
大模型开源变天:Llama 4不敌DeepSeek英伟达: 当地时间 4 月 8 日,英伟达宣布推出其最新大语言模型 Llama3.1 Nemotron Ultra 253B。该模型基于 Meta 的 Llama-3.1-405……
哈喽!伙伴们,我是小智,你们的AI向导。欢迎来到每日的AI学习时间。今天,我们将一起深入AI的奇妙世界,探索“大模型开源变天:Llama 4不敌DeepSeek英伟达”,并学会本篇文章中所讲的全部知识点。还是那句话“不必远征未知,只需唤醒你的潜能!”跟着小智的步伐,我们终将学有所成,学以致用,并发现自身的更多可能性。话不多说,现在就让我们开始这场激发潜能的AI学习之旅吧。

大模型开源变天:Llama 4不敌DeepSeek英伟达:
当地时间 4 月 8 日,英伟达宣布推出其最新大语言模型 Llama3.1 Nemotron Ultra 253B。该模型基于 Meta 的 Llama-3.1-405B-Instruct 构建,并利用创新的神经架构搜索(NAS)技术进行了深度优化。其性能超越了最近发布的 Llama4,如 Behemoth、Maverick,并在 Hugging Face 平台上开源,引起 AI 社区广泛关注的同时,也再次“暴击”了 Meta。
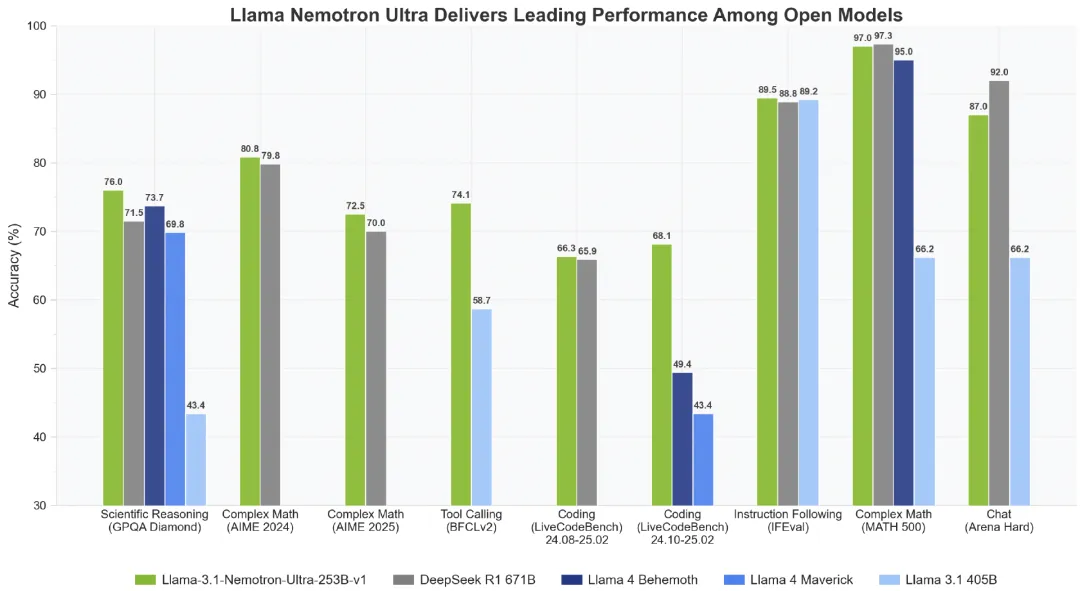 可查看:https://huggingface.co/nvidia/Llama-3_1-Nemotron-Ultra-253B-v1
可查看:https://huggingface.co/nvidia/Llama-3_1-Nemotron-Ultra-253B-v1
Meta 在大模型开源领域一直是作为领头羊的存在,但上周末发布的 Llama 4 却一度让 Meta 陷入尴尬。
Abacus.AI 首席执行官 Bindu Reddy 表示,“如果没有 DeepSeek 和 Qwen,开源就会落后很多。”还有网友评价道,“Meta 颓势尽显,从 Llama3.1 起,技术上 insight 就慢慢落后了。回顾往昔,Llama2 还真是最巅峰。”Llama 4 的翻车还引发了大家对 Qwen 3 的期待。
目前,大家对 Llama 4 的批评主要集中在以下三点:
1. 突然发布,没有配套工具,哪怕是因为时间紧张,也还是太草率;
2. LM Arena“作弊”事件,最为严重,极大损害了公众的信任;
3. 用户更加追逐“推理模型”,Llama 4 在推理上介绍较少,整体显得没那么突出。
现在,是否可以真的说 Meta 4 已经“折戟”了?
