
资源编号
12204最后更新
2025-04-07《Layer normalization篇》电子书下载: 这本书主要介绍了Layer Normalization(层归一化)及其变种在不同深度学习模型中的应用和实现细节。以下是文章的主要内容: 一……
哈喽!伙伴们,我是小智,你们的AI向导。欢迎来到每日的AI学习时间。今天,我们将一起深入AI的奇妙世界,探索“《Layer normalization篇》电子书下载”,并学会本篇文章中所讲的全部知识点。还是那句话“不必远征未知,只需唤醒你的潜能!”跟着小智的步伐,我们终将学有所成,学以致用,并发现自身的更多可能性。话不多说,现在就让我们开始这场激发潜能的AI学习之旅吧。

《Layer normalization篇》电子书下载:
这本书主要介绍了Layer Normalization(层归一化)及其变种在不同深度学习模型中的应用和实现细节。以下是文章的主要内容:
一、Layer Normalization(层归一化)
1.1 计算公式
Layer Normalization的计算公式如下:
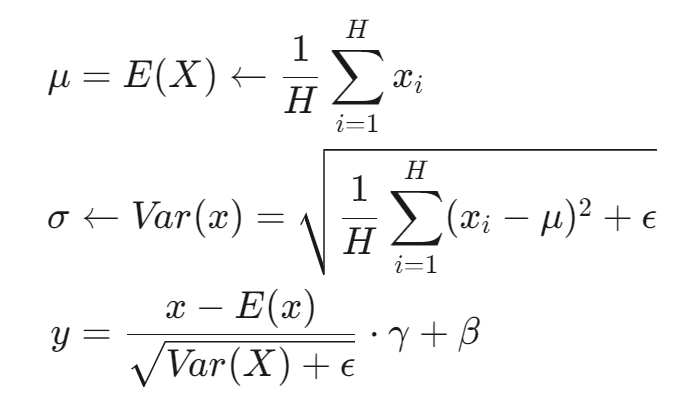
其中,γ 和 β 是可训练的再缩放和再偏移参数。
1.2 位置应用
Post LN:在残差链接之后,可能导致深层梯度范式增大,训练不稳定。
Pre-LN:在残差链接之前,梯度范式近似相等,训练更稳定,但效果略差。
Sandwich-LN:在Pre-LN基础上额外插入一个Layer Norm,用于避免值爆炸,但可能导致训练不稳定。
二、RMS Norm(均方根归一化)
2.1 计算公式
RMS Norm的计算公式如下:
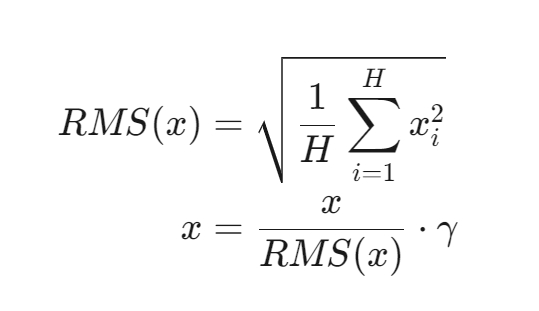
RMS Norm简化了Layer Norm,去除了计算均值进行平移的部分。
2.2 特点
计算速度更快。
效果与Layer Norm基本相当,甚至略有提升。
三、Deep Norm
3.1 思路
Deep Norm在执行Layer Norm之前,对残差连接进行up-scale(α>1),并在初始化阶段对模型参数进行down-scale(β<1)。 3.2 代码实现
python
def deepnorm(x):
return LayerNorm(x * alpha + f(x))def deepnorm_init(w):
if w in [‘ffn’, ‘v_proj’, ‘out_proj’]:
nn.init.xavier_normal_(w, gain=beta)
elif w in [‘q_proj’, ‘k_proj’]:
nn.init.xavier_normal_(w, gain=1)
3.3 优点
缓解爆炸式模型更新问题,使模型训练更稳定。
四、LLMs模型中的Layer Normalization应用
4.1 不同模型的选择
GPT3:使用Pre layer Norm。
LLaMA:使用Pre RMS Norm。
baichuan:使用Pre RMS Norm。
ChatGLM-6B:使用Post Deep Norm。
ChatGLM2-6B:使用Post RMS Norm。
Bloom:使用Pre layer Norm,并在embedding层后添加Layer Norm以提升训练稳定性,但可能带来性能损失。
Falcon:使用Pre layer Norm。
通过这些介绍,文章详细阐述了不同归一化方法的特点及其在大型语言模型中的应用。
嘿,伙伴们,今天我们的AI探索之旅已经圆满结束。关于“《Layer normalization篇》电子书下载”的内容已经分享给大家了。感谢你们的陪伴,希望这次旅程让你对AI能够更了解、更喜欢。谨记,精准提问是解锁AI潜能的钥匙哦!如果有小伙伴想要了解学习更多的AI知识,请关注我们的官网“AI智研社”,保证让你收获满满呦!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 













还没有评论呢,快来抢沙发~