
资源编号
13855最后更新
2025-04-16《基于lora的llama2二次预训练》电子书下载: 这篇文章介绍了基于LoRA(Low-Rank Adaptation)的Llama2模型的二次预训练方法,旨在增强模型对中文的支持能力。 研究背景……
哈喽!伙伴们,我是小智,你们的AI向导。欢迎来到每日的AI学习时间。今天,我们将一起深入AI的奇妙世界,探索“《基于lora的llama2二次预训练》电子书下载”,并学会本篇文章中所讲的全部知识点。还是那句话“不必远征未知,只需唤醒你的潜能!”跟着小智的步伐,我们终将学有所成,学以致用,并发现自身的更多可能性。话不多说,现在就让我们开始这场激发潜能的AI学习之旅吧。

《基于lora的llama2二次预训练》电子书下载:
这篇文章介绍了基于LoRA(Low-Rank Adaptation)的Llama2模型的二次预训练方法,旨在增强模型对中文的支持能力。
研究背景
背景介绍:
这篇文章的研究背景是为了增强Llama2模型对中文的支持能力。通过在中文语料上进行二次预训练,使得模型能够更好地理解和生成中文文本。
研究内容:
该问题的研究内容包括:基于LoRA的Llama2二次预训练,目标是通过在中文语料上进行微调,实现高效的大模型微调。
文献综述:
该问题的相关工作主要集中在大模型的微调方法上,特别是LoRA技术在大模型微调中的应用。LoRA通过低秩适应的方式,实现对模型的高效微调。
研究方法
这篇论文提出了基于LoRA的Llama2二次预训练方法。具体来说,
LoRA技术:
LoRA假设模型在任务适配过程中权重的改变量是低秩的,通过添加额外的网络层并仅训练这些新增的网络层参数,实现高效微调。公式如下:
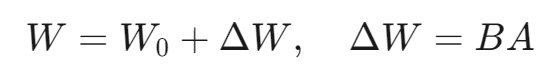
其中,W0是原始模型的权重,ΔW是低秩更新量,B和A是低秩矩阵。
二次预训练:
在保持预训练模型权重不变的情况下,通过添加额外的网络层并仅训练这些新增的网络层参数,实现大模型的高效微调。
实验设计
数据收集:
数据集主要来自中文书籍,包括《尚书》、《诗经》、《红楼梦》等多部经典中文文学作品。数据集格式为.txt文件。
实验步骤:
预训练: 使用中文书籍数据集进行二次预训练,目标是增强模型对中文的支持能力。
微调: 使用Stanford Alpaca项目生成的中文指令数据进行微调,以提高模型的指令遵循能力。
参数配置:
学习率:2e−4
LoRA低秩矩阵的维数:64
LoRA低秩矩阵的缩放系数:28
可训练的LORA模块:q_proj,v_proj,k_proj,o_proj,gate_proj,down_proj,up_proj
LoRA层的丢弃率:0.05
结果与分析
预训练效果:
通过二次预训练,模型在中文文本生成任务上表现出色,能够生成连贯且准确的中文文本。
微调效果:
微调后的模型在指令遵循任务上表现良好,能够准确理解并执行中文指令。
这篇论文通过基于LoRA的Llama2二次预训练方法,成功增强了模型对中文的支持能力。实验结果表明,该方法在中文文本生成和指令遵循任务上均表现出色。该方法为后续的中文大模型微调提供了有效的参考。
这篇论文展示了LoRA技术在中文大模型微调中的有效应用,具有较高的实用价值。
嘿,伙伴们,今天我们的AI探索之旅已经圆满结束。关于“《基于lora的llama2二次预训练》电子书下载”的内容已经分享给大家了。感谢你们的陪伴,希望这次旅程让你对AI能够更了解、更喜欢。谨记,精准提问是解锁AI潜能的钥匙哦!如果有小伙伴想要了解学习更多的AI知识,请关注我们的官网“AI智研社”,保证让你收获满满呦!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 













还没有评论呢,快来抢沙发~