
多模态KV量化突破:10倍吞吐无损,即插即用: 在 InternVL-2.5 上实现 10 倍吞吐量提升,模型性能几乎无损失。 最新 1-bit 多模态大模型 KV cache 量化方案 CalibQuant ……
哈喽!伙伴们,我是小智,你们的AI向导。欢迎来到每日的AI学习时间。今天,我们将一起深入AI的奇妙世界,探索“多模态KV量化突破:10倍吞吐无损,即插即用”,并学会本篇文章中所讲的全部知识点。还是那句话“不必远征未知,只需唤醒你的潜能!”跟着小智的步伐,我们终将学有所成,学以致用,并发现自身的更多可能性。话不多说,现在就让我们开始这场激发潜能的AI学习之旅吧。

多模态KV量化突破:10倍吞吐无损,即插即用:
在 InternVL-2.5 上实现 10 倍吞吐量提升,模型性能几乎无损失。
最新 1-bit 多模态大模型 KV cache 量化方案 CalibQuant 来了。
通过结合后缩放和校准方法,可显著降低显存与计算成本,无需改动原模型即可直接使用。

即插即用、无缝集成
多模态大语言模型在各种应用中展现出了卓越的性能。然而,它们在部署过程中的计算开销仍然是一个关键瓶颈。
虽然 KV cache 通过用显存换计算在一定程度上提高了推理效率,但随着 KV cache 的增大,显存占用不断增加,吞吐量受到了极大限制。
为了解决这一挑战,作者提出了 CalibQuant,一种简单却高效的视觉 KV cache 量化策略,能够大幅降低显存和计算开销。具体来说,CalibQuant 引入了一种极端的 1 比特量化方案,采用了针对视觉 KV cache 内在模式设计的后缩放和校准技术,在保证高效性的同时,不牺牲模型性能。
作者通过利用 Triton 进行 runtime 优化,在 InternVL-2.5 模型上实现了 10 倍的吞吐量提升。这一方法具有即插即用的特性,能够无缝集成到各种现有的多模态大语言模型中。
动 机
当前的多模态大语言模型在实际应用中常常需要处理大尺寸、高分辨率的图像或视频数据,KV cache 机制虽然能提升效率,但其显存占用与输入长度(如视觉帧数、图像尺寸等)成正比。
当输入数据的规模增大(例如更多的视觉帧、更高的图像分辨率)时,KV 缓存的显存使用量迅速增加,成为限制吞吐量的瓶颈。尽管当前有些针对 LLM KV cache 量化的方法可以将其压缩至 2 比特,但这些方法没有针对多模态问题中特有的视觉冗余做分析优化,导致其无法在极限情况 1 比特下被使用。