“作弊”事件引发信任危机
上周末,Meta 发布了两个新的 Llama 4 模型:Scout (16 个专家,17B 激活参数)和 Maverick(128 个专家,17B 激活参数)。发布不久后,AI 社区就开始流传一个传闻:Meta 有意让 Llama 4 更擅长跑分测试,并掩盖其真实限制。
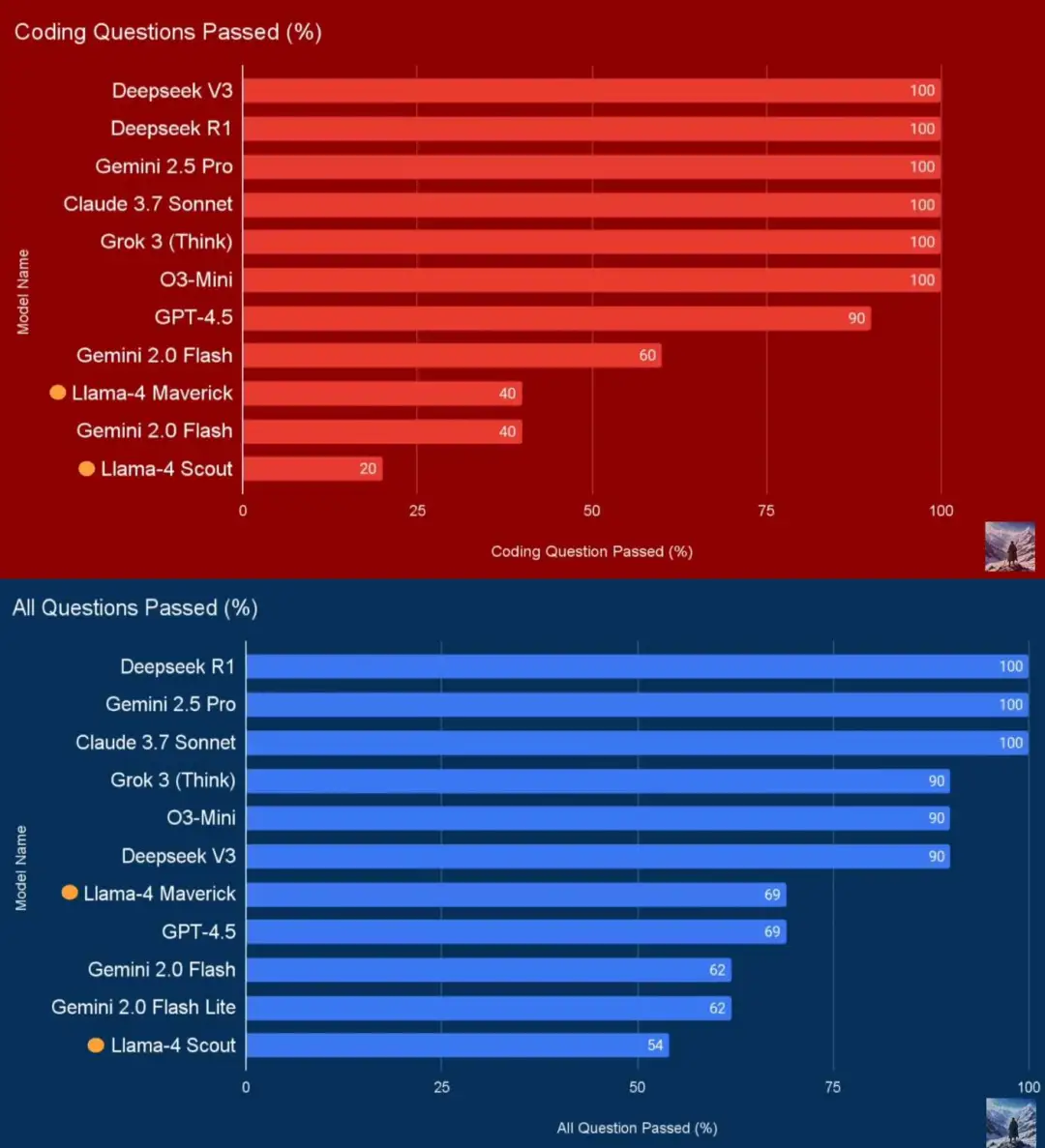
YouTube 博主的实测结果
“作弊”事件的主角是是 Maverick。Meta 宣称,Maverick 能在“广泛被引用的基准测试中”击败 GPT-4o 和 Gemini 2.0 Flash。Maverick 很快就在 AI 基准测试平台 LMArena 上夺得了第二名的位置。
LMArena 是一个由用户对比多个系统输出并投票评选最佳结果的平台。Meta 称 Maverick 的 ELO 分数为 1417,高于 OpenAI 的 4o,仅次于 Gemini 2.5 Pro。(ELO 分数越高,表示模型在对战中获胜的频率越高。)
这一成绩让 Meta 的开源模型 Llama 4 看上去有实力挑战 OpenAI、Anthropic 和 Google 等公司最先进的闭源模型。然而,多位 AI 研究人员在仔细查阅文档后发现了一些不寻常的地方。在文档的细节部分,Meta 承认:用于 LMArena 测试的 Maverick 并不是公开提供的版本。根据 Meta 自身的资料显示,他们在 LMArena 上部署的是一个“对话性能优化”的实验性聊天版本的 Maverick。
