
AI配音GPT-SoVITS指南-使用教程1: 数据集处理:高质量数据集是关键 请认真准备数据集!好的数据集是训练出好模型的基础! 使用 UVR5 处理原音频(如果原音频足够干净可……
哈喽!伙伴们,我是小智,你们的AI向导。欢迎来到每日的AI学习时间。今天,我们将一起深入AI的奇妙世界,探索“AI配音GPT-SoVITS指南-使用教程1”,并学会本篇文章中所讲的全部知识点。还是那句话“不必远征未知,只需唤醒你的潜能!”跟着小智的步伐,我们终将学有所成,学以致用,并发现自身的更多可能性。话不多说,现在就让我们开始这场激发潜能的AI学习之旅吧。

AI配音GPT-SoVITS指南-使用教程1:
数据集处理:高质量数据集是关键
请认真准备数据集!好的数据集是训练出好模型的基础!
使用 UVR5 处理原音频(如果原音频足够干净可以跳过)
方法1:使用自带的 UVR5 处理音频
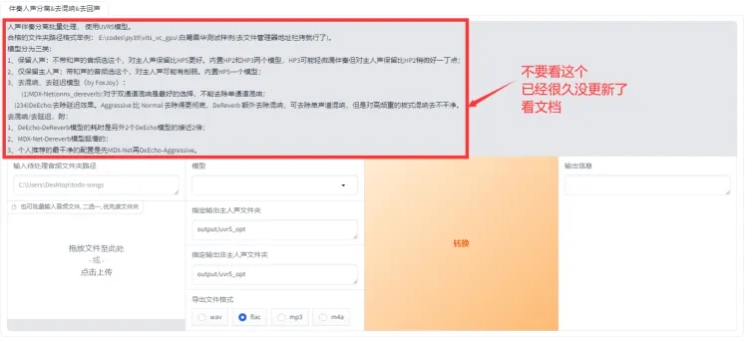
点击“开启 UVR5-WebUI”,稍加等待就会自动弹出网页,如果没有弹出,复制 http://0.0.0.0:9873 到浏览器打开。

首先输入音频文件夹路径或者直接选择文件(二选一)。文件夹上面那个地址框就是文件夹路径,复制即可。
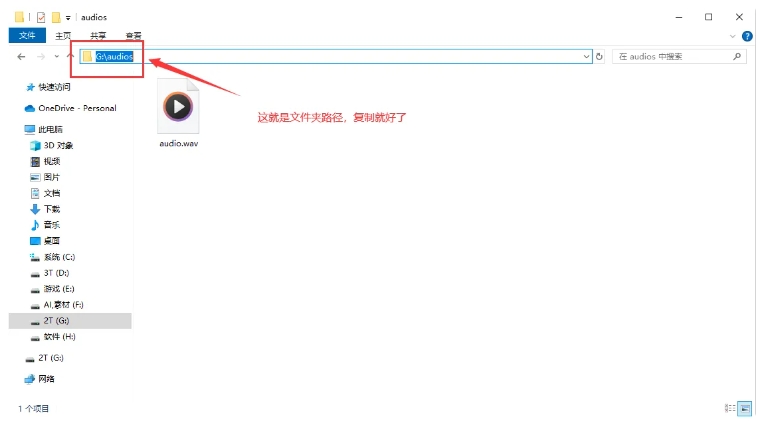
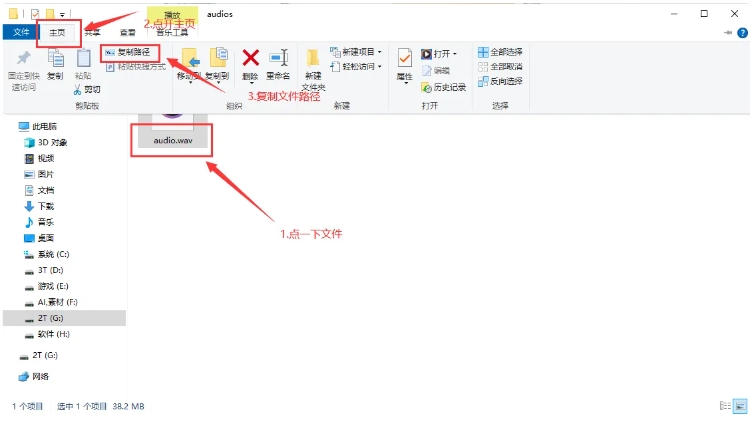
如果要复制文件路径,需要先点一下文件,然后按住 Shift 并右键,选择“复制文件路径”。
先用 model_bs_roformer_ep_317_sdr_12.9755 模型处理一遍(提取人声),然后将输出的干声音频再用 onnx_dereverb 最后用 DeEcho-Aggressive(去混响),输出格式选 wav。输出的文件默认在 GPT-SoVITS-betaoutputuvr5_opt 这个文件夹下,建议不要改输出路径。处理完的音频(vocal)的是人声,(instrument) 是伴奏,(_vocal_main_vocal) 的没混响的,(others)的是混响。(vocal) 和 (_vocal_main_vocal) 才是要用的文件,其他都可以删除。结束后记得在 WebUI 关闭 UVR5 节省显存。
