
通义千问Qwen2.5-VL详解之精准的视觉定位: 精准的视觉定位 Qwen2.5-VL 采用矩形框和点的多样化方式对通用物体定位, 可以实现层级化定位和规范的 JSON 格式输出。 增……
哈喽!伙伴们,我是小智,你们的AI向导。欢迎来到每日的AI学习时间。今天,我们将一起深入AI的奇妙世界,探索“通义千问Qwen2.5-VL详解之精准的视觉定位”,并学会本篇文章中所讲的全部知识点。还是那句话“不必远征未知,只需唤醒你的潜能!”跟着小智的步伐,我们终将学有所成,学以致用,并发现自身的更多可能性。话不多说,现在就让我们开始这场激发潜能的AI学习之旅吧。

通义千问Qwen2.5-VL详解之精准的视觉定位:
精准的视觉定位
Qwen2.5-VL 采用矩形框和点的多样化方式对通用物体定位, 可以实现层级化定位和规范的 JSON 格式输出。 增强的定位能力为复杂场景中的视觉 Agent 进行理解和推理任务提供了基础。


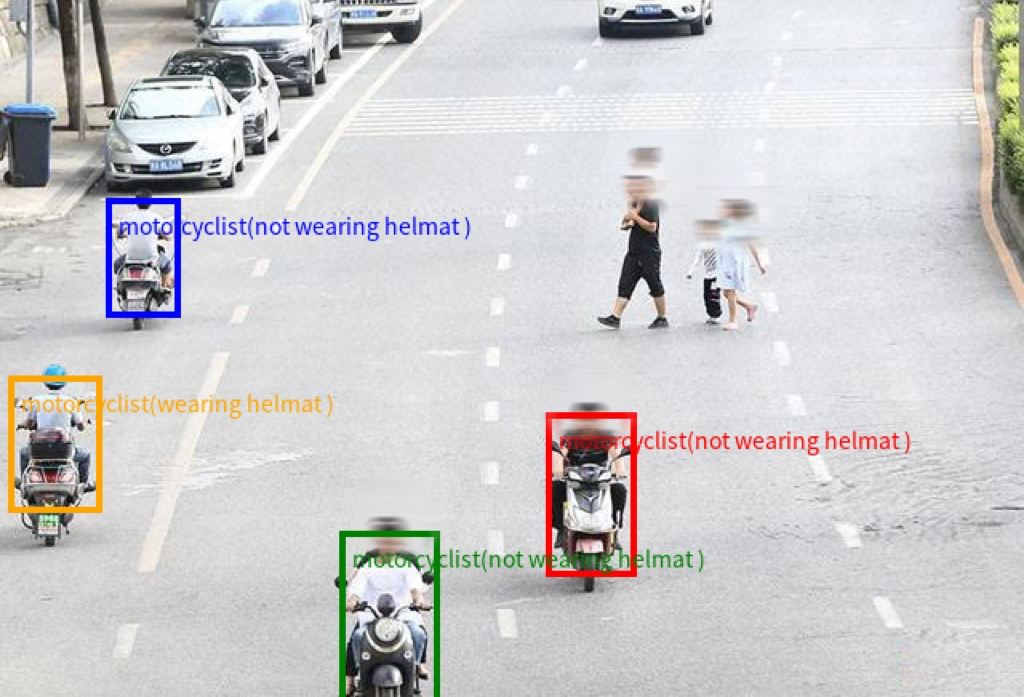
Prompt: Detect all motorcyclists in the image and return their locations in the form of coordinates. The format of output should be like {“bbox_2d”: [x1, y1, x2, y2], “label”: “motorcyclist”, “sub_label”: “wearing helmat” # or “not wearing helmat”}.
嘿,伙伴们,今天我们的AI探索之旅已经圆满结束。关于“通义千问Qwen2.5-VL详解之精准的视觉定位”的内容已经分享给大家了。感谢你们的陪伴,希望这次旅程让你对AI能够更了解、更喜欢。谨记,精准提问是解锁AI潜能的钥匙哦!如果有小伙伴想要了解学习更多的AI知识,请关注我们的官网“AI智研社”,保证让你收获满满呦!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 















还没有评论呢,快来抢沙发~