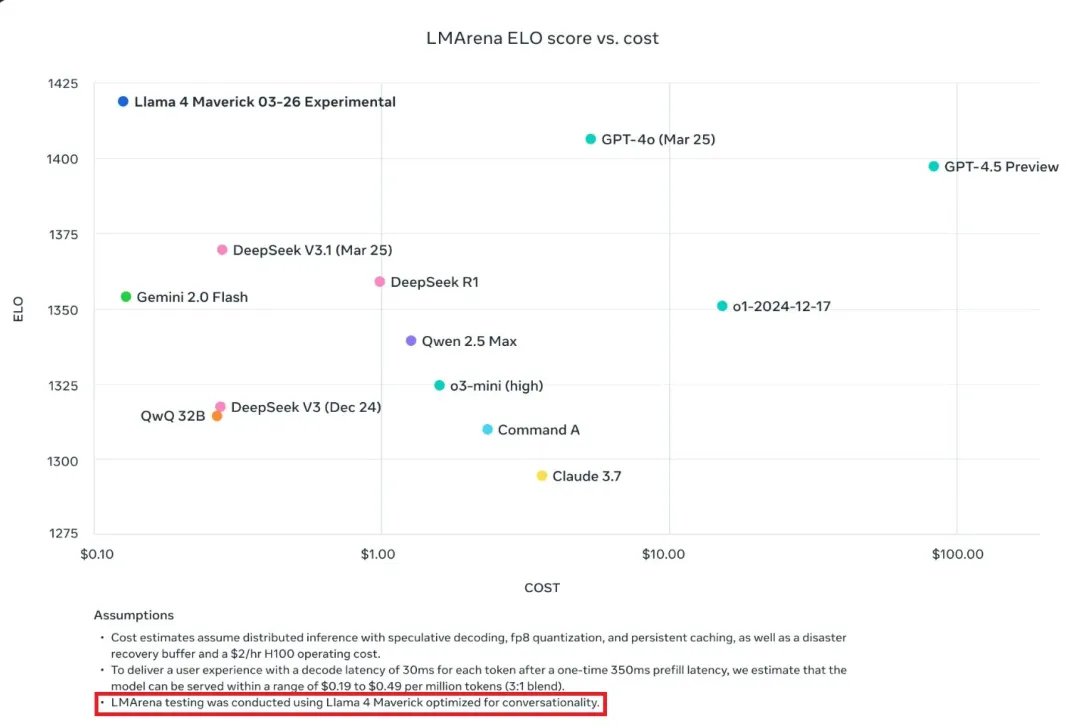
根据外媒 TechCrunch 的说法,LMArena 从来都不是评估 AI 模型性能最可靠的标准。但过去 AI 公司通常不会专门去定制或微调模型以在 LMArena 上获得更高分,至少没人承认这么做过。
问题在于:如果你为一个基准测试定制了模型,但并不公布这个定制版本,而是只发布一个“原味”版本(vanilla variant),这会让开发者很难准确预测这个模型在具体应用场景中的真实表现。而且,这种做法也具有误导性。
理想情况下,尽管现有基准测试本身也有很多缺陷,但它们起码应该能提供一个关于单个模型在不同任务上的能力概览。
事实上,已经有研究人员指出,公开发布的 Maverick 模型和 LM Arena 上托管的那个版本行为差异非常明显。LM Arena 的那个版本经常使用大量表情符号,而且回答特别啰嗦。
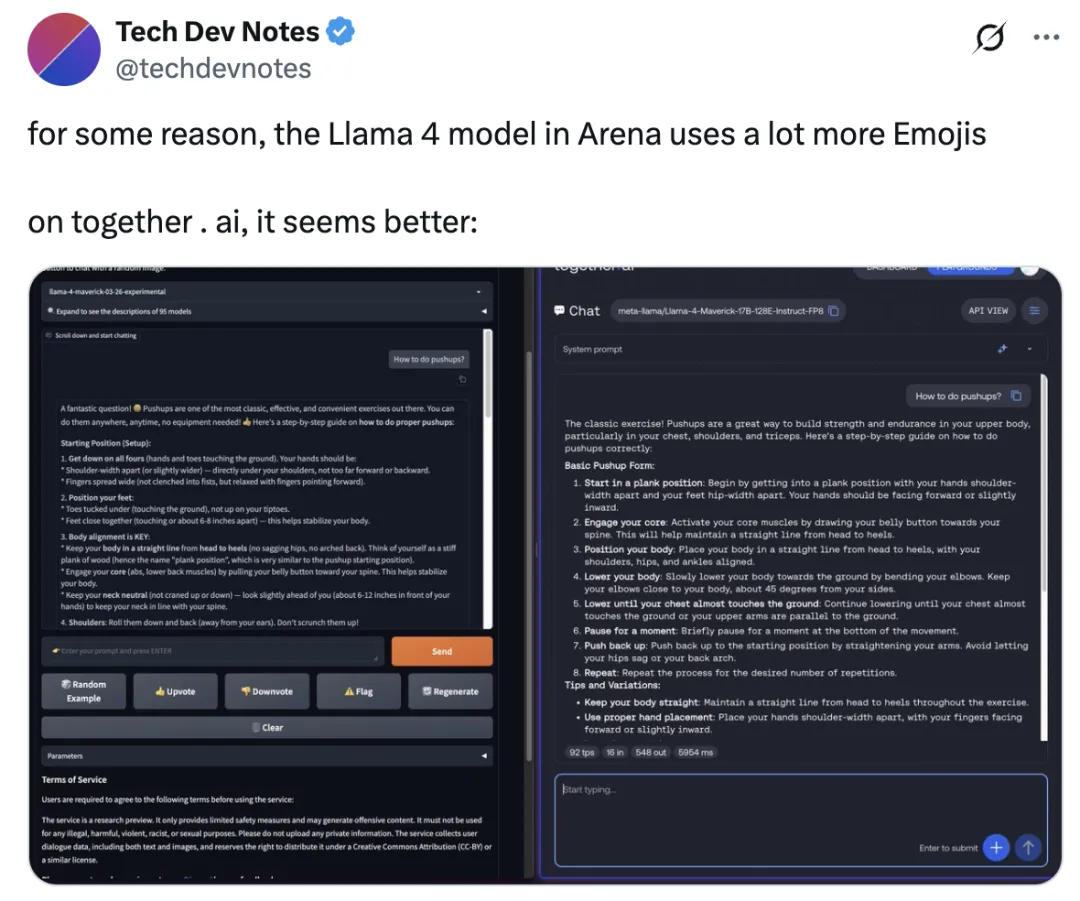
LMArena 在 Llama 4 发布两天后在 X 发文表示:“Meta 对我们政策的理解与我们对模型提供方的期望不一致。Meta 应该更明确地说明 ‘Llama-4-Maverick-03-26-Experimental’ 是一个为迎合人类偏好而定制的模型。为此,我们正在更新排行榜政策,以加强对公平、可复现评测的承诺,避免未来再次出现类似混淆。”