更详细教程:
比如说这里我准备了两段素材,点击一下目录,这就是路径名了,复制一下。
粘贴到输入路径里,下拉选择model_bs_roformer_ep_317_sdr_12.9755模型,然后点击转换,稍等片刻输出信息就会显示xxxx->Success。

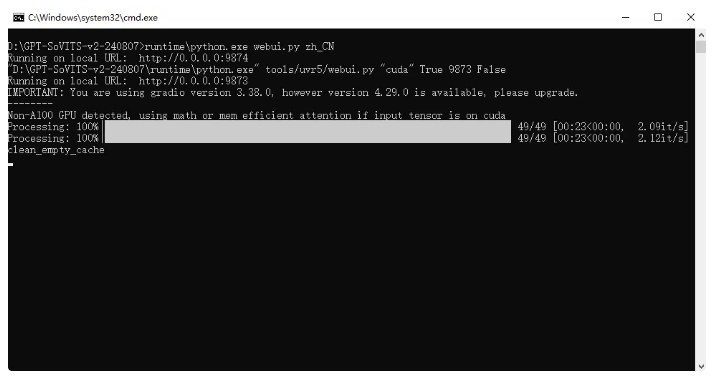
在状态栏点击可以打开bat控制台,在这可以查看进度。
然后打开GPT-SoVITS整合包文件夹的output文件夹。
打开uvr5_opt文件夹。
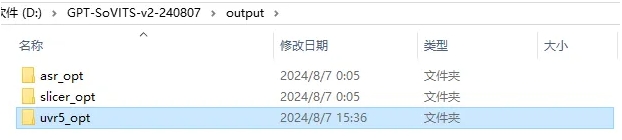
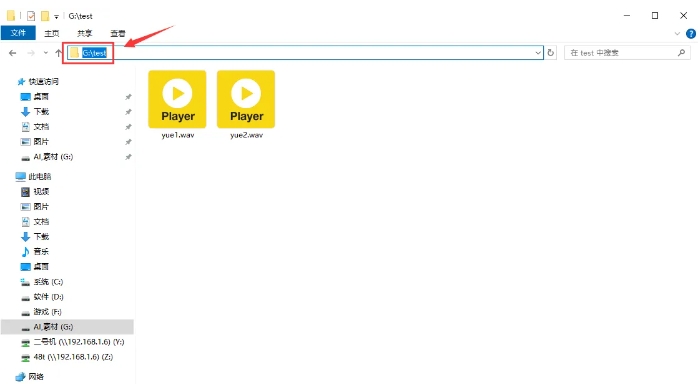
这里会有输入文件数两倍的文件,其中instrumental文件是不需要的,都必须删掉,否则会影响最终效果。再新建一个文件夹把这两个文件移过去。
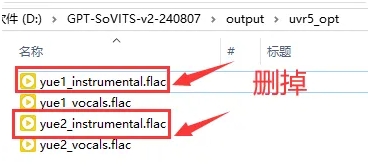
然后输入路径改成上面那个新建文件夹,下拉选择onnx_dereverb_By_FoxJoy模型,点击转换。然后要等待比较长一段时间。同样可以在bat控制台看进度,如果等待的时间实在太长可以跳过这个模型,影响不大。输入的文件还是在uvr5_opt文件夹,其中others是不需要的,删掉。上一步的vocal也不需要了可以删掉。再新建一个文件夹把_vocal_main_vocal这两个文件移过去。
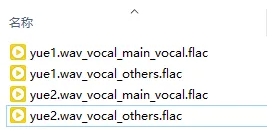
然后输入路径改成上面那个新建文件夹,下拉选择VR-DeEchoAggressive模型(如果混响很重选DeReverb,比较轻选Normal,中间选Aggressive),点击转换。稍微等待一段时间,再打开uvr5_opt文件夹,把instrument开头的删掉就好了。
