
资源编号
13017最后更新
2025-04-11《LLMs损失函数及其应用场景》电子书下载: 这本书主要介绍了在大型语言模型(LLMs)中使用的各种损失函数及其应用场景。以下是文章的主要内容: 1.KL散度(Kullback-……
哈喽!伙伴们,我是小智,你们的AI向导。欢迎来到每日的AI学习时间。今天,我们将一起深入AI的奇妙世界,探索“《LLMs损失函数及其应用场景》电子书下载”,并学会本篇文章中所讲的全部知识点。还是那句话“不必远征未知,只需唤醒你的潜能!”跟着小智的步伐,我们终将学有所成,学以致用,并发现自身的更多可能性。话不多说,现在就让我们开始这场激发潜能的AI学习之旅吧。

《LLMs损失函数及其应用场景》电子书下载:
这本书主要介绍了在大型语言模型(LLMs)中使用的各种损失函数及其应用场景。以下是文章的主要内容:
1.KL散度(Kullback-Leibler Divergence)
定义:KL散度用于衡量两个概率分布之间的差异。
公式:
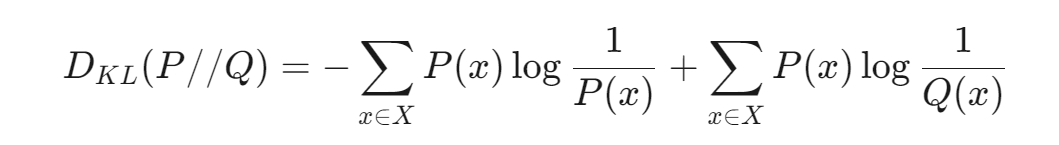
特点:KL散度是非对称的,值是非负数,用于度量两个分布的差异。
2.交叉熵损失函数
定义:交叉熵损失函数用于度量两个概率分布之间的差异,常用于分类问题。
公式:
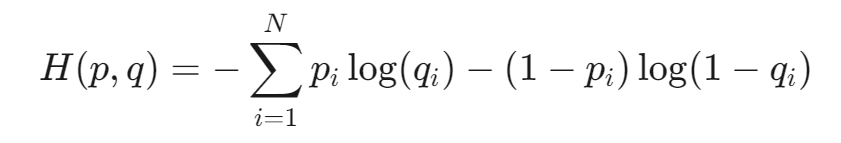
物理意义:衡量实际标签分布与模型预测分布之间的“信息差”,值为0表示完全吻合,值增加表示预测错误程度增加。
3.KL散度与交叉熵的区别
KL散度:衡量两个概率分布的非对称性差异。
交叉熵:二分类问题中最常用的损失函数,可以泛化到多分类问题中,是KL散度的一种特殊形式。
4.多任务学习中处理损失差异过大的方法
动态调整损失权重:根据任务的重要性调整损失权重。
使用任务特定的损失函数:针对不同任务设计不同的损失函数。
改变:调整网络结构以适应不同任务。
引入正则化:通过正则化减少过拟合。
5.为什么分类问题用交叉熵损失函数而不是均方误差(MSE)
分类问题:输出为类别的概率分布,交叉熵损失函数可以度量概率分布的差异。
回归问题:输出为连续数值,MSE损失函数更适用。
交叉熵的优势:对概率的细微差异更敏感,适合分类问题。
6.信息增益
定义:在决策树算法中用于选择最佳特征的评价指标。
作用:衡量特征划分后样本集合的纯度提升程度。
公式:信息增益是原始集合的熵与特定特征下的条件熵之间的差异。
7.多分类的分类损失函数(Softmax)
Softmax函数:将输出值归一化为概率分布。
Softmax交叉熵损失函数:
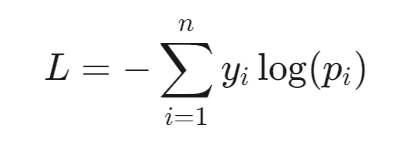
多分类交叉熵:
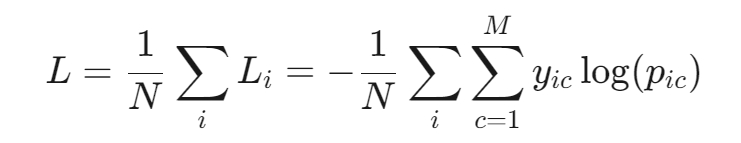
二分类交叉熵:
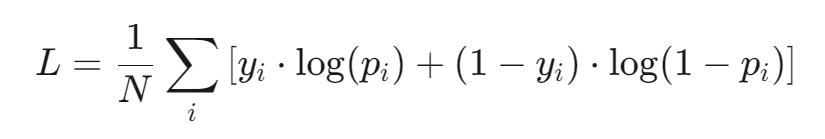
9.处理softmax中e次方超过float值的问题
解决方法:将分子分母同时除以输入向量中的最大值。
公式:
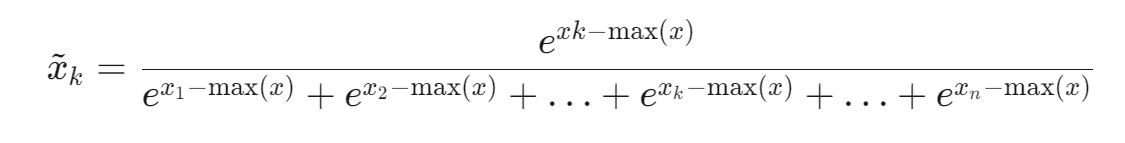
嘿,伙伴们,今天我们的AI探索之旅已经圆满结束。关于“《LLMs损失函数及其应用场景》电子书下载”的内容已经分享给大家了。感谢你们的陪伴,希望这次旅程让你对AI能够更了解、更喜欢。谨记,精准提问是解锁AI潜能的钥匙哦!如果有小伙伴想要了解学习更多的AI知识,请关注我们的官网“AI智研社”,保证让你收获满满呦!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 













还没有评论呢,快来抢沙发~