本文通过分析多模态大语言模型中的视觉 KV cache 的冗余,设计了适合多模态模型特有的 KV cache 量化方案。
方 法
本文在通道维度量化的基础上提出了针对反量化计算顺序的后缩放优化方案和针对注意力权重优化的校准策略。
1. 通道维度 KV cache 量化:
一种广泛使用的方法是均匀整数量化。给定一个比特宽度 b>0 和一个输入值 x,它位于某个范围 [α,β] 内,则将其映射到一个离散整数图片,计算过程为:
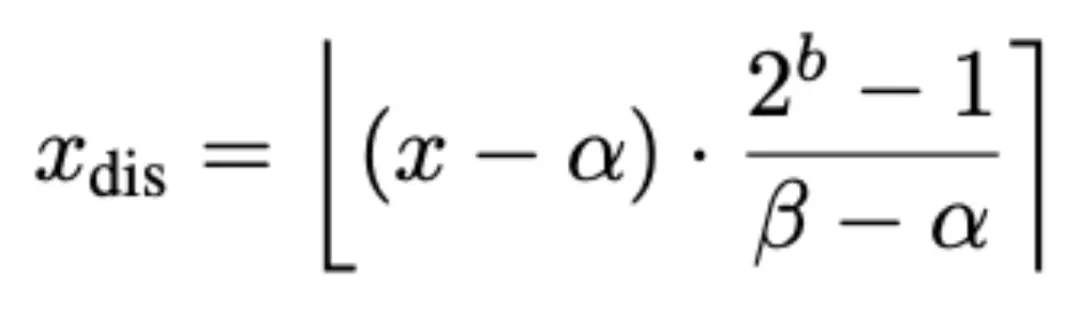
这里的⌊⋅⌉表示取整运算符。最朴素的方法是使用全局统计量来计算这些极值,但是模型性能会受较大影响,作者选择在通道维度上细化统计范围。具体来说,令图片表示一个 K cache,其中 n 和 d 分别表示 token 的数量和 head 的维度。图片 定义两个向量如下:
然后,通过上述过程对 K 中的每一行向量进行量化,其中乘法操作是逐元素进行的。作者同样将这种按通道的量化方法应用于 V cache。
2. 后缩放 KV cache 管理策略:
量化后的 K cache 可以用离散化的整数值、一个缩放因子(scale factor)和一个偏置项(bias term)来表示。在解码阶段,这些值被用于对 K cache 进行反量化,并随后与 Q 相乘。然而,通道维度的量化需要为每个通道分别指定不同的缩放因子和偏置向量,这将导致产生大量不同的数值,增加了反量化过程中的计算开销。此外,这种方式也使得 CUDA 内核中的计算效率降低。作者观察到量化后的 K 仅具有有限数量的离散取值(例如,对于 2 比特量化,其取值仅为 0、1、2、3),于是提出利用简单的计算顺序重排来减少存储需求,并提高计算效率。具体过程如下:
设图片是 K cache 矩阵图片中的任意一行向量,
为其进行 b 比特整数量化后的结果,并伴随有逐通道的缩放因子α,β。给定一个查询向量图片,在生成 token 过程中注意力计算如下:
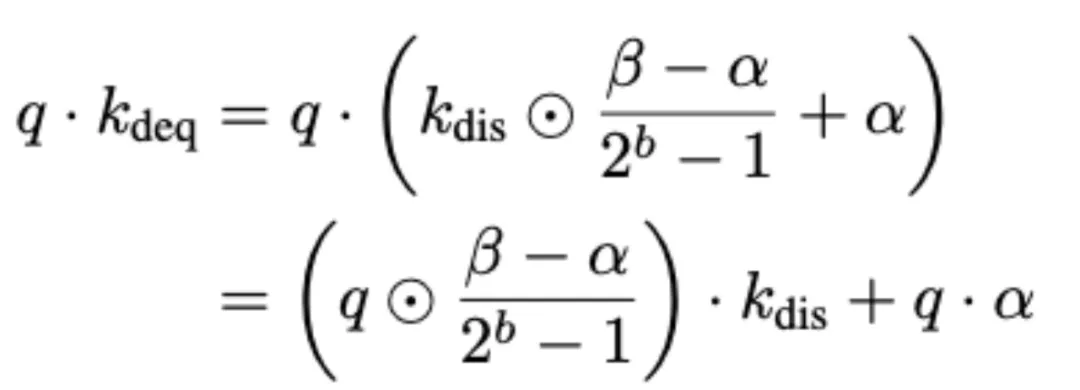