方法2:使用 UVR5 客户端(没有 bug,模型更多)
官方下载地址:https://github.com/TRvlvr/model_repo/releases(beta版)
https://github.com/Anjok07/ultimatevocalremovergui/releases(正式版)
网盘下载(包含Windows和macOS):https://www.123pan.com/s/UHp9-9fi8H.html
macOS和Liunx的使用方法
由于苹果的严格管控应用程序的安全性,您可能需要按照以下步骤打开UVR:首先,使用终端运行以下命令,允许应用程序从所有来源运行:
sudo spctl –master-disable。
其次,运行以下命令来绕过验证:
sudo xattr -rd com.apple.quarantine /Applications/Ultimate Vocal Remover.app
Linux:嗯?都用Linux了,用Git拉代码自己部署不是难事吧?
为了最好的分离效果教程中使用的是beta版,网盘中的windows安装包是beta版。
目前MAC使用beta版要自己拉代码装环境,或者等安装包制作完成。
网盘中的安装包是正式版的。
警告:安装路径必须为全英文!!!不推荐修改默认安装路径,否则会有权限问题!
详细教程:https://www.bilibili.com/read/cv27499700/ 作者@bilibili@bfloat16
打开UVR5首先要下载模型,建议下载我打包好的,里面有几乎所有模型,包含vip模型。下载解压后先把Ultimate Vocal Remover根目录的models文件夹删了,再把解压的文件夹直接拖进Ultimate Vocal Remover根目录替换models文件夹。
模型包:https://www.123pan.com/s/UHp9-Qfi8H.html(下载精简版就好,里面有要用到的模型了。完整版是UVR5的所有模型,可能以后会用到)语雀直接下载