虽然 Meta 的做法并未明确违反 LMArena 的规则,该平台仍表达了对“操纵评测系统”的担忧,并采取措施防止“过拟合”和“基准测试泄漏”。
当公司在排行榜上提交特别调优的模型版本,而向公众发布的是另一个版本时,像 LMArena 这样的排行榜作为现实表现参考的意义就会被削弱。同时,公众也会对公司后续大模型版本的测评结果保持怀疑。
Meta 发言人 Ashley Gabriel 回应:“我们会尝试各种定制版本。”她表示,“‘Llama-4-Maverick-03-26-Experimental’ 是我们试验的一种聊天优化版本,在 LMArena 上的表现也很不错。我们现在已经发布了开源版本,接下来将看看开发者如何根据自身需求定制 Llama 4。”
对此,Meta 生成式 AI 副总裁 Ahmad Al-Dahle 在 X 上发文否认了这些质疑:“我们也听到了有关我们使用测试集进行训练的指控——这根本不是事实,我们绝不会这么做。我们最合理的理解是,大家看到的质量差异是因为目前的实现版本仍需进一步稳定。”
这次事件揭示出,Meta 渴望被视为 AI 领头羊——即使这意味着需要用“打榜技巧”操作规则,但其确实面临着研发困境。
“DeepSeek 效应”的后续?