其中,符号⋅和⊙分别表示向量之间的内积和逐元素乘积。通道维度上的反量化操作图片被延迟执行,并高效地集成到后续的向量乘法运算中。因此,这种方法仅存储经过 b 比特整数量化后的数值,并且避免了全精度反量化计算过程。这种方法确保了低比特反量化执行的高效性。这种后缩放方法也可以自然地应用到 V cache 的反量化过程中。
量化后的校准:
1 比特量化的一个限制是经过反量化之后的数值往往会包含大量的极端值。这是因为 1 比特量化的码本总是包含了最小值和最大值,导致那些接近边界的输入值在反量化后直接映射到了极端值。
因此,重建后的 KV cache 通常包含过多的大绝对值,最终导致注意力分数产生明显的失真。为了解决这个问题,作者提出了一种量化后校准方法,用于调整 softmax 之前注意力分数的峰值。具体来说,假设图片的所有元素都位于区间图片内。给定图片,定义一个线性变换 g 将区间图片映射到图片,其表达式如下:
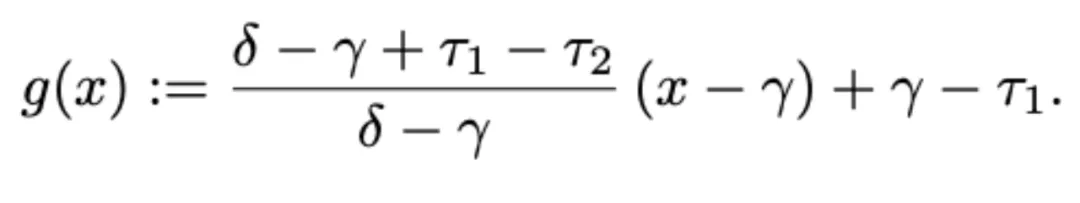
随后对注意力分数进行如下调整:
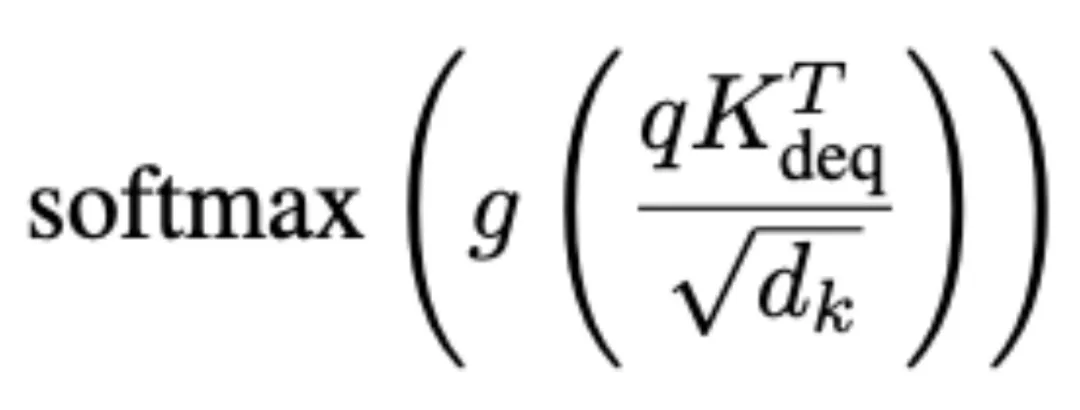
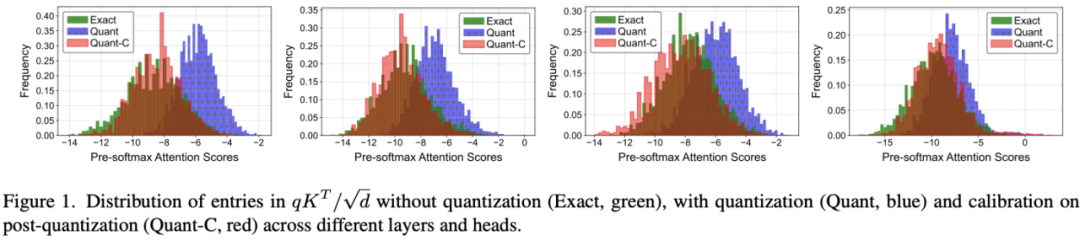
图片如下图所示,校准方法(Quant-C,红色)有效减轻了极端值的影响,使调整后的注意分数分布相较于未经校准的量化方法(Quant,蓝色)更接近全精度(Exact)分布。
实验结果
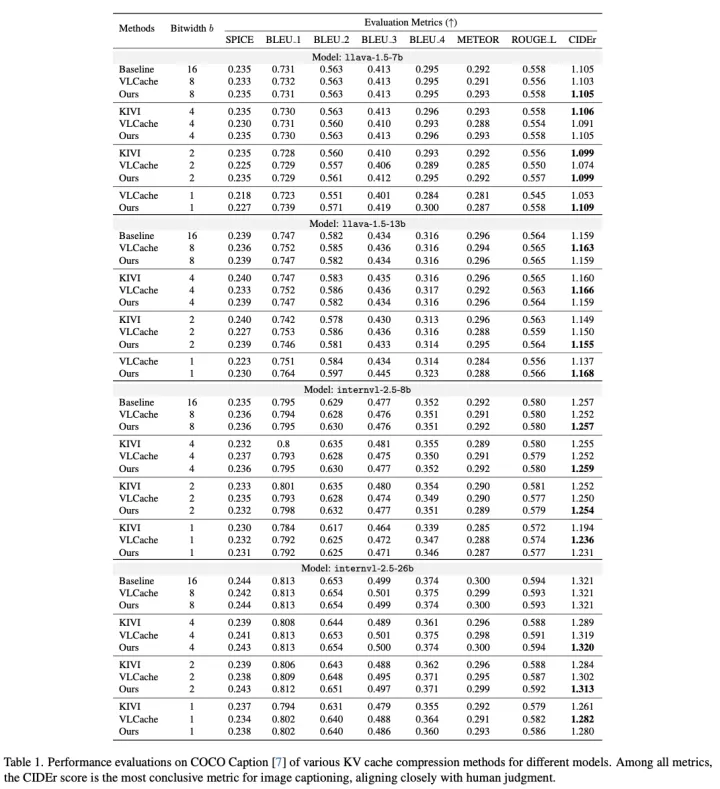
作者将提出的量化方法分别应用在 LLaVA 和 InternVL model 上,测试了其在 captioning,VQA,Video QA 三个不同的任务上的性能。以 captioning 任务为例,下图展示了本文所提出的方法在 cococaption benchmark 下和其他方法如 KIVI,VLCache 的对比。
在不同比特数(8,4,2,1)下,本文提出的方法在大部分测试指标上都优于其他两种方法。例如对于 llava-1.5-7b,本文的方法在 8 比特下达到最高的 CIDEr 分数 1.105,与全精度持平,并在 1 比特下提升至 1.109,超过了 VLCache(1.053)。同样地,对于 InternVL-2.5-26B,本文的方法在 4 比特和 2 比特下分别取得了最高的 CIDEr 分数 1.32 和 1.313,均优于 VLCache 和 KIVI。
Runtime 分析