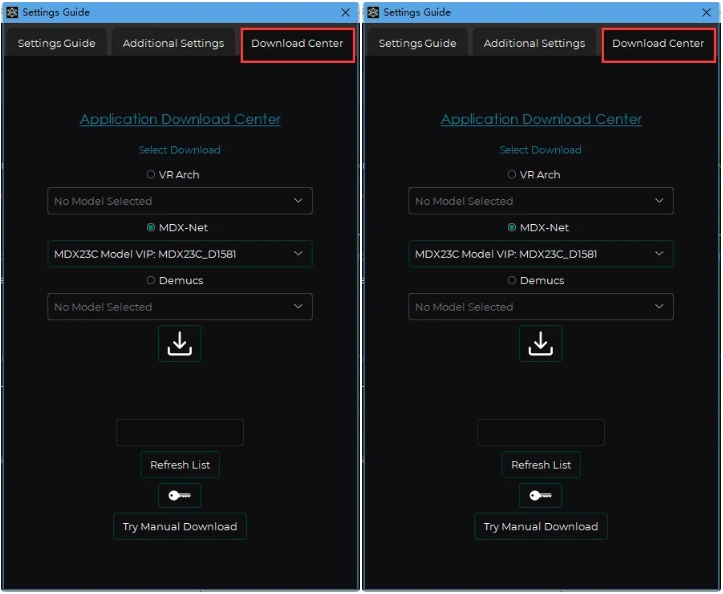
如果觉得模型包太大,也可以自己下载(需要科学上网,且速度很慢,一次只能下一个)。点击左下角的小扳手,打开设置界面,点击第三个下载模型。
需要下载的模型有:
MDX-Net:model_bs_roformer_ep_317_sdr_12.9755。
VR Architecture:UVR-De-Echo-Normal、UVR-De-Echo-Aggressive、UVR-De-Echo-Dereverb、UVR-DeNoise。
如果是A卡或I卡用户需要在第二个设置界面点上Use OpenCL。
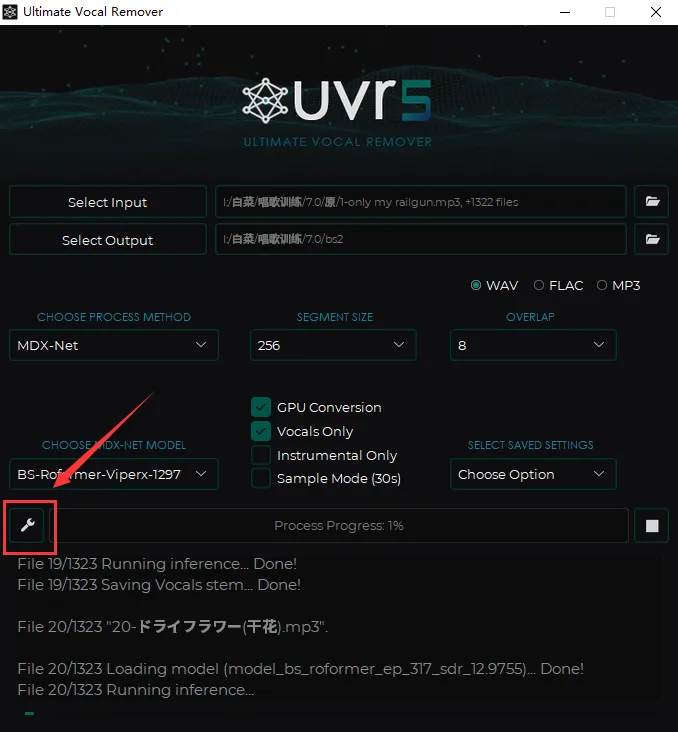
下载完模型后开始处理音频,select input选择输入文件,select output选择输出文件夹,输出格式选WAV,记得点上GPU Conversion(使用GPU),首先选择MDX-Net类型使用Bs-Roformer-Viperx-1297(目前最好的提取人声的模型,又快又好)提取人声。处理完的音频(vocals)的是人声。然后把人声再输入去混响(下面三选一):VR Architecture:UVR-De-Echo-Normal(轻度混响)、UVR-De-Echo-Aggressive(重度混响)、UVR-De-Echo-Dereverb(变态混响),最后用UVR-DeNoise降噪一下。这套流程弄完会比自带的UVR5在人声提取方面好一点。
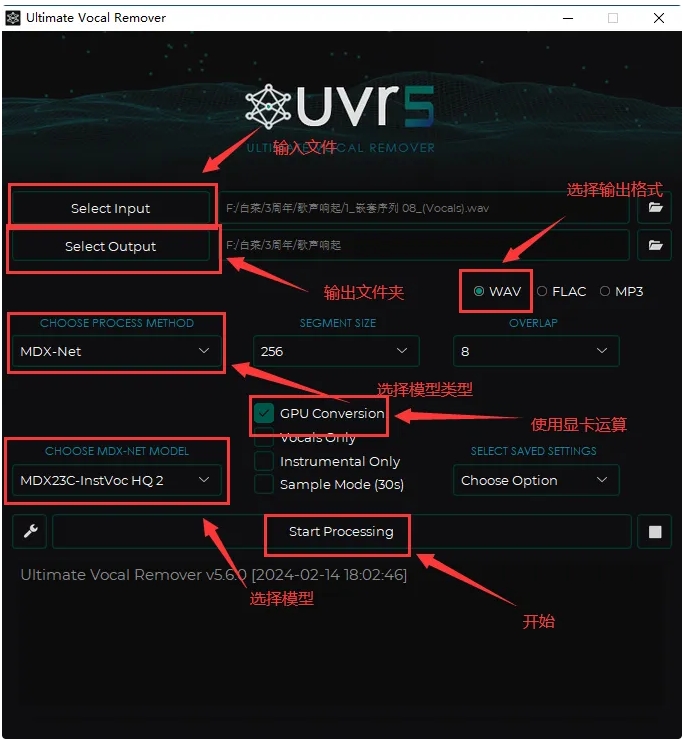
方法 3:MDX23C(MAC 用户暂时使用)
因为目前MAC没有UVR5beta版的安装包,要么拉代码自己装,要么只能用5.6正式版。
正式版目前最好的模型是MDX23C,流程和4.1.1.1.3.1一样的只是把Bs-Roformer-Viperx-1297换成MDX23C。
切割音频:准备训练数据
在切割音频前,建议把所有音频拖进音频软件(如 AU、剪映)调整音量,最大音量调整至 -9dB 到 -6dB,过高的删除。