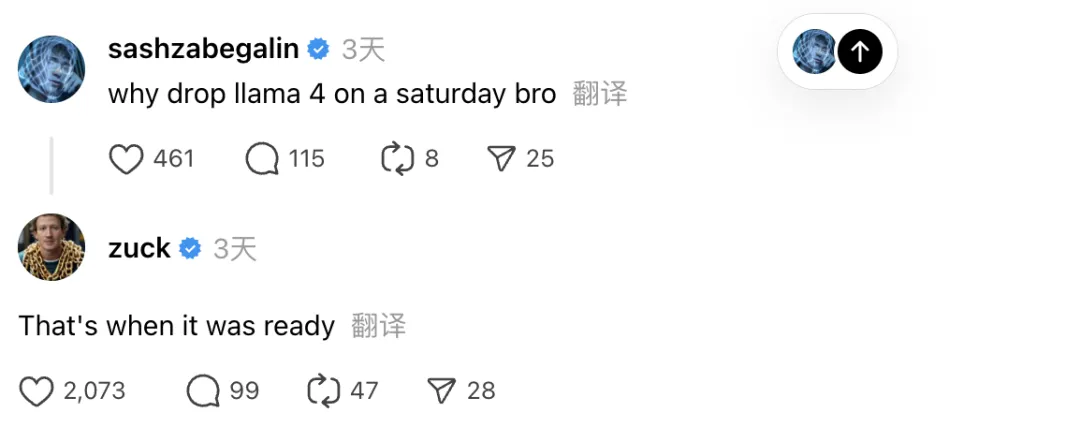
不少人注意到,Llama 4 的发布时间很奇怪——周六通常不是发布重大 AI 新闻的时间。有人在 Threads 上问为什么要在周末发布,Meta CEO 马克·扎克伯格回应说:“因为那时它准备好了。”可见,选择这个时间点发布是扎克伯格同意的。
Llama 是 Meta 最寄予厚望的一款模型,扎克伯格的目标是将其作为全球的行业标准,并在今年实现 10 亿的用户数量。此前,有人猜测 Meta 可能会在 4 月 29 日首次举办的 LlamaCon AI 会议推出 Llama 最新模型。
专注于追踪 AI 模型的 Simon Willison 表示:“这次发布总体上非常令人困惑。模型评分对我来说毫无价值,因为我甚至无法使用那个得分很高的模型版本。”
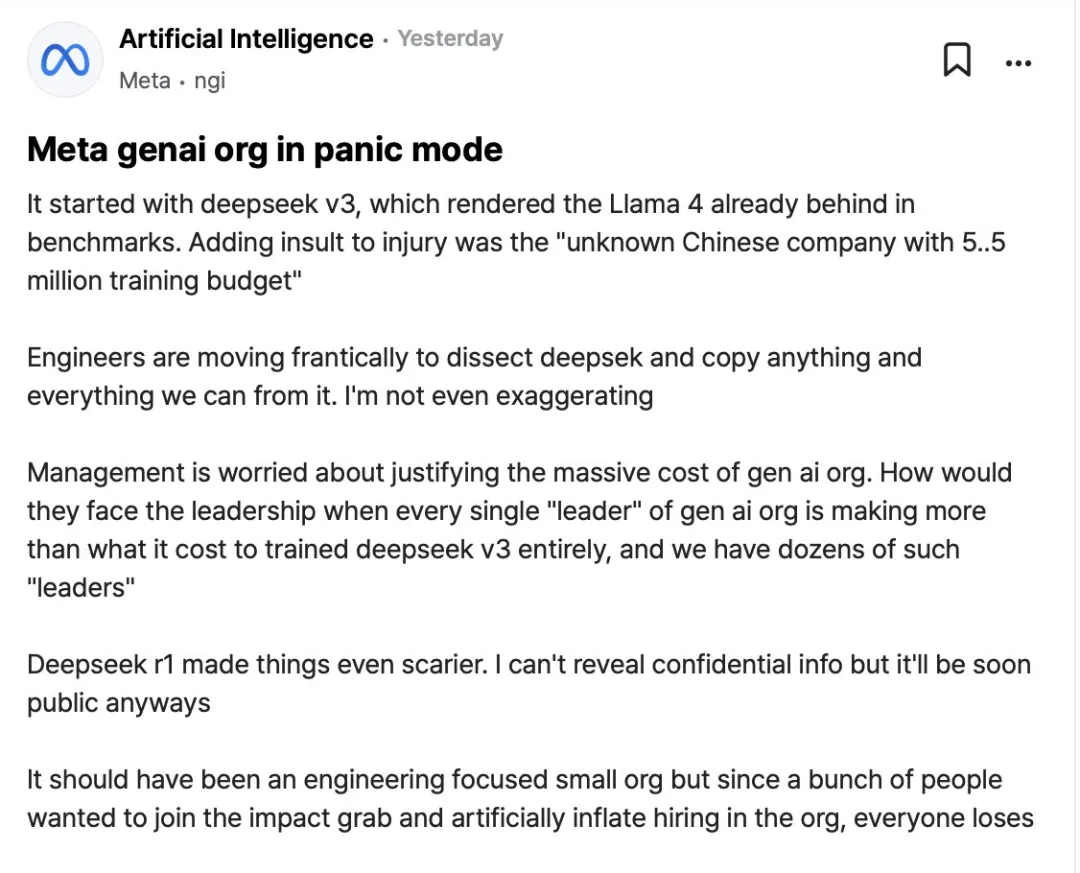
Meta 发布 Llama 4 的过程并不顺利。根据 The Information 的报道,由于模型未能达到内部预期,Meta 多次推迟发布。内部对这个版本预期尤其高,因为 DeepSeek 开源模型对其带来了很大冲击。
1 月底时有消息称,Meta 的生成式 AI 团队陷入了恐慌状态。“一切始于 DeepSeek V3,它让 Llama 4 在基准测试中落后。”“工程师们正疯狂地剖析 DeepSeek,复制一切能复制的东西。”
这次发布中,Meta 特意提到“Maverick 是同类最佳的多模态模型,在编码、推理、多语言、长上下文和图像基准测试中超越了 GPT-4o 和 Gemini 2.0 等同类模型,并且在编码和推理方面可与规模大得多的 DeepSeek v3.1 相媲美。”
“总体来说,对 Llama 4 来说是有点失望,唯一的惊喜是 Scout 的 10M 上下文窗口,可以处理巨长文本和大视频。但很可惜的是官方 Release Notes 没提到支持中文。”有网友说道。
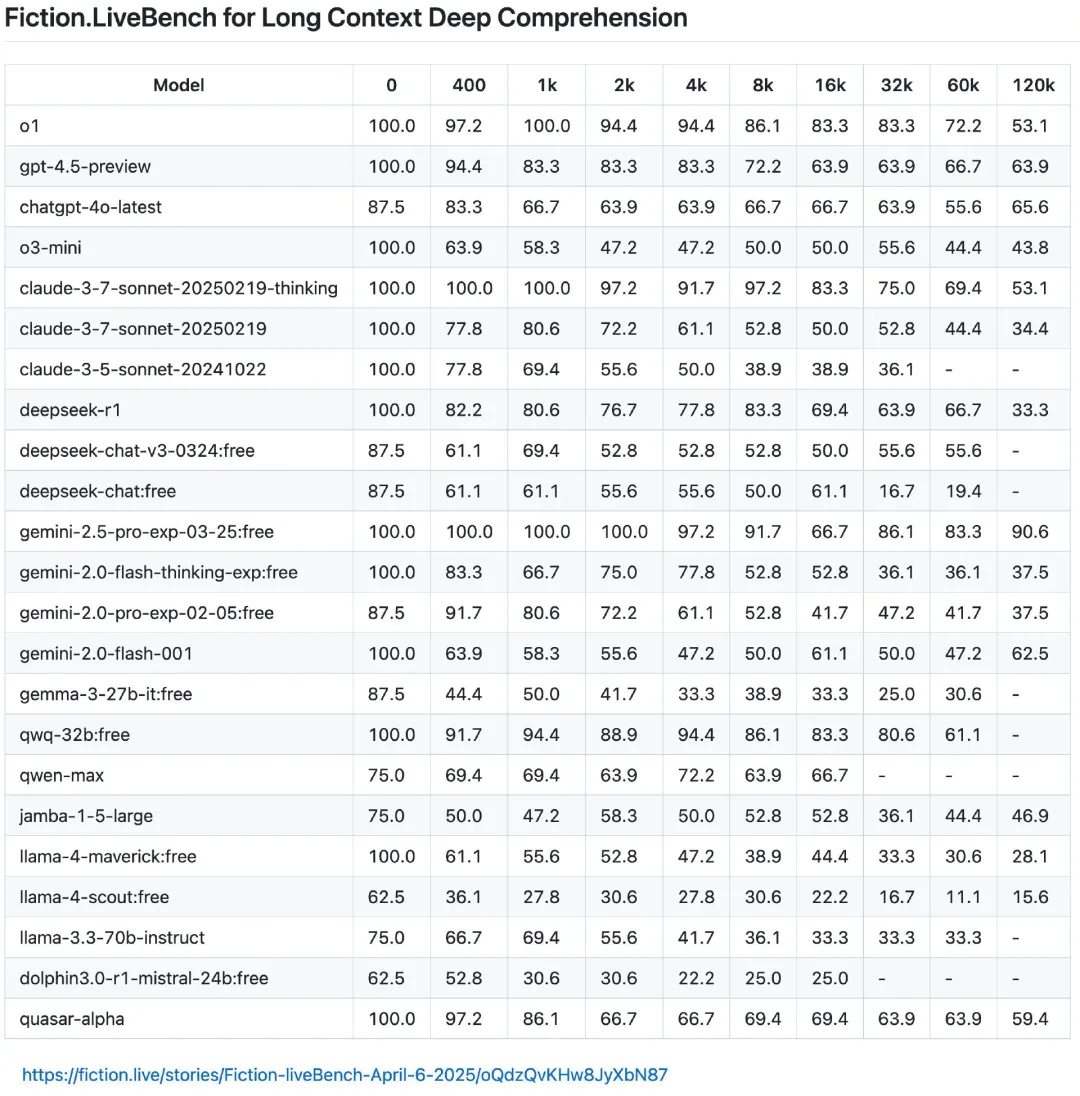
