
通义千问Qwen2.5-Max详解: Qwen2.5-Max 通义千问旗舰版模型Qwen2.5-Max全新升级发布。Qwen2.5-Max比肩Claude-3.5-Sonnet,并几乎全面超越了GPT-4o、DeepSeek-V3及Llam……
哈喽!伙伴们,我是小智,你们的AI向导。欢迎来到每日的AI学习时间。今天,我们将一起深入AI的奇妙世界,探索“通义千问Qwen2.5-Max详解”,并学会本篇文章中所讲的全部知识点。还是那句话“不必远征未知,只需唤醒你的潜能!”跟着小智的步伐,我们终将学有所成,学以致用,并发现自身的更多可能性。话不多说,现在就让我们开始这场激发潜能的AI学习之旅吧。

通义千问Qwen2.5-Max详解:
Qwen2.5-Max
通义千问旗舰版模型Qwen2.5-Max全新升级发布。Qwen2.5-Max比肩Claude-3.5-Sonnet,并几乎全面超越了GPT-4o、DeepSeek-V3及Llama-3.1-405B。
Qwen2.5-Max模型是阿里云通义团队对MoE模型的最新探索成果,预训练数据超过20万亿tokens。新模型展现出极强劲的综合性能,在多项公开主流模型评测基准上录得高分,全面超越了目前全球领先的开源MoE模型以及最大的开源稠密模型。
目前,开发者可在Qwen Chat(https://chat.qwenlm.ai/)平台免费体验模型,企业和机构也可通过阿里云百炼平台直接调用新模型API服务。
模型性能全球领先
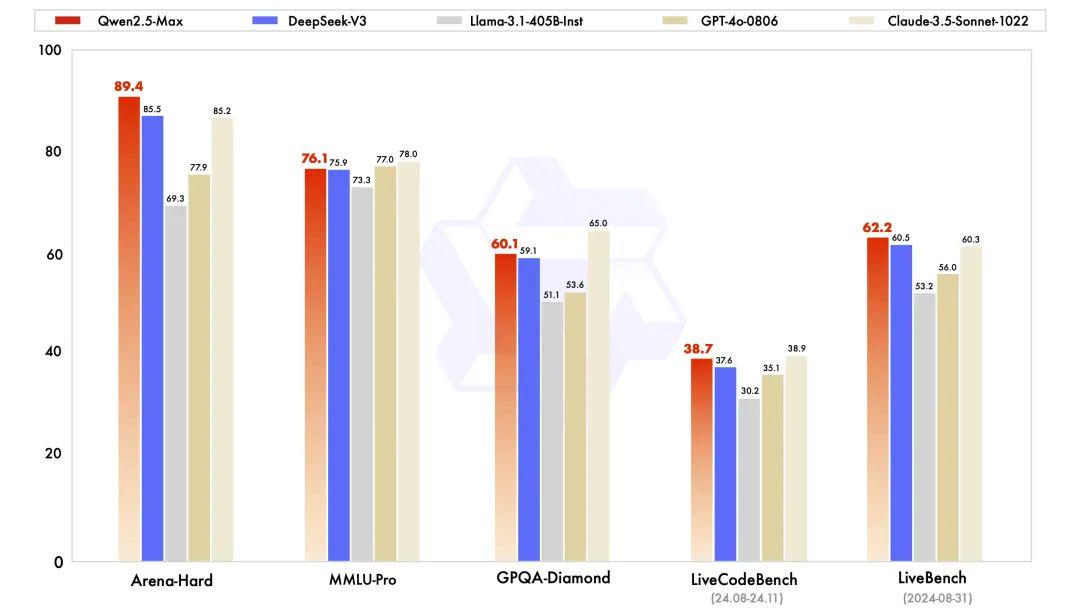
Qwen2.5-Max在知识(测试大学水平知识的MMLU-Pro)、编程(LiveCodeBench)、全面评估综合能力的(LiveBench)以及人类偏好对齐(Arena-Hard)等主流权威基准测试上,展现出全球领先的模型性能。通义团队分别对Qwen2.5-Max的指令(Instruct)模型版本和基座(base)模型版本性能进行了评估测试。