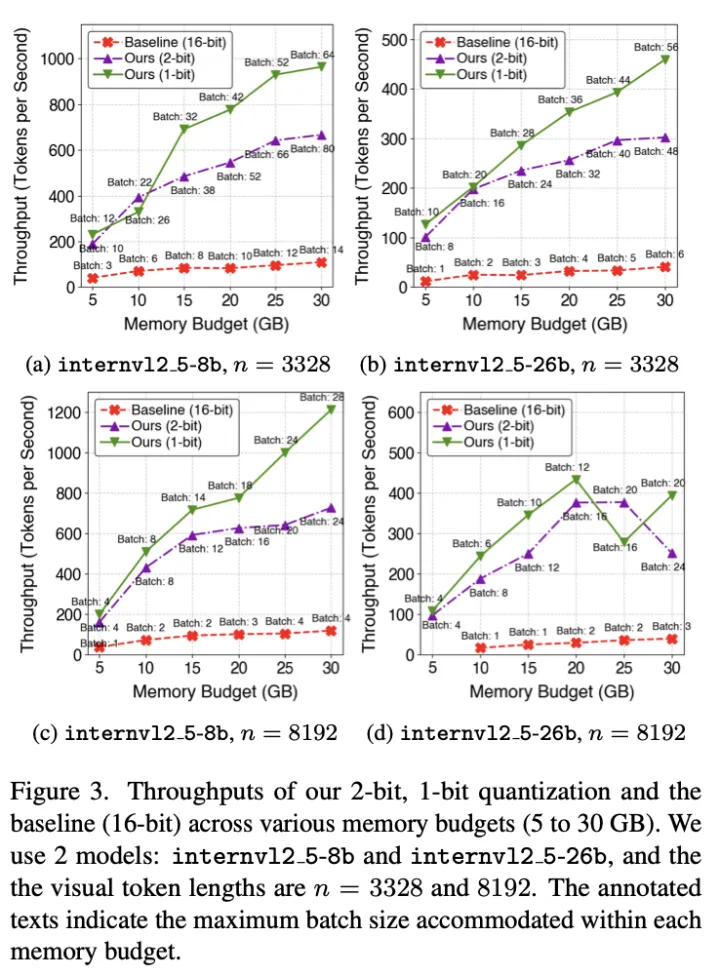
为了展示本文提出的量化方法对解码效率的影响,作者使用 InternVL-2.5 系列模型,将所提出的 1 比特量化方法与 16 比特基线进行了吞吐量评估(即每秒生成的 token 数)。作者考虑了两种视觉 token 长度的情况:n=3328 和 8192。作者将 GPU 最大内存从 5GB 变化到 30GB,并在每种内存限制下,寻找能够容纳的最大 batch size,测量解码阶段的吞吐量。
如下图展示,1 比特量化方法在所有显存预算下始终优于基线方法。例如,当 n=3329 且使用 80 亿参数模型时,本文的方法在 5GB 显存下实现了 126.582tokens/s 的吞吐量(基线为 11.628tokens/s),在 30GB 下提升至 459.016tokens/s(基线为 40.816tokens/s)。这意味着相比基线,本文方法的吞吐量提升约为 9.88×到 11.24×,充分展示了该方法在受限显存条件下显著提升解码速率。
本文探讨了多模态大语言模型中视觉 KV cache 的压缩方法。简单地将量化应用到极低比特数常常会引发分布偏移,导致模型性能下降。为了解决这一问题,本文提出了一种新颖的校准策略,作用于 softmax 之前的注意力分数,有效缓解了量化带来的失真。此外,本文还引入了一种高效的通道维度后缩放技术以提高计算和存储效率。
作者在 InternVL 和 LLaVA 模型系列上,针对 COCO Caption、MMBench-Video 和 DocVQA 等基准任务进行了实验,结果验证了所提出方法的有效性。作者利用 Triton 实现了本文所提出的方法,runtime 分析表明本文提出的方法相较于全精度模型有大约 10 倍的吞吐量提升。
嘿,伙伴们,今天我们的AI探索之旅已经圆满结束。关于“多模态KV量化突破:10倍吞吐无损,即插即用”的内容已经分享给大家了。感谢你们的陪伴,希望这次旅程让你对AI能够更了解、更喜欢。谨记,精准提问是解锁AI潜能的钥匙哦!如果有小伙伴想要了解学习更多的AI知识,请关注我们的官网“AI智研社”,保证让你收获满满呦!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 















还没有评论呢,快来抢沙发~