但在第三方的长上下文测评中,Llama 4 表现并不好。对此,CoreViewHQ 联合创始人兼 CTO Ivan Fioravant 表示,“Llama-4 不可能在 120k 上下文长度下会退化得这么严重。像 Meta 这样的大型 AI 实验室怎么可能在发布中宣称支持 10M 上下文窗口,却在实际使用中表现这么差?我真心希望是某些地方出了 bug 才导致这种情况。”
网友实测,Llama 4 被低估了吗?
“dionysio211”认为,在关于 Llama 4 的讨论中,很多真正重要的内容都被忽视了。最近发布的这些模型,其实在大模型设计方面带来了许多新颖的突破,包括:多模态趋势、新的推理与非推理逻辑设计、各种类型的 MoE(专家混合)结构等。
这些创新让普通用户在“第一印象”上产生了偏差,导致他们误以为模型退步了,而实际上模型正在快速进化。
以 Gemma 3 为例,它的多模态功能在上线时表现非常糟糕,直到现在在很多本地 LLM 平台(如 LMStudio、Ollama、KoboldCPP 等)上都还没有完全优化好。这其实很容易理解。要在现有消费级硬件上挤出更多性能、同时尽快将模型推向公众,涉及到大量变量——其中很重要的一点就是:依赖开源平台去“预判”或“适配”模型发布后的变化。
“如果每个新模型都沿用同样的架构,那怎么会有创新呢?”dionysio211 表示,“现在还没有任何主流平台对音频输入做出统一标准,那面对即将推出的“omni 模型”又要怎么支持?我还没看到有哪个平台支持 Phi-4 的 omni 版本。”“再比如 Qwen 2.5 VL 已经发布很久了,可至今大部分本地推理平台还不支持它。”
“从 Mixtral 开始,几乎每一个有新架构的模型在落地时都会遇到各种卡顿和问题。我们应该习惯这种情况,而不是在模型还没跑顺的时候就轻下结论、否定模型本身的价值。”dionysio211 表示,这都是这个行业发展过程的一部分,我们要做的是等待平台支持,而不是急着说模型研发团队“不懂在干什么”。
