
资源编号
11082最后更新
2025-04-02《大模型(LLMs)基础面》电子书下载: 这本书主要介绍了大语言模型(LLMs)的基础知识,包括开源模型体系、训练目标、涌现能力、模型结构选择、模型定义及优缺点等内容……
哈喽!伙伴们,我是小智,你们的AI向导。欢迎来到每日的AI学习时间。今天,我们将一起深入AI的奇妙世界,探索“《大模型(LLMs)基础面》电子书下载”,并学会本篇文章中所讲的全部知识点。还是那句话“不必远征未知,只需唤醒你的潜能!”跟着小智的步伐,我们终将学有所成,学以致用,并发现自身的更多可能性。话不多说,现在就让我们开始这场激发潜能的AI学习之旅吧。

《大模型(LLMs)基础面》电子书下载:
这本书主要介绍了大语言模型(LLMs)的基础知识,包括开源模型体系、训练目标、涌现能力、模型结构选择、模型定义及优缺点等内容。以下是文章的主要内容:
开源模型体系
1. Prefix Decoder系
介绍:输入双向注意力,输出单向注意力。
代表模型:ChatGLM、ChatGLM2、U-PaLM。
2. Causal Decoder系
介绍:从左到右的单向注意力。
代表模型:LLaMA-7B、LLaMa衍生物。
特点:自回归语言模型,预训练和下游应用一致,遵守只有后面的token才能看到前面的token的规则。
适用任务:文本生成任务效果好。
优点:训练效率高,zero-shot能力更强,具有涌现能力。
3. Encoder-Decoder
介绍:输入双向注意力,输出单向注意力。
代表模型:T5、Flan-T5、BART y1y2。
适用任务:在偏理解的NLP任务上效果好。
缺点:在长文本生成任务上效果差,训练效率低。
模型结构选择
1. Prefix Decoder vs. Causal Decoder vs. Encoder-Decoder
Attention Mask:不同结构的注意力mask不同。
训练效率:Prefix Decoder < Causal Decoder。
涌现能力:Causal Decoder和Prefix Decoder在训练效率和涌现能力上有不同的表现。
训练目标
1. 语言模型
目标:根据已有词预测下一个词,训练目标为最大似然函数。
公式:
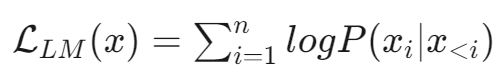
2. 去噪自编码器
目标:随机替换文本段,训练语言模型恢复被打乱的文本段。
公式:
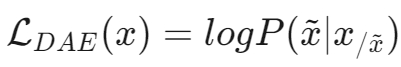
实现难度:更高。
涌现能力
原因:任务评价指标不够平滑,复杂任务与子任务之间的指标增长不平滑。
模型结构选择的原因
Decoder Only结构:在没有任何微调数据的情况下,zero-shot表现能力最好。
Encoder-Decoder结构:需要在一定量的标注数据上做multitask-finetuning才能激发最佳性能。
理论原因:Encoder的双向注意力存在低秩问题,可能削弱模型的表达能力。
大模型LLMs的定义
定义:一般指1亿以上参数的模型,目前已有万亿参数以上的模型。
应用:针对语言的大模型。
参数规模
表示方法:175B、60B、540B等指参数的个数,B是Billion(十亿)的意思。
示例:175B是1750亿参数,ChatGPT大约的参数规模。
优点
预训练和微调:利用大量无标注数据进行预训练,再用少量有标注数据进行微调,减少数据标注成本和时间,提高泛化能力。
生成能力:利用生成式人工智能技术产生新颖和有价值的内容,如图像、文本、音乐等。
涌现能力:完成一些之前无法完成或很难完成的任务,如数学应用题、常识推理、符号操作等。
缺点
资源消耗:需要大量计算资源和存储资源,增加经济和环境负担。
数据质量与安全性:面临数据偏见、数据泄露、数据滥用等问题,可能导致不准确或不道德的输出。
可解释性、可靠性、可持续性:需要理解和控制模型的行为,保证模型的正确性和稳定性,平衡模型的效益和风险。
嘿,伙伴们,今天我们的AI探索之旅已经圆满结束。关于“《大模型(LLMs)基础面》电子书下载”的内容已经分享给大家了。感谢你们的陪伴,希望这次旅程让你对AI能够更了解、更喜欢。谨记,精准提问是解锁AI潜能的钥匙哦!如果有小伙伴想要了解学习更多的AI知识,请关注我们的官网“AI智研社”,保证让你收获满满呦!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 













还没有评论呢,快来抢沙发~