指令模型是所有人可直接对话体验到的模型版本,在Arena-Hard、LiveBench、LiveCodeBench、GPQA-Diamond及MMLU-Pro等基准测试中,Qwen2.5-Max比肩Claude-3.5-Sonnet,并几乎全面超越了GPT-4o、DeepSeek-V3及Llama-3.1-405B。
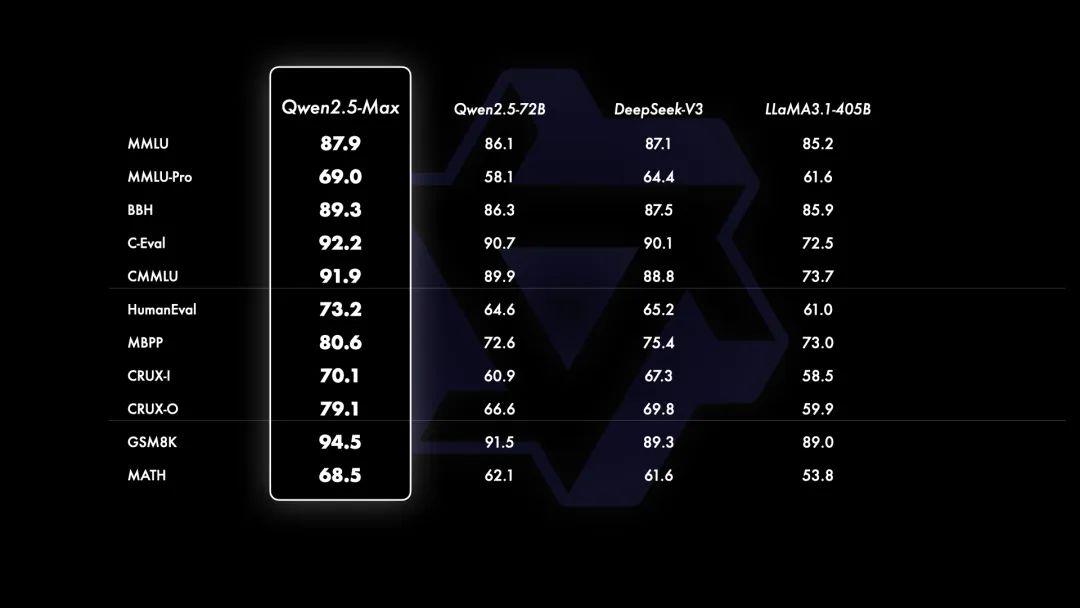
基座模型反映模型裸性能,由于无法访问GPT-4o和Claude-3.5-Sonnet等闭源模型的基座模型,通义团队将Qwen2.5-Max与目前领先的开源MoE模型 DeepSeek V3、最大的开源稠密模型Llama-3.1-405B,以及同样位列开源稠密模型前列的Qwen2.5-72B进行了对比。
评估结果如下所示,在所有11项基准测试中,Qwen2.5-Max全部超越了对比模型。
更方便的取用
目前,Qwen2.5-Max已在阿里云百炼平台上架,模型名称qwen-max-2025-01-25`,企业和开发者都可通过阿里云百炼调用新模型API。
同时,也可以在全新的Qwen Chat(https://chat.qwenlm.ai/)平台上中使用Qwen2.5-Max,直接与模型对话,或者使用artifacts、搜索等功能。
嘿,伙伴们,今天我们的AI探索之旅已经圆满结束。关于“通义千问Qwen2.5-Max详解”的内容已经分享给大家了。感谢你们的陪伴,希望这次旅程让你对AI能够更了解、更喜欢。谨记,精准提问是解锁AI潜能的钥匙哦!如果有小伙伴想要了解学习更多的AI知识,请关注我们的官网“AI智研社”,保证让你收获满满呦!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 














还没有评论呢,快来抢沙发~