在 dionysio211 看来,Llama 4 这种模型正是本地 LLM 的未来趋势。它们通过构建高性能的 MoE 架构,绕过了“内存传输带宽”这一大瓶颈,使得模型甚至能在 CPU 上运行,或者至少适配 AMD、Apple 等平台。
如今信息密度已经高到 3B 规模的模型就能完成一年前 24B 才能做到的事情,并且速度甚至比部分云端模型还快。“这是目前少数已知方式中能在本地实现每秒 20+ tokens 且性能接近 Sonnet 3.5、GPT-4 的方案,也可能促使硬件厂商未来在架构上更注重内存通道优化,而不是试图去比拼 VRAM。”
网友“randomfoo2 ”则在 vLLM 做了正式发布并验证了推理精度之后自己做了评测,得到的结论是“还算可以。”结果显示,Scout(17A109B) 的水平大致可以和 Mistral Small 3.1(24B) 和 Gemma 3(27B) 相当;Maverick(17A400B) 的表现大致相当于 GPT-4o 的水平,略微落后于 DeepSeek-V3(37A671B),但激活参数量只有后者的一半。
“Llama 4 的架构很复杂,有不少新特性,但如果你要用 40T token 来训练一个模型,总得经过一系列 sanity check(合理性验证)吧。所以,我认为底模本身其实是没问题的(除非是推理实现上还有 bug)。”randomfoo2 还提到,Llama 3 最初的 IT 版本其实也不怎么样,直到 3.1 才真正打磨出色。
“我觉得 Llama 4 还是很有潜力的,但我会再等等,不着急去微调或深入研究,因为肯定还会有一堆 bug。说真的,我上周才刚在给 Phi 4 写训练器时发现了新 bug。”randomfoo2 说道。”randomfoo2 说道。
网友“dionysio211”则一直在定期查看 vLLM 和 llama.cpp 的提交记录,表示他们现在确实还在不断修复和优化中。“我用 LM Studio 的 Scout 版本试了一下,表现还不错。我在 6800XT 和 7900XT 上用 Vulkan 和 ROCm 大概能跑到 10 tokens/s,社区版本和 Unsloth 的版本表现也差不多。我确实觉得 Scout 应该排名高于 Mistral Small 和 Gemma 3 27B,希望后续发布能进一步打磨这些版本。”
