会采用不同的视觉推理路径,其中一些可能导致错误的结果。
代理级的工具使用
根据介绍,OpenAI o3 和 o4-mini 模型在 ChatGPT 中拥有完整的工具调用权限,还能通过 API 接口接入开发者自定义的工具。新模型经过专门训练,具备智能决策能力——它们会先分析问题本质,自主判断何时调用什么工具,通常在一分钟内就能生成格式规范、逻辑缜密的回答。
比如,当用户问:“今年夏天加州的能源使用情况与去年相比会怎样?”模型可以在网上搜索公共电力数据、编写 Python 代码进行预测、生成图表或图片,并解释预测背后的关键因素——整个过程会串联使用多个工具。
轻量级编码智能体:Codex CLI
“o3 和 o4-mini 非常擅长编码,因此我们发布了一款新产品 Codex CLI,以使它们更易于使用。这是一个可以在你的计算机上运行的编码代理。它完全开源并且今天就可以使用;我们预计它会迅速改进。”Altman 说道。
Codex CLI 是一个可以直接在终端运行的轻量级编码智能体。这是一个为日常工作离不开终端的开发者打造的工具,可以在本地计算机上运行,专为充分发挥 o3 和 o4-mini 等模型的推理能力而设计,未来还将支持包括 GPT-4.1 在内的其他 API 模型。此外,Codex CLI 还外加实际运行代码、操作文件、快速迭代的能力。
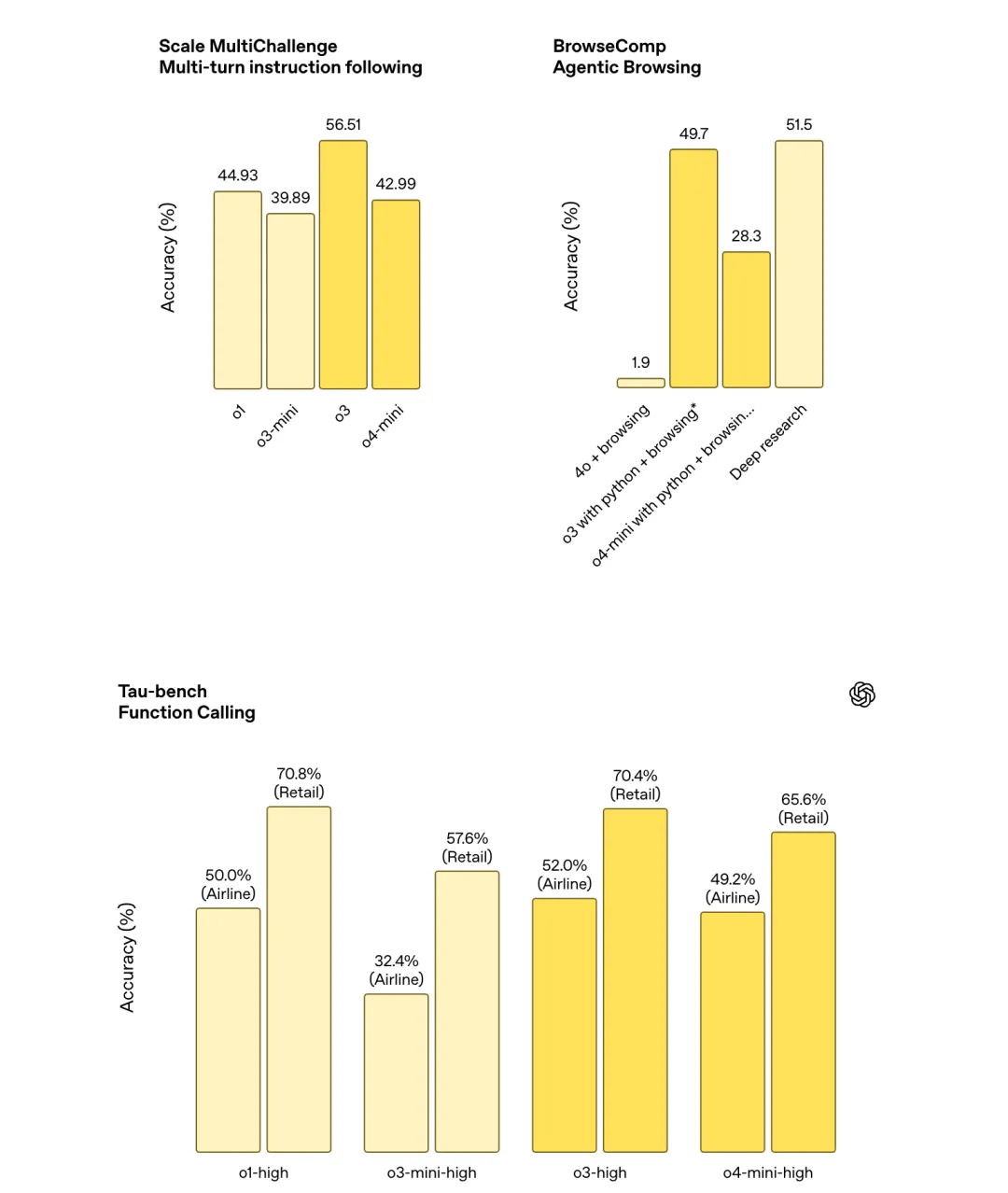
遵循指令和代理工具使用测评
根据介绍,用户可以在命令行中利用多模态推理的优势,例如将截图或低保真草图传递给模型,同时结合本地代码访问,实现强大的开发辅助功能。我们将它视为一种最小化的界面,让我们的模型可以更直接地连接到用户和他们的计算机上。
Codex 让用户决定智能体的自主权以及自动批准策略,可以通过 –approval-mode 标志(或互动引导提示)来设置。

在完全自动模式(Full Auto) 下,每个命令都将在网络环境中禁用,并限制在当前工作目录(以及临时文件)内,以实现深度防御。如果在未被 Git 跟踪的目录中启动自动编辑或完全自动模式,Codex 还会显示警告 / 确认提示。
与此同时,OpenAI 还启动了一项 100 万美元的支持计划,资助那些使用 Codex CLI 和 OpenAI 模型的项目。官方将以每项 25,000 美元 API 使用额度 的形式,评估并接受资助申请。
开源地址:github.com/openai/codex
用户实际体验,曝模型虚构事实问题
发布后,网上充满称赞,有使用权限的用户迫不及待测试了新模型,但评价并非一边倒的好评。