首先输入原音频的文件夹路径(不要有中文),如果刚刚经过了 UVR5 处理,那么就是 uvr5_opt 这个文件夹。然后建议可以调整的参数有 min_length、min_interval 和 max_sil_kept,单位都是 ms。min_length 根据显存大小调整,显存越小调越小。min_interval 根据音频的平均间隔调整,如果音频太密集可以适当调低。max_sil_kept 会影响句子的连贯性,不同音频不同调整,不会调的话保持默认。其他参数不建议调整。点击“开启语音切割”,马上就切割好了。默认输出路径在 output/slicer_opt。当然也可以使用其他切分工具切分。
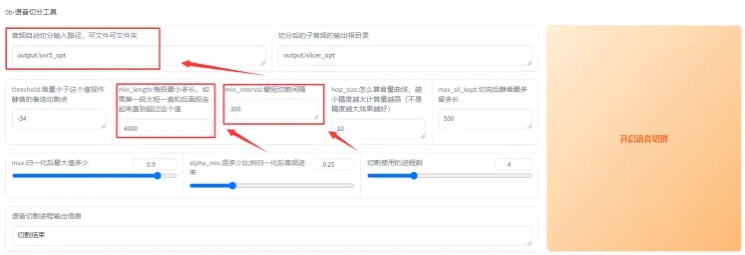
切分完后文件在 outputslicer_opt。打开切分文件夹,排序方式选大小,将时长超过“显存数”秒的音频手动切分至“显存数”秒以下。比如显卡是 4090,显存是 24g,那么就要将超过 24 秒的音频手动切分至 24s 以下,音频时长太长的会爆显存。如果语音切割后还是一个文件,那是因为音频太密集了。可以调低 min_interval,从 300 调到 100 基本能解决这问题。实在不行用 AU 手动切分。
音频降噪(如果原音频足够干净可以跳过)
如果你觉得你的音频足够清晰可以跳过这步,降噪对音质的破坏挺大的,谨慎使用。
输入刚才切割完音频的文件夹,默认是 output/slicer_opt 文件夹。然后点击“开启语音降噪”。默认输出路径在 output/denoise_opt。

打标:为音频添加文本标注
为什么要打标:打标就是给每个音频配上文字,这样才能让 AI 学习到每个字该怎么读。这里的标指的是标注。
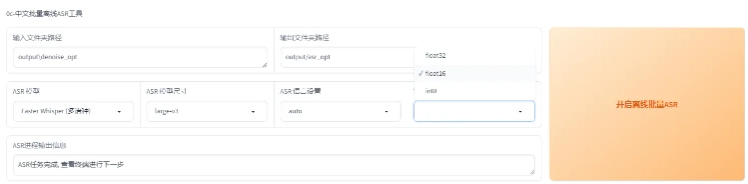