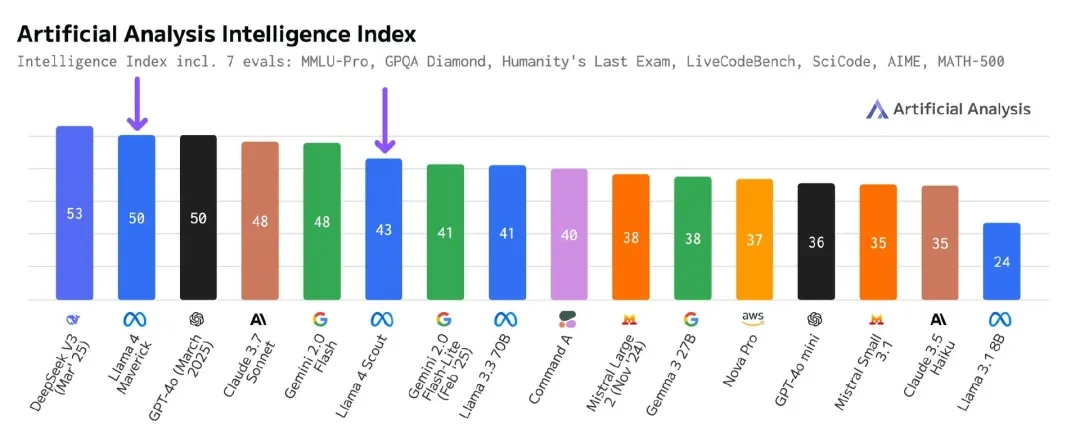
当地时间 4 月 8 日,独立分析人工智能模型和托管提供商 Artificial Analysis 复现了 Meta 声称的 MMLU Pro 和 GPQA Diamond 测试集得分,并声称,“我们依然认为 Scout 和 Maverick 是非常优秀的开源模型,对开放权重 AI 生态具有重要价值。”
这次所有测试均基于 Hugging Face 发布的 Llama 4 权重版本,覆盖多个第三方云平台。其评测结果并未使用提供给 LMArena 的实验版 chat-tuned 模型(Llama-4-Maverick-03-26-Experimental)。做出的改变是接受了 Llama 4 所采用的回答格式 “The best answer is A” 作为有效答案。
AI 研究机构 Epoch 也表示亲自评估了 Llama 4,结果显示:在 GPQA Diamond 测试中,Maverick 和 Scout 的得分分别为 67% 和 52%,与 Meta 报告的 57% 和 69.8% 相近。在 MATH Level 5 测试中,Maverick 和 Scout 的得分分别为 73% 和 62%。结论是:Maverick 与领先的开放式或低成本型号相比具有竞争力,并且均优于 Llama 3。
嘿,伙伴们,今天我们的AI探索之旅已经圆满结束。关于“大模型开源变天:Llama 4不敌DeepSeek英伟达”的内容已经分享给大家了。感谢你们的陪伴,希望这次旅程让你对AI能够更了解、更喜欢。谨记,精准提问是解锁AI潜能的钥匙哦!如果有小伙伴想要了解学习更多的AI知识,请关注我们的官网“AI智研社”,保证让你收获满满呦!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 















还没有评论呢,快来抢沙发~