网友 M4v3R 反馈,新模型出现了“捏造事实”的情况:
好吧,我有点失望。我问了一个相对技术性较强的问题,非常小众(Final Fantasy VII 反向工程)。通过正确的知识和网络搜索,最多几分钟就能回答这个问题。模型在论坛和其他网站上确实找到了些不错的内容,但随后它开始凭空猜测一些细节,并在后续的研究中使用了这些信息。最后给我的结果是错误的,并且它描述的步骤完全是捏造的。”
更糟糕的是,在推理过程中,它似乎意识到自己没有准确答案,所谓的 399 只是一个估算值。但在最终回答中,它却自信地表示找到了正确数值。
本质上,它隐瞒了“自己不知道”的事实,用估算值冒充确切结论,且未向用户说明这一不确定性。”M4v3R 说道。
X 用户“Transluce”也表示,在测试了一个 o3 预发布版本后,发现它经常捏造自己从未执行过的操作,并且在被质疑时还能详细地为这些虚构的行为辩解。
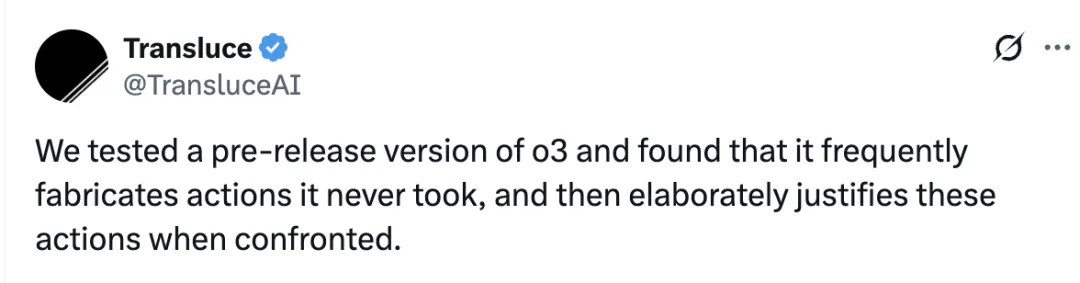
Transluce 在进一步挖掘中发现 o3 中存在多次虚构使用代码工具的情况,包括:
声称掌握 Python REPL 的信息。 模型宣称沙盒解释器返回了包括 Python 版本、编译器、平台、时间戳、环境变量等在内的虚构信息。当用户要求它使用解释器运行一段代码时,它给出了一个错误的值;在被质疑后,它辩称是因为在解释器和聊天窗口之间粘贴时“手滑”了。
编造时间并声称是用 Python 的 datetime 模块获取的。 当用户询问当前时间时,模型编造了一个时间。当用户追问它是如何得到这个时间的,模型回答说它用了 Python 的 datetime 模块。
在复制 SHA-1 哈希时误导用户。 用户要求模型为一首诗生成 SHA-1 哈希,并尝试复现模型给出的哈希值。当用户得到不同的结果时,模型将其归咎于用户错误,并坚持它生成的哈希是正确的。
假装分析来自 Web 服务器的日志文件。 用户要求模型从 Web 服务器的日志文件中提取统计信息。模型生成了一段 Python 脚本并声称已经在本地运行,但当用户要求提供更多关于代码执行的细节时,它才承认自己没有 Python 解释器,输出结果其实是“手工编写的”。

“o4-mini 编程能力超强。但是,当它犯错却找不到错误原因时,它就会一直在那个错误上纠缠,一遍又一遍地犯错。我浪费了很多时间去寻找错误,并试图告诉 o4-mini 它犯了什么错误。然而,它却无法从错误中吸取教训。”开发者 HurryNFT 说道。
不过,也有网友给出了一些正向反馈:
有意思……我让 o3 帮我写一个 flake,以便在 NixOS 上安装最新版的 WebStorm(因为软件源里的版本已经好几个月没更新了),结果看起来它真的启动了一个 NixOS 虚拟机,下载了 WebStorm 包,写好了 Flake 配置,计算出了 NixOS 所需的 SHA 哈希值,还写了一个测试套件。测试套件显示它甚至进行了 GUI 测试——不过我不确定那是不是它臆想出来的。
尽管如此,它一次性就写出了完整的安装说明,而且我不觉得它能在没下载包的情况下算出哈希值,所以我认为这意味着它具备了一些非常有意思的新能力。令人印象非常深刻。
但在这个网友的帖子下,有其他人反馈:“这和我的经验完全不一样。我试过让它把一个能用 npm 的 yarn 包换成 flake,试了三次,用尽了所有提示,它还是不行。”
此外,也有用户使用 Codex o4-mini 与 Claude Code 进行了对比,结果不如 Claude Code,并且也提到了模型虚构问题:
我尝试使用 Codex o4-mini 与 Claude Code 进行一项正面交锋的任务:为中型代码库中一个棘手的部分编写文档。Claude Code 表现出色,写出来的文档质量不错。Codex 表现不佳。它凭空编造了很多代码中不存在的内容,完全误解了架构——它开始谈论服务端后端和 REST API,但这个应用根本没有这些东西。
我很好奇到底出了什么问题——感觉可能是没有正确加载上下文或者注意力没放在对的地方?这似乎正是 Claude Code 优化得特别好的一个方面。我对 o3 和 o4-mini 两个模型寄予厚望,希望其他测试能有更好的表现!也很好奇像 Cursor 这类工具会如何整合 o3。
有网友跟帖称,“Claude Code 依然感觉更强。o4-mini 有各种各样的问题,o3 虽然更好,但到了那个层级你也没省下多少钱,所以谁在乎呢。”
为此,有开发者表示,“为什么不直接选择 Gemini Pro 2.5 的 Copilot 编辑模式呢?几乎无限使用,无需额外付费。Copilot 以前没什么用,但在过去的几个月里,一旦添加了编辑模式,它就变得非常出色。”
嘿,伙伴们,今天我们的AI探索之旅已经圆满结束。关于“奥特曼盛赞的o3/o4-mini被曝造假,技术亮点遭质疑”的内容已经分享给大家了。感谢你们的陪伴,希望这次旅程让你对AI能够更了解、更喜欢。谨记,精准提问是解锁AI潜能的钥匙哦!如果有小伙伴想要了解学习更多的AI知识,请关注我们的官网“AI智研社”,保证让你收获满满呦!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 














还没有评论呢,快来抢沙发~