如果你上一步切分了或者降噪了,那么已经自动帮你填充好路径了。然后选择“达摩 ASR”或者“fast whisper”。达摩 ASR 只能用于识别汉语和粤语,效果也最好。“fast whisper”可以标注 99 种语言,是目前最好的英语和日语识别,模型尺寸选 large V3,语种选 auto 自动。Whisper 可以选择精度,建议选 float16,float16 比 float32 快,int8 速度几乎和 float16 一样。然后点“开启离线批量 ASR”就好了,默认输出是 output/asr_opt 这个路径。ASR 需要一些时间,看着控制台有没有报错就好了。
如果有字幕的可以用字幕标注,准确多了。内嵌字幕或者外挂字幕都可以。
校对标注(比较费时间,不追求极致效果可以跳过)
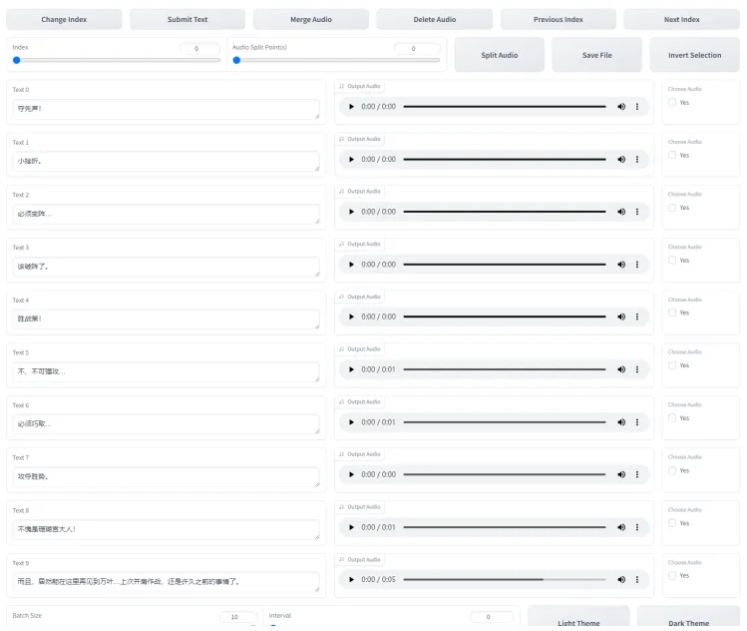
上一步打标完会自动填写list路径,你只需要点击“开启打标webui”。
打开后就是 SubFix,从左往右从上到下依次意思是:跳转页码、保存修改、合并音频、删除音频、上一页、下一页、分割音频、保存文件、反向选择。每一页修改完都要点一下“保存修改 (Submit Text)”,如果没保存就翻页那么会重置文本,在完成退出前要点“保存文件 (Save File)”,做任何其他操作前最好先点一下“保存修改 (Submit Text)”。合并音频和分割音频不建议使用,精度非常差,一堆 bug。删除音频先要点击要删除的音频右边的 yes,再点“删除音频 (Delete Audio)”。删除完后文件夹中的音频不会删除但标注已经删除了,不会加入训练集的。这个 SubFix 一堆 bug,任何操作前都多点两下保存。
嘿,伙伴们,今天我们的AI探索之旅已经圆满结束。关于“AI配音GPT-SoVITS指南-使用教程1”的内容已经分享给大家了。感谢你们的陪伴,希望这次旅程让你对AI能够更了解、更喜欢。谨记,精准提问是解锁AI潜能的钥匙哦!如果有小伙伴想要了解学习更多的AI知识,请关注我们的官网“AI智研社”,保证让你收获满满呦!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 















还没有评论呢,快来抢沙发~